[논문 리뷰] Language Modeling Is Compression
본 논문은 손실 없는 압축의 관점에서 예측을 재구성하며, 대형 언어 모델이 텍스트, 이미지, 오디오 전반에서 맥락 내 압축에 탁월한 범용 예측기로 작동한다는 것을 보여주고, 스케일링, 토크나이제이션 및 압축기를 생성 모델로 활용하는 방법을 분석한다.
It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training increasingly large and powerful self-supervised (language) models. Since these large language models exhibit impressive predictive capabilities, they are well-positioned to be strong compressors. In this work, we advocate for viewing the prediction problem through the lens of compression and evaluate the compression capabilities of large (foundation) models. We show that large language models are powerful general-purpose predictors and that the compression viewpoint provides novel insights into scaling laws, tokenization, and in-context learning. For example, Chinchilla 70B, while trained primarily on text, compresses ImageNet patches to 43.4% and LibriSpeech samples to 16.4% of their raw size, beating domain-specific compressors like PNG (58.5%) or FLAC (30.3%), respectively. Finally, we show that the prediction-compression equivalence allows us to use any compressor (like gzip) to build a conditional generative model.
연구 동기 및 목표
- 손실less 압축과 정보 이론의 관점에서 기초 모델 연구를 자극한다.
- 대형 언어 모델의 멀티모달에서 오프라인(맥락 내) 압축 능력을 실험적으로 평가한다.
- 스케일링 법칙과 맥락 길이 및 모델 크기가 압축 성능에 미치는 영향을 분석한다.
- 압축기를 조건부 생성 모델로 재목적화하는 방법을 보여준다.
- 토크나이제이션과 데이터 모달리티가 압축 효율성에 미치는 역할을 분석한다.
제안 방법
- 트랜스포머 및 친칭실라(Chinchilla) 계열 모델의 확률적 예측으로 산술 부호화를 사용하여 무손실 압축기를 만든다.
- 텍스트(enwik9), 이미지(ImageNet 패치), 오디오 LibriSpeech에서 1 GB 샘플로 압축을 평가한다.
- 일반 용도 압축기(gzip, LZMA2)와 도메인 특화 압축기(PNG, FLAC)와 비교한다.
- 최적의 보정 압축률을 위한 모델 크기와 데이터 세트 크기 간의 트레이드오프를 조사한다.
- 사전 맥락에 조건을 두고 조건부 압축 길이에 따라 샘플링하는 방법을 시연한다.
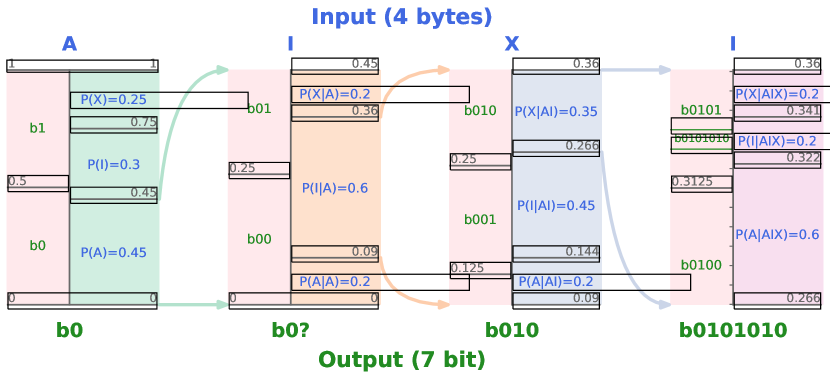
실험 결과
연구 질문
- RQ1텍스트를 주로 학습한 기초 모델이 여러 데이터 모달리티에 걸쳐 범용 압축기로 작용할 수 있는가?
- RQ2맥락 길이와 모델 크기가 맥락 내 압축 성능에 어떤 영향을 미치는가?
- RQ3토크나이제이션 스킴이 대형 모델과 짝지었을 때 압축을 개선하거나 저해하는가?
- RQ4압축기를 텍스트, 이미지, 오디오 데이터의 조건부 생성 모델로 사용할 수 있는가?
