[논문 리뷰] Learning Mask-aware CLIP Representations for Zero-Shot Segmentation
논문은 마스크 제안을 구분 가능하게 만들어 CLIP의 마스크 제안을 무시하는 특성을 개선하고 전이 가능성을 유지하면서 제로샷 분할을 향상시키는 MAFT를 도입합니다.
Recently, pre-trained vision-language models have been increasingly used to tackle the challenging zero-shot segmentation task. Typical solutions follow the paradigm of first generating mask proposals and then adopting CLIP to classify them. To maintain the CLIP's zero-shot transferability, previous practices favour to freeze CLIP during training. However, in the paper, we reveal that CLIP is insensitive to different mask proposals and tends to produce similar predictions for various mask proposals of the same image. This insensitivity results in numerous false positives when classifying mask proposals. This issue mainly relates to the fact that CLIP is trained with image-level supervision. To alleviate this issue, we propose a simple yet effective method, named Mask-aware Fine-tuning (MAFT). Specifically, Image-Proposals CLIP Encoder (IP-CLIP Encoder) is proposed to handle arbitrary numbers of image and mask proposals simultaneously. Then, mask-aware loss and self-distillation loss are designed to fine-tune IP-CLIP Encoder, ensuring CLIP is responsive to different mask proposals while not sacrificing transferability. In this way, mask-aware representations can be easily learned to make the true positives stand out. Notably, our solution can seamlessly plug into most existing methods without introducing any new parameters during the fine-tuning process. We conduct extensive experiments on the popular zero-shot benchmarks. With MAFT, the performance of the state-of-the-art methods is promoted by a large margin: 50.4% (+ 8.2%) on COCO, 81.8% (+ 3.2%) on Pascal-VOC, and 8.7% (+4.3%) on ADE20K in terms of mIoU for unseen classes. The code is available at https://github.com/jiaosiyu1999/MAFT.git.
연구 동기 및 목표
- Address the insensitivity of frozen CLIP to different mask proposals in zero-shot segmentation.
- Develop a mask-aware fine-tuning method that preserves CLIP transferability.
- Enable efficient, plug-and-play integration of MAFT with existing frozen-CLIP segmentation pipelines.
제안 방법
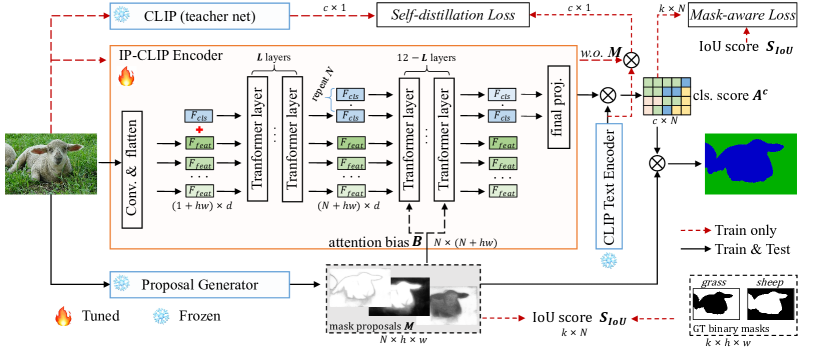
- Introduce Image-Proposals CLIP Encoder (IP-CLIP Encoder) to process arbitrary numbers of images and mask proposals via masked multi-head attention.
- Design mask-aware loss to align CLIP predicted proposal scores with IoU-based quality signals.
- Introduce a self-distillation loss to maintain CLIP’s zero-shot transferability by aligning IP-CLIP outputs with a frozen CLIP teacher.
- Fine-tune only the IP-CLIP Encoder (leaving Proposal Generator and CLIP Text Encoder frozen) in a lightweight MAFT process.
- Provide a plug-and-play approach that can be added to existing frozen-CLIP zero-shot segmentation methods.
- Demonstrate robustness across different backbones and open-vocabulary settings.

실험 결과
연구 질문
- RQ1How does CLIP's sensitivity to mask proposals affect zero-shot segmentation performance?
- RQ2Can a mask-aware fine-tuning regime improve proposal classification without sacrificing transferability?
- RQ3Is IP-CLIP Encoder capable of handling arbitrary numbers of proposals efficiently?
- RQ4Does MAFT improve performance across standard zero-shot segmentation benchmarks and open-vocabulary settings?
주요 결과
- MAFT significantly improves unseen-class mIoU on standard benchmarks when plugged into existing methods.
- IP-CLIP Encoder with mask-aware training reduces false positives by making CLIP respond differently to varied proposals.
- Self-distillation preserves transferability while enabling mask-aware fine-tuning.
- MAFT is compatible with multiple CLIP backbones and can extend to open-vocabulary segmentation with notable gains.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.