[논문 리뷰] Large scale paired antibody language models
IgBert 및 IgT5는 페어드 및 언페어드 항체 서열로 학습된 대형 항체 특화 언어 모델로 서열 회복 및 다운스트림 예측 작업을 개선하고, 주요 벤치마크에서 기존 단백질 및 항체 LMs를 능가하며, 항체 엔지니어링 애플리케이션에 공개적으로 이용 가능합니다.
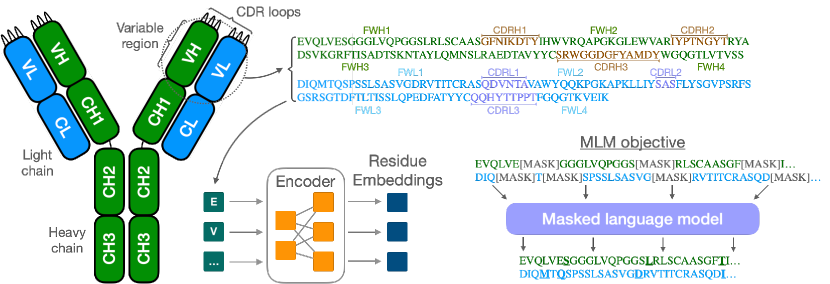
Antibodies are proteins produced by the immune system that can identify and neutralise a wide variety of antigens with high specificity and affinity, and constitute the most successful class of biotherapeutics. With the advent of next-generation sequencing, billions of antibody sequences have been collected in recent years, though their application in the design of better therapeutics has been constrained by the sheer volume and complexity of the data. To address this challenge, we present IgBert and IgT5, the best performing antibody-specific language models developed to date which can consistently handle both paired and unpaired variable region sequences as input. These models are trained comprehensively using the more than two billion unpaired sequences and two million paired sequences of light and heavy chains present in the Observed Antibody Space dataset. We show that our models outperform existing antibody and protein language models on a diverse range of design and regression tasks relevant to antibody engineering. This advancement marks a significant leap forward in leveraging machine learning, large scale data sets and high-performance computing for enhancing antibody design for therapeutic development.
연구 동기 및 목표
- 대량의 항체 서열 데이터 활용을 촉진하여 항체의 설계 및 엔지니어링을 향상시키기.
- 페어드/언페어드 가변 영역을 입력으로 모두 처리할 수 있는 항체 특화 언어 모델을 개발한다.
- 광범위한 언페어드 데이터로 사전학습하고 페어드 무거운/경쇄 데이터를 미세조정하여 교차 체인 특성을 학습한다.
- 시퀀스 회복, 결합 친화성, 발현 예측에 대해 기존 항체 및 단백질 LMs와 비교하여 모델을 평가한다.
제안 방법
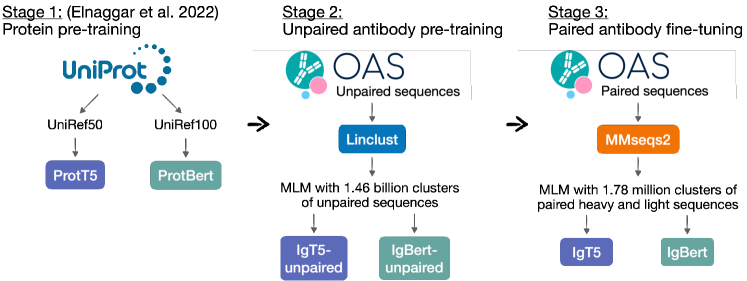
- OAS의 두십억 개가 넘는 언페어드 항체 서열에서 ProtBert/ProtT5 가중치를 시작점으로 BERT 스타일 및 T5 스타일 모델을 사전 학습한다.
- OAS의 고유한 페어드 무거운/경쇄 서열 2,038,528건에서 언페어드 모델을 미세조정하여 IgBert와 IgT5를 페어드로 형성한다.
- BERT와 T5에 대해 MLM 목표를 사용하되, BERT는 15% 마스킹, T5는 스팬 기반 마스킹을 적용한다.
- 가중 사슬과 경쇄를 구분 토큰으로 연결하여 교차 체인 특징을 학습하는 입력을 구성한다.
- 언페어드와 페어드 데이터의 혼합 배치로 미세조정하여 언페어드 사전학습의 망각을 완화한다.
- 테스트 세트에서 시퀀스 회복을 평가하고, 임베딩에 선형 모델을 적용한 다운스트림 결합/발현 예측, 그리고 perplexity/의사 perplexity 측정을 수행한다.
실험 결과
연구 질문
- RQ1대규모 페어드/언페어드 데이터로 학습된 항체 특화 언어 모델이 항체 설계 작업에서 일반 단백질 LMs보다 더 나은가?
- RQ2무거운/경쇄의 페어드 학습이 결합 친화성 및 발현과 같은 다운스트림 예측을 향상시키는 교차 체인 특징을 도출할 수 있는가?
- RQ3IgBert와 IgT5가 기존 AbLang, AntiBERTy, 및 ProtBert/ProtT5와 시퀀스 회복 및 perplexity에서 어떻게 비교되는가?
- RQ4데이터 품질과 페어링이 항체 엔지니어링 작업에서 모델 성능에 미치는 영향은 무엇인가?
- RQ5이 모델들이 인 실리코 친화성 성숙 및 기타 치료제 설계 워크플로우를 가능하게 할 수 있는가?
주요 결과
- IgBert 및 IgT5는 항체 영역 전반의 시퀀스 회복에서 기존 항체 및 단백질 언어 모델보다 우수하며, 특히 하이퍼가변 CDR에서 더 뛰어나다.
- 페어드 모델(IgBert, IgT5)은 선형 다운스트림 모델에서 결합 친화성 예측에 가장 높은 성능을 보이며, 교차 체인 학습의 가치를 강조한다.
- 일반 단백질 모델(ProtBert, ProtT5)이 발현 예측에서 항체 특화 모델보다 때때로 더 나은 성능을 보이며, 광범위한 진화 정보가 특정 작업에 도움이 됨을 시사한다.
- Perplexity/유사-Perplexity 측정은 항체 특화 페어드 모델이 일반 단백질 모델보다 더 낮은 값을 달성해 페어드 데이터의 시퀀스 '자연스러움'이 더 크다는 것을 보여준다.
- 페어드 데이터로의 미세조정은 언페어드 데이터만의 사전학습에 비해 상당한 이점을 제공하며, 토체인(무거운/경쇄) 페어링의 중요성을 강조한다.
- 저자들은 IgBert와 IgT5를 공개적으로 제공하여 항체 엔지니어링 및 설계 워크플로우에 활용할 수 있게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.