[논문 리뷰] Language Instructed Reinforcement Learning for Human-AI Coordination
이 논문은 instructRL을 소개합니다, 자연어 지시문과 대형 언어 모델을 사용하여 다중 에이전트 RL을 정규화하고 AI 파트너가 인간과 협력하여 인간-aligned 균형으로 조정되도록 Say-Select와 Hanabi에서 시연됩니다.
One of the fundamental quests of AI is to produce agents that coordinate well with humans. This problem is challenging, especially in domains that lack high quality human behavioral data, because multi-agent reinforcement learning (RL) often converges to different equilibria from the ones that humans prefer. We propose a novel framework, instructRL, that enables humans to specify what kind of strategies they expect from their AI partners through natural language instructions. We use pretrained large language models to generate a prior policy conditioned on the human instruction and use the prior to regularize the RL objective. This leads to the RL agent converging to equilibria that are aligned with human preferences. We show that instructRL converges to human-like policies that satisfy the given instructions in a proof-of-concept environment as well as the challenging Hanabi benchmark. Finally, we show that knowing the language instruction significantly boosts human-AI coordination performance in human evaluations in Hanabi.
연구 동기 및 목표
- 인간과 조정하기 위한 균형 선택을 자연어 지시를 통해 안내함으로써 AI 파트너가 인간과 협력하도록 합니다.
- 사전 학습된 언어 모델을 활용해 인간 지시로 조건화된 우선 정책을 생성합니다.
- LLM 사전지식을 사용해 RL 학습을 Regularize하여 인간이 선호하는 균형으로 수렴하도록 합니다.
- 설계된 Say-Select 게임과 Hanabi 벤치마크에서 접근법을 시연합니다.
- 지시가 알려진 상황에서 언어 정보가 포함된 에이전트가 협력을 향상시키는지 인간 평가를 통해 보여줍니다.
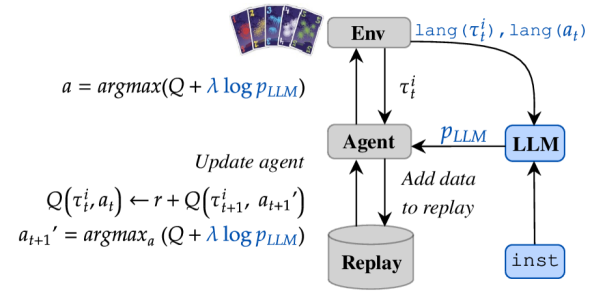
제안 방법
- LLM 기반의 우선 정책을 인간 지시와 현재 관찰 설명에 조건화하여 구성합니다.
- 행동과 관측을 언어 설명으로 매핑하여 LLM에 합리적 행동을 문의합니다.
- 로그-확률 증가 또는 KL 페널티를 통해 LLM 우선 정책으로 Q-러닝과 PPO를 Regularize합니다.
- instructRL이 지시를 만족하는 균형으로 유도할 수 있음을 보입니다.
- 두 가지 구체적 알고리즘 인스턴스화: instructQ (log pLLM)와 instructPPO (KL to pLLM)을 제공합니다.
- RL 중 LLM 가이던스를 통합하기 위해 병렬 학습을 적용하고 규칙화 가중치를 점진적으로 감소시킵니다.
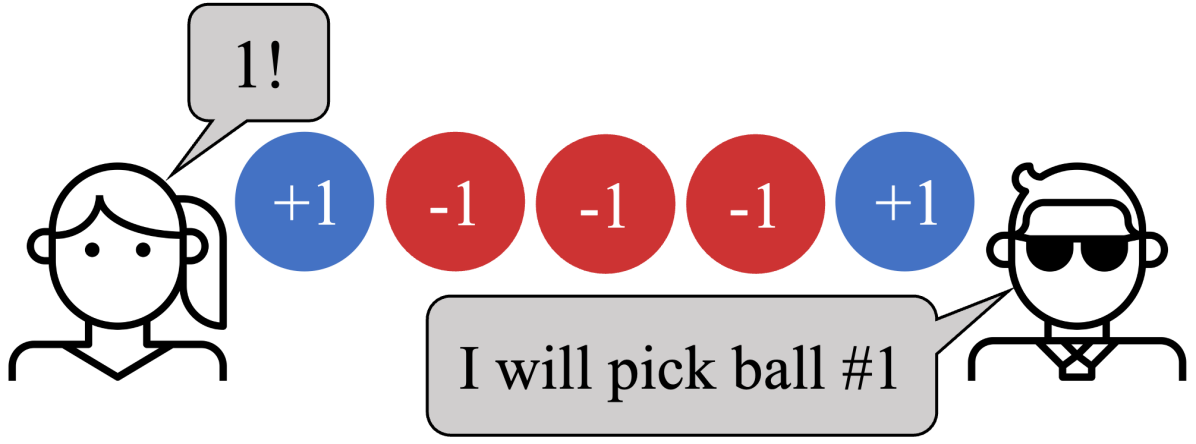
실험 결과
연구 질문
- RQ1자연어 지시가 협력적 과제에서 인간이 선호하는 균형으로 다중 에이전트 RL을 유도할 수 있는가?
- RQ2정책 학습을 LLM 사전지식으로 조건화하는 것이 Say-Select와 Hanabi에서 인간 친화적인 정책으로 연결되는가?
- RQ3언어 가이드 규제으로 학습된 에이전트가 표준 MARL 기준선에 비해 인간-AI 협력을 개선하는가?
- RQ4결과 정책이 다양한 환경에서 해석 가능하고 주어진 지시와 일치하는가?
주요 결과
| 방법 | 자기대전 | 내부-AXP |
|---|---|---|
| Q-learning | 23.96 ± 0.05 | 23.77 ± 0.07 |
| InstructQ (color) | 23.78 ± 0.05 | 23.77 ± 0.06 |
| InstructQ (rank) | 23.92 ± 0.02 | 23.78 ± 0.05 |
| PPO | 24.25 ± 0.01 | 24.25 ± 0.01 |
| InstructPPO (color) | 24.25 ± 0.03 | 24.23 ± 0.01 |
| InstructPPO (rank) | 24.10 ± 0.02 | 24.08 ± 0.02 |
- Say-Select에서 instructQ는 'I should select the same number as my partner.'라는 지시와 정렬된 정책을 산출합니다.
- Hanabi에서 instructQ와 instructPPO는 지시에 따라 색상 기반 정책과 등급 기반 정책처럼 의미적으로 다른 정책을 생성합니다.
- 두 방법 모두 자기 학습 및 내부-AXP 성능이 일반 벤치마크와 비슷하게 수렴해 견고한 수렴을 시사합니다.
- 인간 평가에 따르면 지시가 인간에게 알려진 경우 언어 정보 기반 에이전트와의 협력이 성능을 향상시킵니다.
- 이 방법은 대규모 인간 시연 데이터 없이도 에이전트에 언어 기반 지침을 주면 균형을 유도할 수 있음을 보여줍니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.