[논문 리뷰] Leak Proof PDBBind: A Reorganized Dataset of Protein-Ligand Complexes for More Generalizable Binding Affinity Prediction
본 논문은 LP-PDBBind를 도입하여 PDBBind의 정제되고 누출 방지된 재구성을 제시하고, 이 데이터에서 네 가지 스코어링 함수를 재학습시키며, 3D-구조 기반 방법에서 BDB2020+와 같은 독립 벤치마크에서 일반화가 향상되었음을 보여주고, 순전히 시퀀스 기반 모델에는 이익이 제한적임을 강조한다.
Many physics-based and machine-learned scoring functions (SFs) used to predict protein-ligand binding free energies have been trained on the PDBBind dataset. However, it is controversial as to whether new SFs are actually improving since the general, refined, and core datasets of PDBBind are cross-contaminated with proteins and ligands with high similarity, and hence they may not perform comparably well in binding prediction of new protein-ligand complexes. In this work we have carefully prepared a cleaned PDBBind data set of non-covalent binders that are split into training, validation, and test datasets to control for data leakage, defined as proteins and ligands with high sequence and structural similarity. The resulting leak-proof (LP)-PDBBind data is used to retrain four popular SFs: AutoDock Vina, Random Forest (RF)-Score, InteractionGraphNet (IGN), and DeepDTA, to better test their capabilities when applied to new protein-ligand complexes. In particular we have formulated a new independent data set, BDB2020+, by matching high quality binding free energies from BindingDB with co-crystalized ligand-protein complexes from the PDB that have been deposited since 2020. Based on all the benchmark results, the retrained models using LP-PDBBind consistently perform better, with IGN especially being recommended for scoring and ranking applications for new protein-ligand systems.
연구 동기 및 목표
- PDBBind 데이터셋의 데이터 누출 및 품질 비일관성 문제를 해결하기 위해 정제되고 비공유(non-covalent), 누출 방지 분할(LP-PDBBind)을 생성한다.
- LP-PDBBind에서 기존 스코어링 함수들을 재학습시켰을 때 새로운 단백질-리간드 복합체에 대한 일반화에 미치는 영향을 평가한다.
- 재학습된 모델의 전달된 성능을 평가하기 위한 독립 벤치마크(BDB2020+)를 제공한다.
- 누출 방지 데이터 분할과 3D-구조 기반 표현에서 어떤 모델 계열이 가장 큰 이점을 얻는지에 대한 가이드를 제공한다.
제안 방법
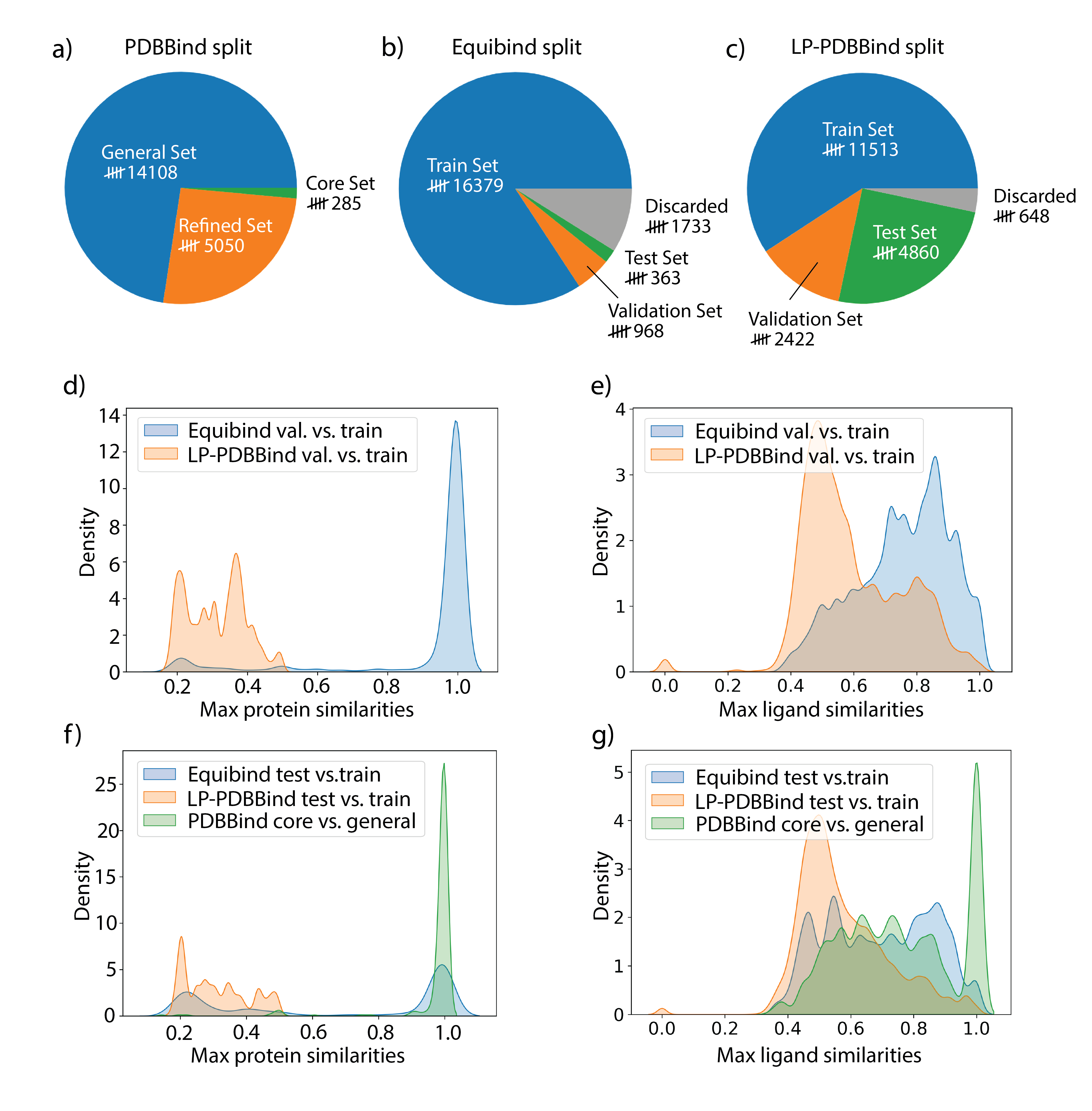
- PDBBind를 정제하고 필터링하여 비공유(non-covalent), 고품질 부분집합(CL1, 선택적으로 CL2/CL3)을 생성하고 단백질 카테고리별 유사도 기반 누출 제어 분할을 정의한다.
