[논문 리뷰] Language-based Action Concept Spaces Improve Video Self-Supervised Learning
본 논문은 이미지 CLIP를 비디오에 적용하기 위해 언어 기반의 행동 개념 공간과 자체 증류를 활용하여 제로샷, 선형 탐지, 전이 제로샷에서 동작 인식 벤치마크를 향상시킨다.
Recent contrastive language image pre-training has led to learning highly transferable and robust image representations. However, adapting these models to video domains with minimal supervision remains an open problem. We explore a simple step in that direction, using language tied self-supervised learning to adapt an image CLIP model to the video domain. A backbone modified for temporal modeling is trained under self-distillation settings with train objectives operating in an action concept space. Feature vectors of various action concepts extracted from a language encoder using relevant textual prompts construct this space. We introduce two train objectives, concept distillation and concept alignment, that retain generality of original representations while enforcing relations between actions and their attributes. Our approach improves zero-shot and linear probing performance on three action recognition benchmarks.
연구 동기 및 목표
- 언어 조건화된 행동 개념을 활용하여 비디오당 개별 라벨 없이도 견고한 비디오 표현을 학습하도록 동기를 부여한다.
- 언어 표현에서 파생된 카테고리 및 설명 개념 공간을 제안하여 SSL를 안내한다.
- CLIP와 같은 일반성을 보존하면서 행동 속성 관계를 포착하기 위해 두 가지 SSL 목표(개념 증류 및 개념 정렬)를 개발한다.
- 캡션이나 비디오당 라벨 없이 비디오에서 학습된 모델로 직접 제로샷 다운스트림 행동 인식을 가능하게 한다.
제안 방법
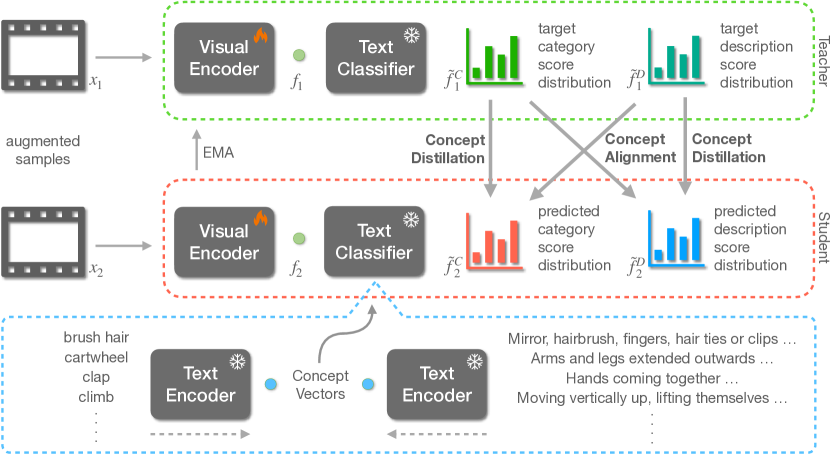
- 공간-시간 분해 주의(Factorized space-time attention)를 통한 시간적 모델링으로 보강된 CLIP 기반 시각 백본을 사용한다.
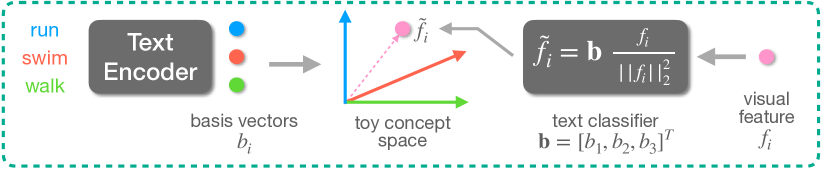
- CLIP 텍스트 인코더의 고정 임베딩으로부터 얻은 텍스트 분류기를 도입하여 시각 특징을 행동 개념 공간으로 투영한다.
- 언어로부터 두 개의 개념 공간을 구성한다: 카테고리 개념 공간(행동 라벨)와 설명 개념 공간(설명/속성).
- 각 각의 개념 공간에서 두 개의 증강 뷰를 일치시키는 개념 증류 손실을 정의한다. EMA 교사-학생 구성과 개념 점수에 대한 샤프한 소프트맥스 사용.
- 무균일 분포 사전분포를 추가하여 모 collapsed를 방지하고, 서로 다른 뷰 간에 카테고리 공간과 설명 공간을 연결하는 개념 정렬 손실을 추가한다.
- 레이블 생성 및 확장성을 탐색하기 위해 카테고리 개념 공간의 변형(LSS-A, LSS-B, LSS-C)을 지원한다.
실험 결과
연구 질문
- RQ1언어-derived action concepts가 비디오 SSL을 향상시켜 CLIP와 같은 표현이 비디오 작업으로 더 잘 전이되게 만들까?
- RQ2언어 정렬된 개념 공간에서의 개념 증류와 개념 정렬이 표준 벤치마크에서 제로샷 및 선형 탐색 성능을 더 낫게 만들까?
- RQ3카테고리/설명 개념 공간의 서로 다른 구성(LMM생성 라벨 포함)이 SSL 결과 및 확장성에 어떤 영향을 미칠까?
주요 결과
- HMDB-51 및 UCF-101에서 비디오당 라벨이나 캡션을 사용하지 않고도 기존의 SSL 방법과 비교해 선형 탐색에서 최첨단 성능을 달성한다.
- 제로샷으로 HMDB-51과 UCF-101에 대한 전이에서 베이스라인 CLIP 유사 모델을 능가하며 HMDB-51, UCF-101, Kinetics-400 전체에 걸친 강력한 트랜덕티브 제로샷 성능을 보인다.
- 두 가지 새로운 SSL 목표(개념 증류 및 개념 정렬)가 항상 베이스라인보다 향상되며, 균등 분포 사전과의 결합 시에도 개선이 지속된다.
- 언어 정렬된 행동 개념 공간이 이미지 CLIP 표현의 비디오 도메인으로의 전이성과 제로샷 능력을 유지하고 향상시킴을 입증한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.