[논문 리뷰] Large Language Models for Compiler Optimization
LLVM 어셈블리 최적화를 위해 처음부터 학습된 7B 파라미터 LLM은 코드 크기를 최소화하기 위해 컴파일러 패스를 선택하는 법을 학습하며, 추론 시 컴파일러를 실행하지 않고도 컴파일러 기준 대비 명령 수를 3.0% 감소시키고 강한 코드 추론 능력을 보임(91% 컴파일 가능, 컴파일러 출력과의 70% 정확 일치).
We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.
연구 동기 및 목표
- 생성 및 번역을 넘어 코드 최적화를 위한 LLM 연구를 촉진한다.
- LLM이 컴파일러 패스를 선택하고 적용하여 코드 크기를 최소화하는 방법을 학습할 수 있는지 조사한다.
- 최적화 성능과 이해도를 향상시키는 보조 학습 작업을 시연한다.
- 다양한 보이지 않는 IR 벤치마크에 걸친 강건성을 평가한다.
제안 방법
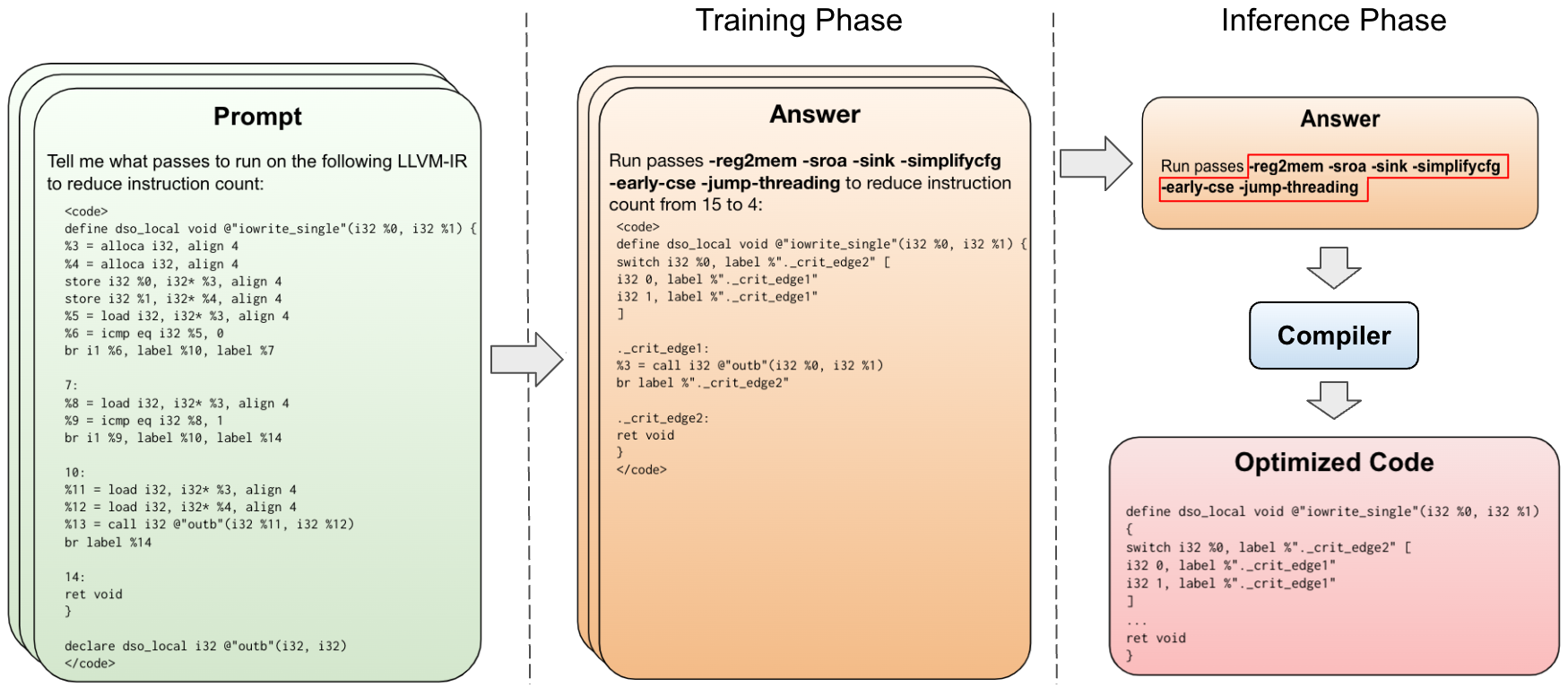
- 수백만 개의 LLVM-IR 예제와 최고의 컴파일 옵션 및 결과 최적화된 IR를 짝지어 사용해 처음부터 7B 파라미터 트랜스포머를 학습시킨다( Llama 2 베이스 ).
