[논문 리뷰] Large language models for aspect-based sentiment analysis
미세조정된 GPT-3.5가 SemEval-2014 ABSA 공동 태스크에서 최첨단 83.8 F1을 달성했으며, GPT-4 및 InstructABSA에 비해 비용-성능 프로파일이 우수합니다; 제로/적은 샷 프롬프트는 일부 설정에 도움을 주지만, 미세조정이 프롬프트의 필요성을 크게 줄이는 경향이 있습니다.
Large language models (LLMs) offer unprecedented text completion capabilities. As general models, they can fulfill a wide range of roles, including those of more specialized models. We assess the performance of GPT-4 and GPT-3.5 in zero shot, few shot and fine-tuned settings on the aspect-based sentiment analysis (ABSA) task. Fine-tuned GPT-3.5 achieves a state-of-the-art F1 score of 83.8 on the joint aspect term extraction and polarity classification task of the SemEval-2014 Task 4, improving upon InstructABSA [@scaria_instructabsa_2023] by 5.7%. However, this comes at the price of 1000 times more model parameters and thus increased inference cost. We discuss the the cost-performance trade-offs of different models, and analyze the typical errors that they make. Our results also indicate that detailed prompts improve performance in zero-shot and few-shot settings but are not necessary for fine-tuned models. This evidence is relevant for practioners that are faced with the choice of prompt engineering versus fine-tuning when using LLMs for ABSA.
연구 동기 및 목표
- GPT-4와 GPT-3.5의 제로샷, 소샷, 및 미세조정 설정에서의 ABSA 태스크의 공동 측면 용어 추출 및 극성 분류 성능 평가.
제안 방법
- 주요 지표로 F1을 사용하여 노트북 및 레스토랑 리뷰에 대한 SemEval-2014 ABSA 벤치마크를 평가한다.
- 다양한 프롬프트 변형, 인-컨텍스트 예제 개수, OpenAI API를 통한 GPT-3.5의 미세조정을 테스트한다.
- 모델 출력을 표준화하기 위해 JSON 스키마와 OpenAI 함수 호출을 사용한다.
- 강력한 기준선으로 InstructABSA와 비교한다.
- 모델 간 오차 유형 및 비용-성능 트레이드를 분석한다.
- 미세조정 모델에 대해 상세 프롬프트가 필요한지 여부를 검토한다.

실험 결과
연구 질문
- RQ1GPT-4, GPT-3.5(제로/적은 샷), 그리고 미세조정된 GPT-3.5가 SemEval-2014에서 ABSA의 공동 ATE 및 극성 태스크에서 어떻게 수행되는가?
- RQ2프롬프트 설계, 인-컨텍스트 예제, 그리고 미세조정이 ABSA 성능 및 비용에 미치는 영향은?
- RQ3미세조정된 GPT-3.5 모델이 SemEval-2014 ABSA 공동 태스크에서 이전의 최첨단(InstructABSA)을 능가하는가?
- RQ4LLM이 ABSA에서 보이는 오류 패턴은 무엇이며, 미세조정이 거짓 양성/거짓 음성에 어떻게 영향을 미치는가?
- RQ5LLM을 사용한 ABSA에서 프롬프트 사용과 미세조정 간의 비용-성능(비용 대 F1) 트레이드오프는 무엇인가?
주요 결과
- 미세조정된 GPT-3.5가 SemEval-2014 공동 ABSA 태스크에서 83.8 F1을 달성했고, InstructABSA보다 5.7% 포인트 앞섭니다.
- GPT-3.5와 GPT-4는 서로 다른 비용-성능 프로파일을 가지며, 미세조정된 GPT-3.5가 더 낮은 비용으로 강한 성능을 제공합니다.
