[논문 리뷰] Knowledge Diffusion for Distillation
DiffKD는 교사 특징으로 학습된 확산 모델을 통해 학생 특징을 노이즈 제거하여 교사-학생 간 격차를 해소하고, 비전 과제 전반에서 더 효과적인 지식 증류를 가능하게 한다.
The representation gap between teacher and student is an emerging topic in knowledge distillation (KD). To reduce the gap and improve the performance, current methods often resort to complicated training schemes, loss functions, and feature alignments, which are task-specific and feature-specific. In this paper, we state that the essence of these methods is to discard the noisy information and distill the valuable information in the feature, and propose a novel KD method dubbed DiffKD, to explicitly denoise and match features using diffusion models. Our approach is based on the observation that student features typically contain more noises than teacher features due to the smaller capacity of student model. To address this, we propose to denoise student features using a diffusion model trained by teacher features. This allows us to perform better distillation between the refined clean feature and teacher feature. Additionally, we introduce a light-weight diffusion model with a linear autoencoder to reduce the computation cost and an adaptive noise matching module to improve the denoising performance. Extensive experiments demonstrate that DiffKD is effective across various types of features and achieves state-of-the-art performance consistently on image classification, object detection, and semantic segmentation tasks. Code is available at https://github.com/hunto/DiffKD.
연구 동기 및 목표
- 용량 차이로 인한 KD에서 교사와 학생 간 표현 격차를 동기 부여하고 해결한다.
- 학생 특징에서 가치 있는 정보를 추출하기 위한 확산 기반 노이즈 제거 모듈을 제안한다.
- 계산 비용을 줄이기 위해 선형 오토인코더를 갖춘 경량 확산 모델을 도입한다.
- 초기화를 위한 적응적 노이즈 매칭 메커니즘을 추가하여 초기 확산 노이즈 수준을 정렬한다.
- 분류, 탐지 및 분할 작업 전반에서 방법의 효과를 입증한다.
제안 방법
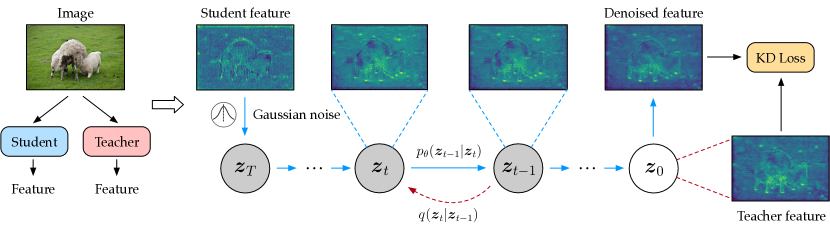
- 학생 특징을 교사 특징의 노이즈 버전으로 간주하고, 교사 특징에 확산 모델을 학습시켜 학생 특징을 노이즈 제거한다.
- 노이즈 제거된 학생 특징을 사용하여 표준 KD 손실로 교사 특징에 대해 증류를 수행한다.
- 특징 표현을 압축하기 위해 두 개의 병목 블록과 선형 오토인코더를 갖춘 경량 확산 아키텍처를 도입한다.
- 초기화를 위한 적절한 가우시안 노이즈를 추정하고 주입하기 위한 적응적 노이즈 매칭 모듈을 도입한다.
- 확산 및 증류 손실에 표준 거리(MSE, KL)를 사용하고, 고급 KD 손실(DIST, DKD)과 같은 옵션을 제공한다.
- Ltrain = Ltask + lambda1 Ldiff + lambda2 Lae + lambda3 Ldiffkd로 합성 손실로 전체 파이프라인을 최적화한다.
실험 결과
연구 질문
- RQ1확산 모델을 활용하여 KD를 위한 교사와 학생 특징을 노이즈 제거하고 정렬하는 방법은 무엇인가?
- RQ2학생 특징의 노이즈 제거가 작업 간 직접 특징 매칭보다 더 나은 지식 전달로 이어지는가?
- RQ3경량 확산 모델과 적응적 노이즈 매칭이 과도한 비용 없이 실질적인 이점을 달성할 수 있는가?
- RQ4DiffKD 접근법이 특징 유형(중간 특징, 로짓) 및 작업(분류, 탐지, 분할)에 걸쳐 일반적인가?
주요 결과
- DiffKD는 작업 전반에서 일관되게 최첨단 성능 향상을 제공하며, 예를 들어 ImageNet에서 MobileNetV1 학생과 ResNet-50 교사로 설정 시 top-1 정확도 73.62%를 달성한다.
- 더 강력한 교사 구성에서 DiffKD는 Swin-T/Swin-L 및 ResNet 계열과 같은 모델 쌍에서 기존 KD 방법을 능가한다.
- DiffKD는 다수의 기준선 대비 탐지 및 분할 벤치마크를 개선하고 간단한 KD 손실(MSE, KL)로도 효과적이다.
- 선형 오토인코더를 갖춘 경량 확산 모델은 distillation 성능을 유지하거나 향상시키면서 FLOPs를 크게 감소시킨다.
- 적응적 노이즈 매칭(ANM)은 초기 확산 노이즈를 학생 특징에 맞춰 정렬함으로써 노이즈 제거를 개선한다.
- 특징과 로짓 DiffKD를 결합하는 것이 최상의 성능을 낳는다는 애블레이션 결과가 나타나며(예: 한 설정에서 73.62%).

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.