- 입력: 최적화되지 않은 LLVM-IR; 출력: opt를 통해 적용할 최적화 패스의 시퀀스(pass list), 122개의 패스와 메타 플래그를 고려한다.
- 보조 학습 작업: 최적화 전후의 명령 수를 예측하고 최적화된 IR을 생성하여 안전성과 이해를 심화한다.
- 토크나이제이션 및 학습을 위한 입력 길이를 줄이고 포맷팅을 표준화하기 위해 LLVM-IR을 정규화한다.
- 함수별 금표준(pass lists)을 얻기 위해 자동 튜닝을 사용한 뒤 이를 학습 데이터 전체에 감독 신호로 전파한다.
- 100만 개의 IR 함수(훈련 분할)로 학습하며 총 약 373M 토큰; 평가 지표로 코드 크기를 최적화한다.
- 다수의 벤치마크 세트(AI-SOCO, ExeBench, POJ-104, Transcoder, CSmith, YARPGen)에 걸쳐 100k개의 미지의 IR 함수로 평가한다.
실험 결과
연구 질문
- RQ1LLM이 보이지 않는 코드의 명령 수를 최소화하는 효과적인 LLVM 최적화 패스 목록을 예측하는 법을 학습할 수 있는가?
- RQ2보조 작업(명령 수 예측 및 최적화된 IR 생성)이 모델의 최적화 성능을 향상시키는가?
- RQ3다양한 벤치마크에서 모델이 생성한 코드와 패스 목록의 특성 및 한계는 무엇인가?
주요 결과
- 모델은 추론 시 컴파일러 호출 없이 모델이 전적으로 생성한 패스 목록을 사용하여 컴파일러 기준 대비 명령 수를 3.0% 개선했다(-Oz).
- 모델이 생성한 최적화 IR의 91%가 컴파일 가능하고 컴파일러가 생성한 최적화 IR과의 70% 정확 일치를 보인다.
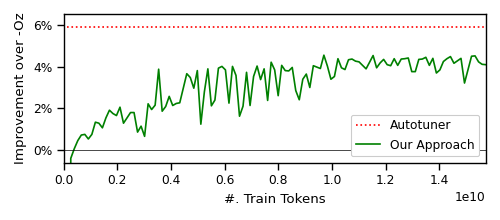
- BLEU 점수 0.952 및 피크 시점의 최적화 코드에서 4.4% 명령 감소를 기록하고, 자동튜너는 5.6%를 달성하지만 대규모 컴파일 작업이 필요하다.
- 미지의 벤치마크에서 모델은 전체 개선에서 -Oz, AutoPhase, 및 Coreset-NVP를 능가하고 -Oz 백업은 회귀를 방지하면서 이득을 유지한다.
- 모델은 더 길거나 큰 입력으로 일반화하며(더 큰 프로그램일수록 더 큰 개선을 얻는 경향), 학습 데이터에 없었던 많은 새로운 패스 목록을 생성할 수 있다(100k 테스트 프로그램에서 105개 목록).
- 변형 분석은 학습 데이터 규모와 또한 최적화된 코드를 생성하도록 모델을 학습시키는 것이(패스 목록뿐 아니라) 하위 성능에 상당한 영향을 준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.