[논문 리뷰] LayoutGPT: Compositional Visual Planning and Generation with Large Language Models
LayoutGPT는 CSS 유사한 인-context 프롬 prompts를 이용해 LLM을 시각적 계획자로 변환하고, 영역-제어 이미지 생성 모델과 결합했을 때 2D 레이아웃과 3D 실내 씬 레이아웃의 충실도와 효율성을 향상시킵니다.
Attaining a high degree of user controllability in visual generation often requires intricate, fine-grained inputs like layouts. However, such inputs impose a substantial burden on users when compared to simple text inputs. To address the issue, we study how Large Language Models (LLMs) can serve as visual planners by generating layouts from text conditions, and thus collaborate with visual generative models. We propose LayoutGPT, a method to compose in-context visual demonstrations in style sheet language to enhance the visual planning skills of LLMs. LayoutGPT can generate plausible layouts in multiple domains, ranging from 2D images to 3D indoor scenes. LayoutGPT also shows superior performance in converting challenging language concepts like numerical and spatial relations to layout arrangements for faithful text-to-image generation. When combined with a downstream image generation model, LayoutGPT outperforms text-to-image models/systems by 20-40% and achieves comparable performance as human users in designing visual layouts for numerical and spatial correctness. Lastly, LayoutGPT achieves comparable performance to supervised methods in 3D indoor scene synthesis, demonstrating its effectiveness and potential in multiple visual domains.
연구 동기 및 목표
- 대형 언어 모델(Large Language Models)이 텍스트 조건으로부터 2D 및 3D 생성을 위한 시각적 레이아웃을 계획하도록 한다.
- 세밀한 입력 대신 언어 기반 레이아웃 계획으로 사용자의 노력을 줄인다.
- 인-컨텍스트 시연과 CSS 스타일 프롬프트가 LLM에 시각적 상식을 주입한다는 것을 보여준다.
- 2D T2I 및 3D 실내 씬 합성 전반에서 레이아웃 충실성과 이미지/장면 품질을 벤치마킹한다.
- 3D 실내 씬 과제에서 최첨단 감독 학습 방법과의 경쟁력을 보인다.
제안 방법
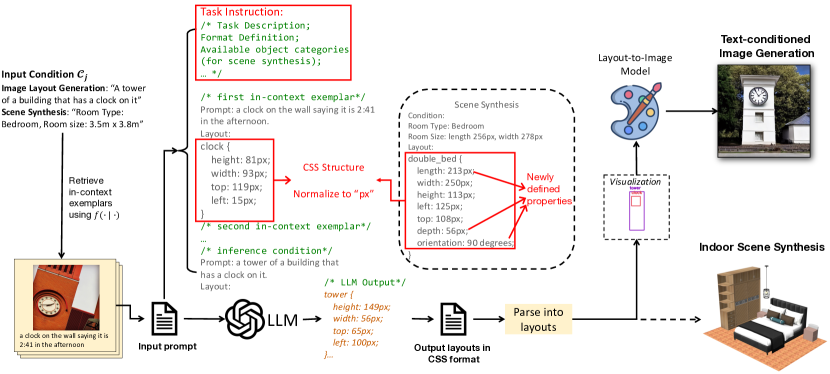
- 레이아웃을 CSS 유사 형식의 구조화된 프로그램으로 표현해 LLM에 공간적 의미를 명확하게 한다.
- 학습을 돕기 위해 작업 지시를 앞에 추가하고 값을 일관된 스케일(최대 256px)로 정규화한다.
- 유사도 기반으로 인-콘텍스트 예시를 선택한다(2D 프롬프트는 CLIP 기반; 3D의 경우 방 크기 차이)를 이용하고 예시는 역순으로 제시한다.
- LLM이 생성한 레이아웃을 다운스트림의 레이아웃-투-이미지 또는 3D 씬 렌더링 모델과 결합해 최종 시각화를 생성한다.
- 가구의 카테고리, 위치, 크기 및 방향을 예측하여 3D 실내 씬 합성으로 프레임워크를 확장하고, 그 후 렌더링한다.
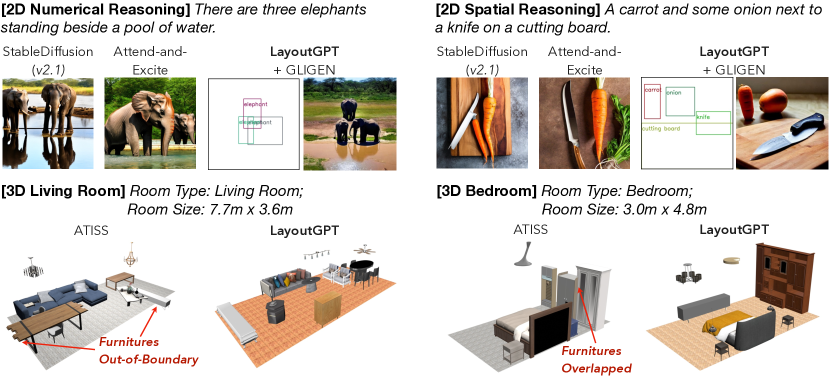
실험 결과
연구 질문
- RQ1CSS 유사 레이아웃으로 안내될 때 LLM이 텍스트 프롬프트로부터 충실한 객체 수 및 공간 관계를 생성할 수 있는가?
- RQ2인-컨텍스트 CSS 구조화 프롬프가 일반 텍스트 프롬프에 비해 레이아웃 충실도와 다운스트림 이미지 품질을 향상시키는가?
- RQ3레이아웃GPT가 미세 조정 없이 2D 이미지 레이아웃에서 3D 실내 씬 합성으로 얼마나 잘 확장되는가?
- RQ4작업 지시, CSS 형식화 및 값 정규화가 2D 및 3D 작업의 레이아웃 정확도에 미치는 영향은 무엇인가?
주요 결과
- LayoutGPT는 2D 생성에서 GLIP 기반 레이아웃 정확도 면에서 엔드 투 엔드 텍스트-투-이미지 모델보다 20-40% 우수하다.
- LayoutGPT는 2D 레이아웃에서 숫자적 및 공간적 정확성 면에서 인간이 생성한 레이아웃과 유사한 성능을 달성한다.
- LayoutGPT는 침실 및 거실 장면에 걸친 평균 지표(FID, out-of-bounds 등)에서 3D 실내 씬 합성에 대해 감독 방법에 비해 경쟁력 있거나 더 우수한 결과를 얻는다.
- 고찰 연구에서 CSS 형식의 인-컨텍스트 시연 및 정규화가 레이아웃 충실성에 중요하며, CSS가 강한 이점을 제공함이 나타난다.
- LayoutGPT는 밀집 레이아웃, 텍스트 기반 인페인팅 및 반사실적 프롬프트에서도 견고한 성능을 보이며 강한 시각적 상식 및 일반화 능력을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.