- RQ5데이터 크기 대비 압축 성능에 대한 스케일링 법칙의 시사점은 무엇인가?
주요 결과
| 청크 크기 | 압축기 | enwik9 원시 (%) | ImageNet 원시 (%) | LibriSpeech 원시 (%) | 무작위 원시 (%) | enwik9 보정 (%) | ImageNet 보정 (%) | LibriSpeech 보정 (%) | 무작위 보정 (%) |
|---|---|---|---|---|---|---|---|---|---|
| ∞ | gzip | 32.3 | 70.7 | 36.4 | 100.0 | 32.3 | 70.7 | 36.4 | 100.0 |
| ∞ | LZMA2 | 23.0 | 57.9 | 29.9 | 100.0 | 23.0 | 57.9 | 29.9 | 100.0 |
| ∞ | PNG | 42.9 | 58.5 | 32.2 | 100.0 | 42.9 | 58.5 | 32.2 | 100.0 |
| ∞ | FLAC | 89.5 | 61.9 | 30.9 | 107.8 | 89.5 | 61.9 | 30.9 | 107.8 |
| 2048 | gzip | 48.1 | 68.6 | 38.5 | 100.1 | 48.1 | 68.6 | 38.5 | 100.1 |
| 2048 | LZMA2 | 50.0 | 62.4 | 38.2 | 100.0 | 50.0 | 62.4 | 38.2 | 100.0 |
| 2048 | PNG | 80.6 | 61.7 | 37.6 | 103.2 | 80.6 | 61.7 | 37.6 | 103.2 |
| 2048 | FLAC | 88.9 | 60.9 | 30.3 | 107.2 | 88.9 | 60.9 | 30.3 | 107.2 |
| 200K | Transformer | 30.9 | 194.0 | 146.6 | 195.5 | 30.9 | 194.0 | 146.6 | 195.5 |
| 800K | Transformer | 21.9 | 185.3 | 131.3 | 200.3 | 21.9 | 185.3 | 131.3 | 200.3 |
| 3.2M | Transformer | 17.7 | 216.5 | 228.9 | 224.7 | 17.7 | 216.5 | 228.9 | 224.7 |
| 1B | Chinchilla | 211.3 | 262.2 | 224.9 | 308.8 | 1410.2 | 1454.7 | 1423.6 | 1501.6 |
| 7B | Chinchilla | 1410.2 | 1454.7 | 1423.6 | 1501.6 | 1410.2 | 1454.7 | 1423.6 | 1501.6 |
| 70B | Chinchilla | 14008.3 | 14048.0 | 14021.0 | 14100.8 | 14008.3 | 14048.0 | 14021.0 | 14100.8 |
- Chinchilla 70B가 ImageNet 패치에서 43.4%, LibriSpeech에서 16.4%의 압축을 달성하여 각 도메인에서 PNG 및 FLAC를 능가한다.
- 대형 기초 모델은 텍스트, 이미지, 오디오 전반에서 경쟁력 있는 오프라인 압축을 가능하게 하는 강력한 맥락 학습을 제공한다.
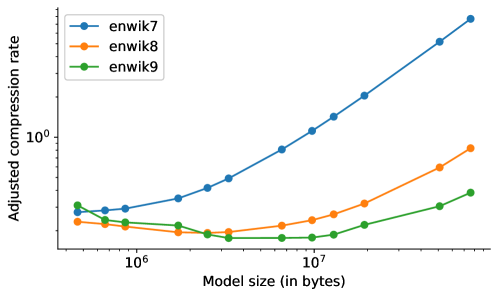
- 압축 성능은 스케일링 추세를 따르지만 데이터 세트 크기로 한계가 있다; 일정 지점을 넘으면 모델 규모를 반영한 보정 압축률이 증가한다.
- 작은 모델의 경우 일반적으로 토크나이제이션이 원시 압축률을 향상시키지 않으며, 더 큰 어휘는 더 큰 모델에서 성능을 해칠 수 있다.
- 사전 맥락으로 조건을 두고 조건부 압축 길이 차이에 따라 샘플링함으로써 압축기를 생성 모델로 사용하는 것이 가능하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.