[논문 리뷰] Large Language Models Are Semi-Parametric Reinforcement Learning Agents
이 논문은 LLM 기반 에이전트의 지속적인 외부 경험 메모리를 강화 학습(Reinforcement Learning)으로 업데이트하여, LLM을 미세 조정하지 않고도 준-매개변수적 RL을 가능하게 하는 Rememberer를 소개한다. 이는 WebShop 및 WikiHow 벤치마크에서 최첨단 성과를 달성한다.
Inspired by the insights in cognitive science with respect to human memory and reasoning mechanism, a novel evolvable LLM-based (Large Language Model) agent framework is proposed as REMEMBERER. By equipping the LLM with a long-term experience memory, REMEMBERER is capable of exploiting the experiences from the past episodes even for different task goals, which excels an LLM-based agent with fixed exemplars or equipped with a transient working memory. We further introduce Reinforcement Learning with Experience Memory (RLEM) to update the memory. Thus, the whole system can learn from the experiences of both success and failure, and evolve its capability without fine-tuning the parameters of the LLM. In this way, the proposed REMEMBERER constitutes a semi-parametric RL agent. Extensive experiments are conducted on two RL task sets to evaluate the proposed framework. The average results with different initialization and training sets exceed the prior SOTA by 4% and 2% for the success rate on two task sets and demonstrate the superiority and robustness of REMEMBERER.
연구 동기 및 목표
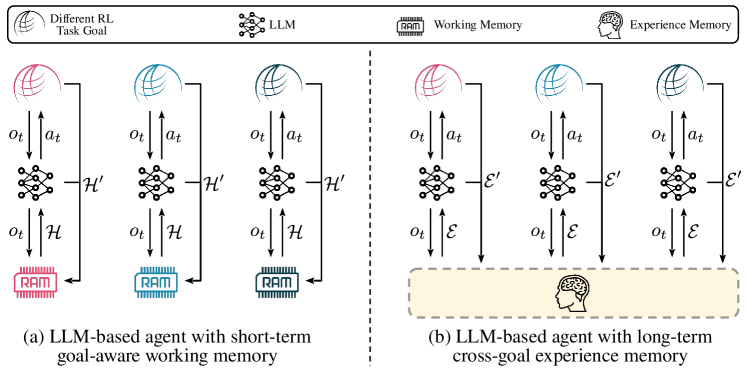
- 고정된 예시를 넘는 과거 에피소드로부터 학습할 수 있도록 LLM 기반 에이전트를 장기 경험 메모리의 활용으로 동기화한다.
- LLM 매개변수를 업데이트하지 않고 외부 메모리를 업데이트하는 Experience Memory를 이용한 Reinforcement Learning(RLEM)을 제안한다.
- Rememberer를 설계하여 경험을 선별적으로 검색하고 맥락 내 학습을 위한 동적 exemplars를 제공한다.
- WebShop 및 WikiHow 벤치마크 RL 작업 세트에서 강인성과 성능 향상을 시연한다.
제안 방법
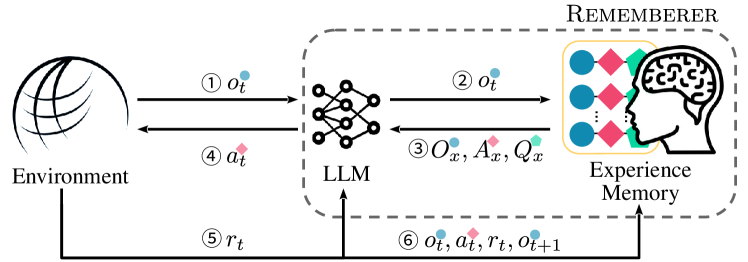
- LLM 에이전트를 위한 외부의 지속적인 경험 메모리를 도입하고 환경과의 상호작용을 정의한다.
- 안정성을 위한 Bellman 유사 규칙과 선택적 n-스텝 부트스트래핑을 사용하여 메모리의 Q-value 업데이트를 정의한다.
- 메모리에서 유사도 기반 검색을 사용하여 LLM을 few-shot 프롬프트로 안내하는 exemplars를 형성한다.
- 기억된 경험을 활용하기 위해 권장 행동과 비권장 행동을 모두 포함하는 action-advice 프롬프트 형식을 제시한다.
- LLM 매개변수 미세조정 없이 off-policy 학습을 통해 메모리를 업데이트한다.
- 최첨단 기준선과의 비교를 통해 WebShop 및 WikiHow에서 Rememberer를 평가한다.
실험 결과
연구 질문
- RQ1LLM 기반 에이전트가 모델 매개변수를 미세조정하지 않고도 장기 경험 메모리로부터 학습할 수 있는가?
- RQ2외부 메모리를 갖춘 준-매개적 RL 프레임워크가 고정된 exemplars나 순수 RL/IL 기반대보다 순차적 의사결정 과제에서 성능을 향상시키는가?
- RQ3다양한 작업에서 의사결정 품질을 최대화하도록 경험을 LLM에 어떻게 검색하고 제시해야 하는가?
- RQ4메모리-엑셀럼 프롬프트에서 부트스트래핑과 비권장 행동의 포함이 의사결정 품질에 미치는 영향은 무엇인가?
- RQ5다양한 초기 경험과 학습 세트에 대해 Rememberer의 강인성은 어느 정도인가?
주요 결과
- Rememberer는 WebShop에서 Avg Score 0.68 및 Success Rate 0.39로 이전 SOTA를 상회하며, ReAct의 0.66/0.36 및 LLM-only의 0.55/0.29를 상회한다.
- WikiHow에서 Rememberer는 Avg Reward 2.63 및 Success Rate 0.93을 달성하여 LLM-only 2.58/0.90 및 Mobile-Env 2.50/0.89를 능가한다.
- Rememberer는 전통적인 RL/IL 방식에 비해 주석 샘플이 훨씬 적게 필요하며(예: 10개 작업당 74단계) 강한 성능에 도달한다.
- 삭제 실험에서 부트스트래핑이 보상 추정 정확도와 최종 성능을 향상시키는 반면 관찰 유사성 제거는 작업 유사성 제거보다 결과를 더 악화시킨다.
- 비권장 행동의 포함과 두 구성요소 유사도(작업 및 관찰)가 성능에 큰 영향을 미치며, 특히 관찰 유사도가 매우 중요하다.
- 실험은 Rememberer가 서로 다른 초기 엑샘플과 학습 세트에 대해 견고하며, 설정 간 고정 엑샘플에 비해 지속적으로 향상을 유지함을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.