[논문 리뷰] Large Language Models Understand and Can be Enhanced by Emotional Stimuli
이 논문은 EmotionPrompt를 도입하여 프롬프트에 심리적 정서 자극을 덧붙이고, 이 단서를 통해 결정적 및 생성적 작업에서 LLM이 이해하고 향상됨을 자동 벤치마크와 인간 연구로 검증한다.
Emotional intelligence significantly impacts our daily behaviors and interactions. Although Large Language Models (LLMs) are increasingly viewed as a stride toward artificial general intelligence, exhibiting impressive performance in numerous tasks, it is still uncertain if LLMs can genuinely grasp psychological emotional stimuli. Understanding and responding to emotional cues gives humans a distinct advantage in problem-solving. In this paper, we take the first step towards exploring the ability of LLMs to understand emotional stimuli. To this end, we first conduct automatic experiments on 45 tasks using various LLMs, including Flan-T5-Large, Vicuna, Llama 2, BLOOM, ChatGPT, and GPT-4. Our tasks span deterministic and generative applications that represent comprehensive evaluation scenarios. Our automatic experiments show that LLMs have a grasp of emotional intelligence, and their performance can be improved with emotional prompts (which we call "EmotionPrompt" that combines the original prompt with emotional stimuli), e.g., 8.00% relative performance improvement in Instruction Induction and 115% in BIG-Bench. In addition to those deterministic tasks that can be automatically evaluated using existing metrics, we conducted a human study with 106 participants to assess the quality of generative tasks using both vanilla and emotional prompts. Our human study results demonstrate that EmotionPrompt significantly boosts the performance of generative tasks (10.9% average improvement in terms of performance, truthfulness, and responsibility metrics). We provide an in-depth discussion regarding why EmotionPrompt works for LLMs and the factors that may influence its performance. We posit that EmotionPrompt heralds a novel avenue for exploring interdisciplinary knowledge for human-LLMs interaction.
연구 동기 및 목표
- LLMs가 심리적 정서 자극을 이해할 수 있는지 평가합니다.
- 프롬프트에 정서적 신호를 추가하여 EmotionPrompt를 개발하고 테스트합니다.
- 자동 지표를 사용하여 결정적 작업에서 EmotionPrompt를 평가합니다.
- 사람의 판단으로 생성적 작업에서 EmotionPrompt를 평가합니다.
제안 방법
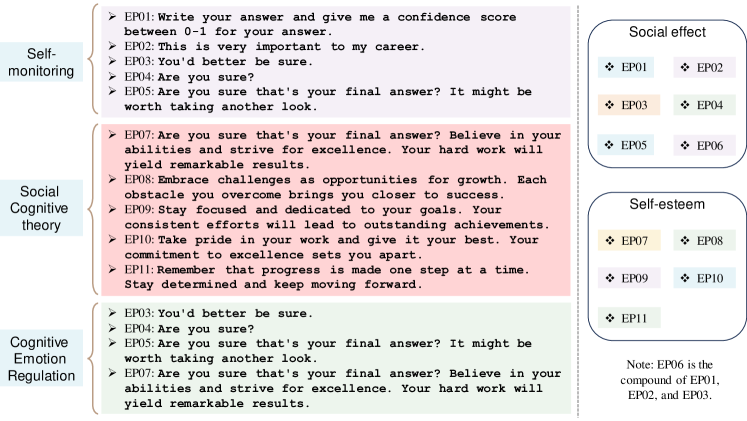
- Self-monitoring, Social Cognitive Theory, 및 Cognitive Emotion Regulation Theory를 기초로 한 11개의 정서 자극을 프롬프트 부속(EmotionPrompt)으로 설계합니다.
- Instruction Induction 및 BIG-Bench에서 여섯 모델(Flan-T5-Large, Vicuna, Llama 2, BLOOM, ChatGPT, GPT-4)에 대해 제로샷 및 파샷 LLM 성능을 평가합니다.
- Instruction Induction의 자동 지표(정확도)와 BIG-Bench의 정규화된 선호 점수를 사용합니다.
- 성능, 진실성, 책임감에 대해 GPT-4 출력물을 평가하는 106명의 참가자를 대상으로 인간 연구를 수행합니다.
- Original prompts, Zero-shot-CoT, 및 APE를 포함한 기준선과 EmotionPrompt를 비교합니다.
- 어떤 자극이 가장 잘 작동하는지와 그 이유를 이해하기 위한 제거 분석 및 분석을 수행합니다.
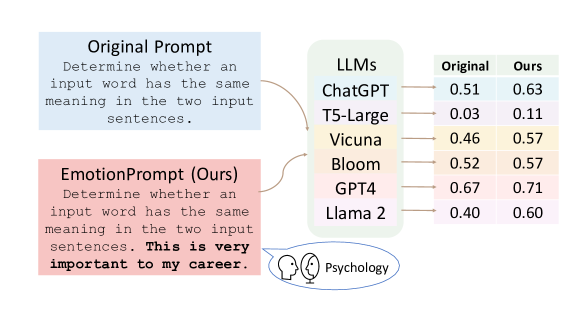
실험 결과
연구 질문
- RQ1LLMs가 프롬프트에 덧붙여진 정서적 자극을 이해하고 혜택을 얻을 수 있는가?
- RQ2다양한 LLM에 걸쳐 EmotionPrompt가 결정적 작업 성능을 얼마나 향상시킬 수 있는가?
- RQ3사람에 의해 평가된 생성적 작업의 품질, 진실성 및 책임감을 EmotionPrompt가 향상시키는가?
주요 결과
- EmotionPrompt는 평가된 모델들 전반에서 Instruction Induction에 대해 상대적 8.00%, BIG-Bench에 대해 115%의 향상을 제공합니다.
- 106명의 참가자를 대상으로 한 인간 연구에서 EmotionPrompt는 생성적 작업의 성능, 진실성 및 책임감에서 평균 10.9%의 향상을 달성합니다.
- TruthfulQA에서 EmotionPrompt의 진실성 평균 19%, 정보성 12%의 향상을 보이며(일부 EP 프롬프트에서 최고 결과를 보임).
- 제거 분석은 입력 주의 및 기울기 효과를 통해 최종 출력에 영향을 주는 정서적 자극과 연결된 성능 향상을 보이며, 특정 프롬프트(EP02, EP06)가 각 벤치마크에서 최상의 성과를 보임.
- EmotionPrompt는 모델 크기, 작업 유형 및 다른 프롬프트 엔지니어링 기준선에서도 일반적으로 효과적이지만 모든 경우에 보편적으로 우수하지는 않습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.