[논문 리뷰] Learning Robust Statistics for Simulation-based Inference under Model Misspecification
논문은 시뮬레이션 기반 추론(SBI)에 대한 일반적 접근법을 도입하여 NPE, ABC 등 SBI 방법들에서 모델의 잘못 지정(misspecification)을 완화하고 MMD 기반 잘못 지정 페널티로 통계 학습 목표를 정규화한다.
Simulation-based inference (SBI) methods such as approximate Bayesian computation (ABC), synthetic likelihood, and neural posterior estimation (NPE) rely on simulating statistics to infer parameters of intractable likelihood models. However, such methods are known to yield untrustworthy and misleading inference outcomes under model misspecification, thus hindering their widespread applicability. In this work, we propose the first general approach to handle model misspecification that works across different classes of SBI methods. Leveraging the fact that the choice of statistics determines the degree of misspecification in SBI, we introduce a regularized loss function that penalises those statistics that increase the mismatch between the data and the model. Taking NPE and ABC as use cases, we demonstrate the superior performance of our method on high-dimensional time-series models that are artificially misspecified. We also apply our method to real data from the field of radio propagation where the model is known to be misspecified. We show empirically that the method yields robust inference in misspecified scenarios, whilst still being accurate when the model is well-specified.
연구 동기 및 목표
- Misspecified가 요약통계치를 사용할 때 SBI에 미치는 영향을 식별한다.
- robust statistics를 얻기 위한 정규화 학습 목표를 개발한다.
- NPE와 ABC(및 RNPE와의 비교) 전반에서 접근법의 로버스트성을 입증한다.
- 합성 시계열 모델과 실제 라디오 전파 데이터셋에의 적용 가능성을 보인다.
제안 방법
- SBI에서 모델-요약자 쌍의 misspecification을 정의하고 misspecification 여유를 통해 정량화한다.
- 시뮬레이션 통계치와 관측 통계치 간의 차이를 벌주는 정규화 항을 추가하여 Robust statistics (RS) 손실을 도입한다.
- 관찰된 통계치와 시뮬레이션 통계치의 분포를 비교하기 위한 정규화 거리로 최대 평균 차이(MMD)를 사용한다.
- RS 손실을 사용하여 요약 네트워크를 추론 네트워크(NPE)와 함께 또는 오토인코더(AE)와 함께 공동 학습한다.
- MMD 항에 대한 닫힘 형태의 추정치를 제공하고 커널, 부분집합 크기 l 등 실제적 선택을 설명한다.
- 정규화 가중치 lambda가 로버스트성과 정보 함량 사이를 어떻게 조정하는지 보여주며, NPE/ABC와 사전 간 보간하는 모습을 설명한다.
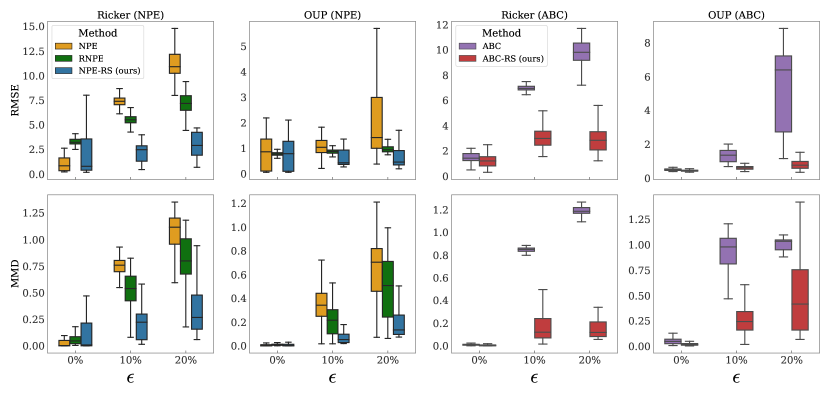
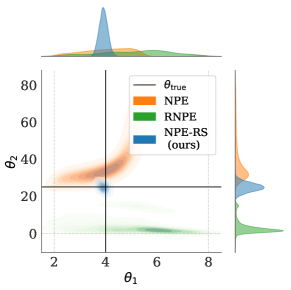
실험 결과
연구 질문
- RQ1misspecification이 NPE와 ABC로 생산된 SBI 후방분포에 어떤 영향을 미치는가?
- RQ2RS 손실을 통한 로버스트 통계 학습이 잘 정의된 경우 성능을 유지하면서 misspecification 아래 후방 편향을 감소시킬 수 있는가?
- RQ3RS 접근법이 SBI의 여러 방법(NPE, ABC)에서 일반적이며 다양한 데이터 모달리티에 적응 가능한가?
- RQ4실무에서 정규화 가중치 lambda를 어떻게 선택해야 하는가?
주요 결과
- NPE-RS 및 ABC-RS는 misspecification(epsilon > 0) 하에서 비로버스트 버전보다 RMSE 및 MMD 지표에서 우수하다.
- 잘 정의된 설정에서는 NPE-RS 및 ABC-RS가 표준 NPE 및 ABC와 비슷한 성능을 보인다.
- RNPE는 표준 NPE에 비해 로버스트성을 개선하지만 여전히 진정한 매개변수에서 벗어나게 할 수 있는 반면, NPE-RS는 진짜 값에 더 근접한다.
- RS 프레임워크는 사전 잘못 지정에 대한 로버스트성도 제공하여 사전이 이를 제외하는 경우에도 포스트eriors를 진짜 매개변수 근처에 유지한다.
- 모델이 잘 정의된 경우에도 정확성을 유지하고, 시간 시계열 모델(Ricker, OU) 및 실제 라디오 전파 데이터셋에 걸쳐 로버스트한 추론을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.