[논문 리뷰] Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs
이 논문은 255편의 논문을 체계적으로 분석하여 OpenAI GPT-3.5 및 GPT-4의 데이터 오염과 평가 남용을 검토하고, 약 42%의 누출이 총 약 4.7 million 샘플에 걸쳐 263 벤치마크에서 발생했으며 재현성 및 공정성 문제를 강조합니다.
Natural Language Processing (NLP) research is increasingly focusing on the use of Large Language Models (LLMs), with some of the most popular ones being either fully or partially closed-source. The lack of access to model details, especially regarding training data, has repeatedly raised concerns about data contamination among researchers. Several attempts have been made to address this issue, but they are limited to anecdotal evidence and trial and error. Additionally, they overlook the problem of \emph{indirect} data leaking, where models are iteratively improved by using data coming from users. In this work, we conduct the first systematic analysis of work using OpenAI's GPT-3.5 and GPT-4, the most prominently used LLMs today, in the context of data contamination. By analysing 255 papers and considering OpenAI's data usage policy, we extensively document the amount of data leaked to these models during the first year after the model's release. We report that these models have been globally exposed to $\sim$4.7M samples from 263 benchmarks. At the same time, we document a number of evaluation malpractices emerging in the reviewed papers, such as unfair or missing baseline comparisons and reproducibility issues. We release our results as a collaborative project on https://leak-llm.github.io/, where other researchers can contribute to our efforts.
연구 동기 및 목표
- 게시된 연구를 통해 GPT-3.5 및 GPT-4에 대한 간접적 데이터 오염(데이터 누출)을 정량화한다.
- 누출된 데이터가 추가 학습에 어떻게 사용될 수 있는지 평가하고, 공정한 비교와 평가에 미치는 영향을 판단한다.
- 폐쇄형 LLM을 사용하는 연구에서 일반적으로 나타나는 평가 악용 및 재현성 장애를 식별한다.
- 폐쇄형 LLM의 평가 엄격성을 높이기 위한 모범 사례를 제안한다.
제안 방법
- GPT-3.5 및 GPT-4를 평가하는 255편의 논문에 대한 체계적 문헌 고찰을 수행한다.
- 웹 인터페이스와 API 접근을 사용한 논문을 구분하고 OpenAI의 데이터 사용 정책에 따른 잠재적 데이터 누출을 매핑한다.
- 보고된 경우 데이터셋별 누출 데이터를 추정하고, 그렇지 않으면 전체 데이터셋 사용으로 가정한다.
- 재현성을 위해 프롬프트 가용성, 코드 저장소, 데이터셋 분할 및 모델 버전 보고를 평가한다.
- 기준선과의 비교를 통해 평가 공정성을 분석하고 모델 간 데이터 사용의 일관성을 보장한다.
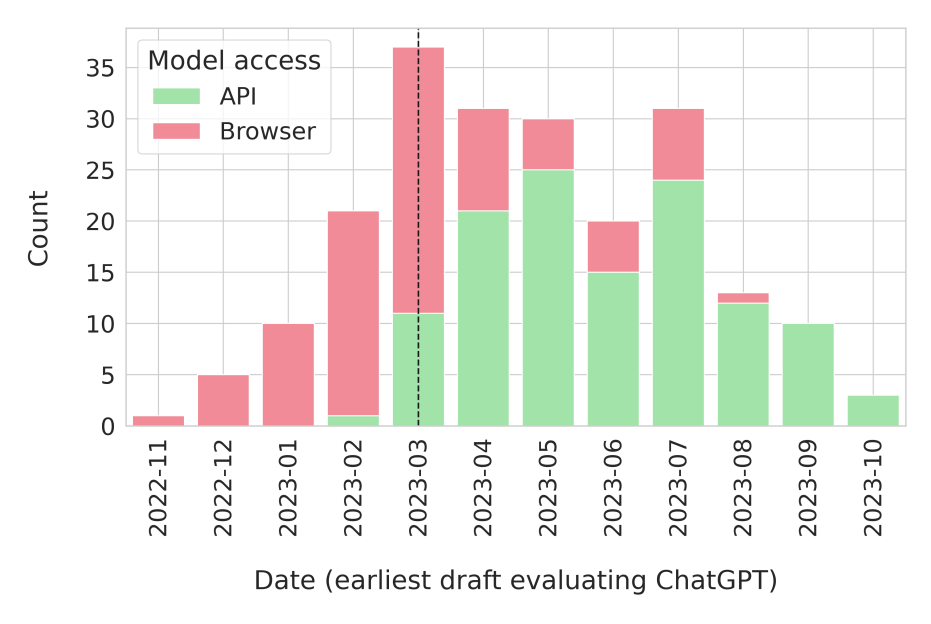
실험 결과
연구 질문
- RQ1지난해에 GPT-3.5 및 GPT-4에 명백히 누출된 데이터셋은 무엇인가?
- RQ2이 모델들을 평가한 논문들이 기존 기준선과 공정한 비교를 포함하는가?
- RQ3폐쇄형 LLM 평가에서 재현성과 공정성을 해치는 일반적인 관행은 무엇인가?
- RQ4폐쇄형 LLM의 데이터 오염과 평가 남용을 완화할 지침은 무엇인가?
주요 결과
- ~42%의 검토된 논문이 GPT-3.5 또는 GPT-4에 데이터를 누출했으며, 총 ~4.7 million 샘플이 263개의 벤치마크에 걸쳐 누출되었다.
- 웹 인터페이스를 통해 ChatGPT에 접근한 논문은 90편(~42%)으로, OpenAI가 학습에 사용할 수 있는 데이터를 노출했다.
- 누출된 데이터셋은 다양한 작업에 걸쳐 분산되었고, 자연어 추론, 질의응답, 자연어 생성에서 누출이 높은 편이었다.
- 사용된 프롬프트를 보고한 비율은 약 91%에 불과했고; 코드 저장소를 제공한 비율은 약 53%; 동료심사/프리프린트 논문에서 각각 모델 버전 정보를 제공한 비율은 40%/23%에 불과했다.
- 다수의 연구가 불공정하거나 불완전한 비교를 수행했으며, 종종 ChatGPT를 공개 모델보다 적은 샘플에서 평가하고 서로 다른 데이터 크기로 평가했다.
- 노출을 문서화하고 커뮤니티 기여를 촉진하기 위해 협력 공개 자원(leak-llm.github.io)가 공개되었다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.