- Morgan 지문과 Dice 유사도로 리간드 유사도를 계산하고; 카테고리 내에서 서열 정렬으로 단백질 유사도를 계산하며; 학습-테스트 누출을 최소화하기 위한 반복적 시드 기반 분할을 적용한다.
- LP-PDBBind에서 네 가지 스코어링 함수 계열을 재학습: AutoDock Vina(재가중 3D 항목), RF-Score(원자 유형 접촉에 대한 랜덤 포레스트), IGN(3D 구조 기반 그래프 신경망), 그리고 DeepDTA(시퀀스/SMILES 기반 기본 모델).
- 최근 BindingDB 기록을 PDB 구조에 유사도 제어를 적용하여 매칭해 BDB2020+를 구성하고, 평가를 위한 독립 벤치마크를 만든다.
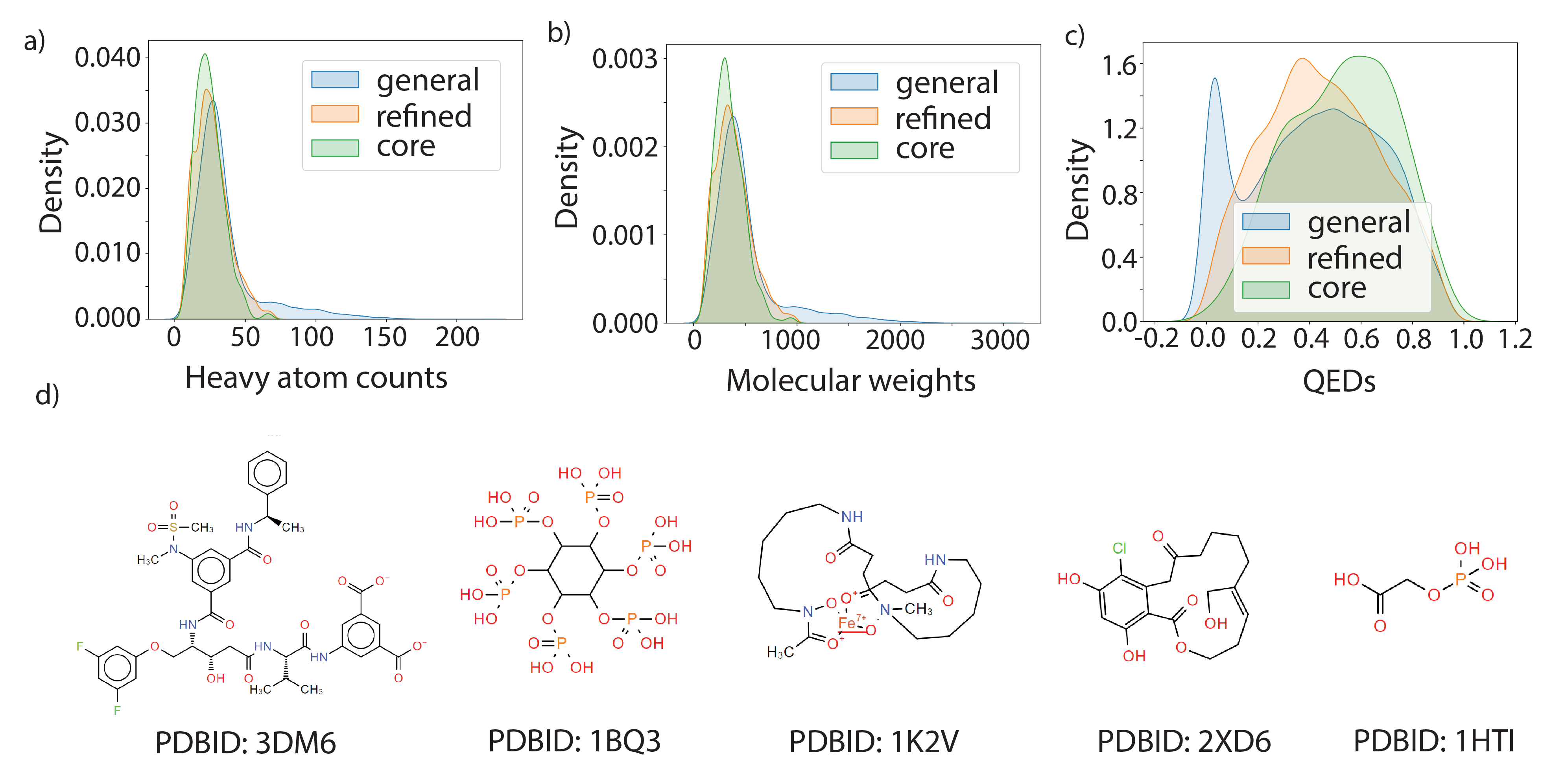
실험 결과
연구 질문
- RQ1LP-PDBBind를 통해 데이터 누출을 제거하면 기존 SFs의 새로운 단백질-리간드 복합체에 대한 일반화가 향상되는가?
- RQ2LP-PDBBind에서 학습하고 독립 벤치마크에서 평가할 때 3D-구조 기반 모델과 시퀀스 기반 모델은 어떻게 비교되는가?
- RQ3LP-PDBBind에서 재학습한 것이 학습, 검증, 테스트 세트 및 BDB2020+와 같은 독립 벤치마크에서의 성능 지표에 미치는 영향은 무엇인가?
- RQ4누출-방지 재학습 후 어떤 모델 계열이 새로운 복합체와 독립 데이터셋에 가장 강력한 전이 가능성을 보이는가?
주요 결과
- LP-PDBBind에서 재학습하면 3D-구조 기반 모델(IGN, AutoDock Vina, RF-Score)이 BDB2020+와 같은 독립 벤치마크에서 일반화가 향상된다.
- IGN은 재학습 후 새로운 단백질-리간드 시스템의 스코어링 및 랭킹에서 꾸준히 최고 성능 중 하나를 차지한다.
- DeepDTA(1D 시퀀스 기반)는 재학습 후 일반화가 감소하고 3D 기반 모델에 비해 독립 벤치마크에서 성능이 더 떨어진다.
- 원래 MLSF 모델은 훈련 데이터 중첩으로 인해 누출에 취약한 코어에서 과대 성능을 보이며, LP-PDBBind는 이들의 실제 일반화 격차를 드러낸다.
- LP-PDBBind 분할은 훈련 데이터와의 유사도를 제어한 더 큰 테스트 세트를 제공하여 전이 가능성의 보다 현실적인 평가를 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.