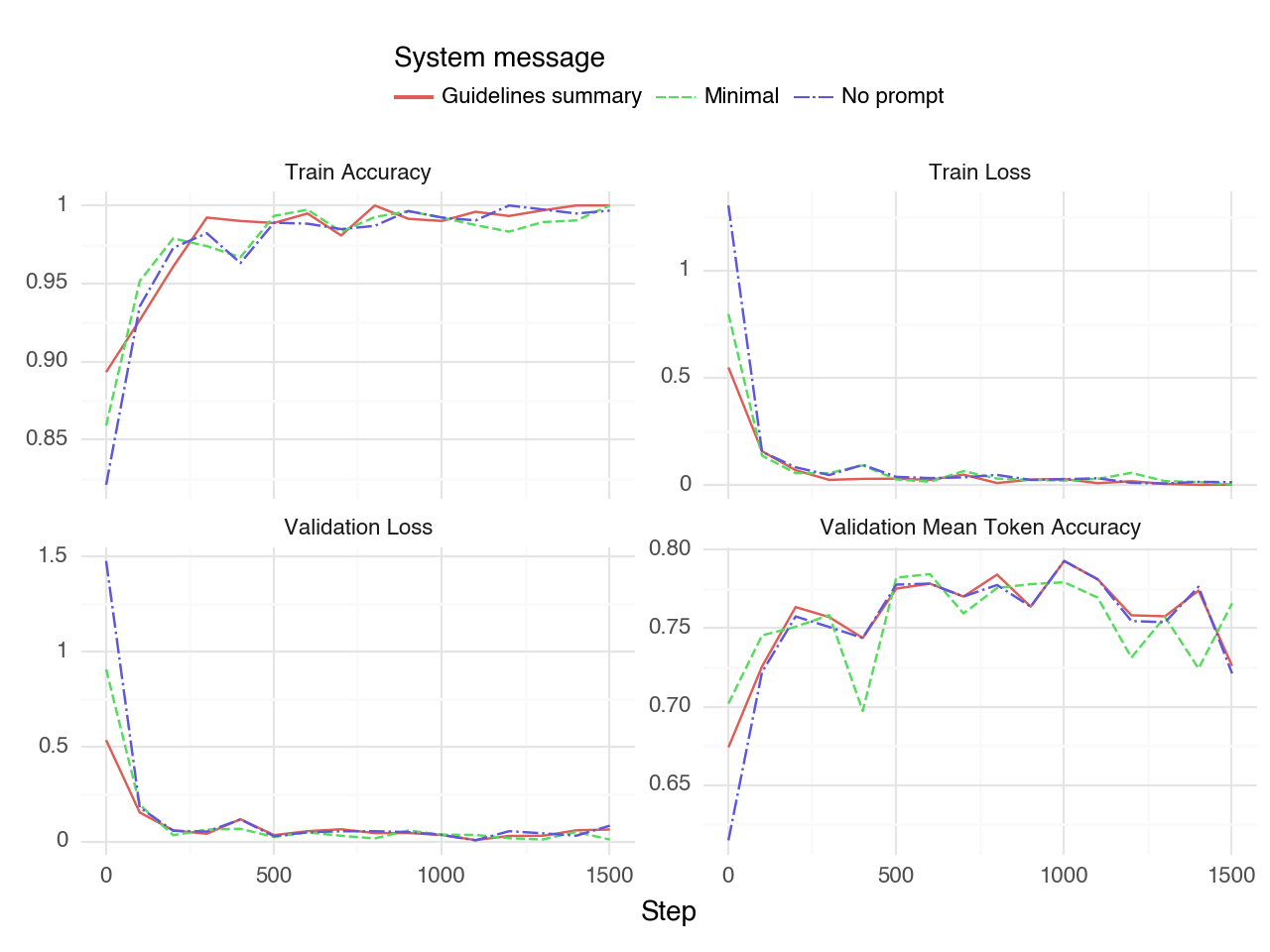
- 자세한 프롬프트는 일부 설정에서 제로샷 및 소샷 결과를 개선하지만, 미세조정된 모델에는 필요하지 않습니다.
- 제로샷 GPT-4는 GPT-3.5보다 성능이 떨어질 수 있으며, 인-컨텍스트 예제가 GPT-4를 경쟁력 있는 수준으로 끌어올립니다.
- 오류 분석에 따르면 주요 이득은 비-골드 용어를 잘못 예측하는 거짓 양성을 줄이고, 용어가 정확히 추출될 때 극성 분류를 개선하는 데서 나옵니다.
- 미세조정된 GPT-3.5는 특정 하위 유형에서 거짓 양성을 최대 약 88%까지 감소시키고, 측면 용어 추출에서 더 높은 정확도를 달성합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.