[논문 리뷰] Large Language Models in the Clinic: A Comprehensive Benchmark
본 논문은 BenchHealth를 소개한다, 의료 판단, 생성, 이해 전반에 걸쳐 16개의 LLM을 평가하는 헬스케어 벤치마크로, 다섯 가지 신뢰성 지표와 인간 평가를 포함한다.
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and clinical tasks that are complex but common in real-world practice, e.g., open-ended decision-making, long document processing, and emerging drug analysis. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs. The benchmark data is available at https://github.com/AI-in-Health/ClinicBench.
연구 동기 및 목표
- 클리닉 환경에서 LLM의 신뢰할 수 있는 배치를 촉진하기 위해 닫힌형 QA에서 벗어나 개방형 의료 과제로의 적용을 촉진한다.
- 추론, 생성, 이해에 걸친 다양한 의료 과제에서 공개 데이터셋을 사용해 LLM을 벤치마킹한다.
- 전통적인 매칭 지표와 함께 추가적인 신뢰성 지향 지표(faithfulness, comprehensiveness, robustness, generalizability)를 도입한다.
- 일반 LLM과 의료용 LLM의 비교 분석 및 오픈 소스 모델과 상용 모델의 비교를 제공한다.
- 임상적 유용성과 한계를 평가하기 위해 의료 전문가를 참여시켜 인간 평가를 수행한다.
제안 방법
- BenchHealth를 일곱 가지 과제와 세 가지 시나리오에 걸친 일곱 가지 데이터셋으로 구성한다.
- 제로샷 및 few-shot(1/3/5-shot) 설정에서 16개 LLM(일반 9개, 의료 7개)을 평가한다.
- 정확도 이외에 다섯 가지 지표를 사용한다: faithfulness, comprehensiveness, robustness, generalizability, 그리고 전통적인 매칭 점수.
- 최신 기술의 프롬프트를 기반으로 과제별로 맞춤 프롬트를 도입하여 과제 이해를 최적화한다.
- 환자 대화에서 공개 모델과 선도적 상용 LLM을 비교하는 의료 전문가를 대상으로 인간 평가를 수행한다.
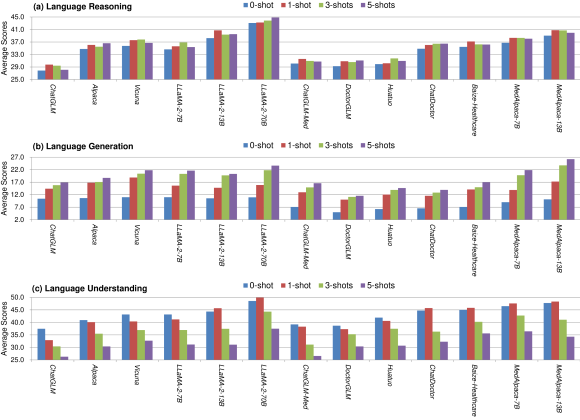
실험 결과
연구 질문
- RQ1개방형 임상 과제가 닫힌형 QA에 비해 LLM 성능에서 어떻게 차이가 나타나는가?
- RQ2상용 LLM이 헬스케어 과제 전반에서 오픈소스 모델을 능가하는가, 그리고 의료 미세조정 LLM은 일반 LLM과 어떻게 비교되는가?
- RQ3모델 크기, 미세 조정 데이터, 적은-shot 학습이 성능, 신뢰성, 임상적 유용성에 어떻게 영향을 미치는가?
- RQ4임상 맥락에서 어떤 지표가 faithfulness, comprehensiveness, robustness, generalizability를 가장 잘 포착하는가?
- RQ5인간 평가에 따른 일반 LLM과 의료 LLM의 상대적 임상적 유용성은 무엇인가?
주요 결과
- 상용 LLM들(예: GPT-4)은 작업과 데이터세트 전반에서 오픈 소스 모델보다 우수하다.
- 모든 LLM은 닫힌형 QA에서 우수하지만 개방형 임상 결정과 일부 생성/이해 과제에서 어려움을 겪는다.
- 일반 LLM을 의료 데이터로 미세조정하면 추론/이해가 향상되지만 요약 능력이 감소할 수 있다.
- 매개변수 수가 크게 증가하면 일반적으로 모든 과제에서 성능이 향상되며, few-shot는 추론과 생성은 향상시키지만 이해에는 해를 끼칠 수 있다.
- 의료 LLM은 더 충실한 답변과 더 나은 일반화 가능성을 제공하는 반면, 일반 LLM은 더 넓은 포괄성 및 견고성을 제공한다.
- 인간 평가에 따르면 의료 LLM은 충실성 및 일반화 가능성에서 일반 LLM을 능가하지만 포괄성 및 견고성은 일반 LLM에 비해 약하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.