[논문 리뷰] Learning to "Segment Anything" in Thermal Infrared Images through Knowledge Distillation with a Large Scale Dataset SATIR
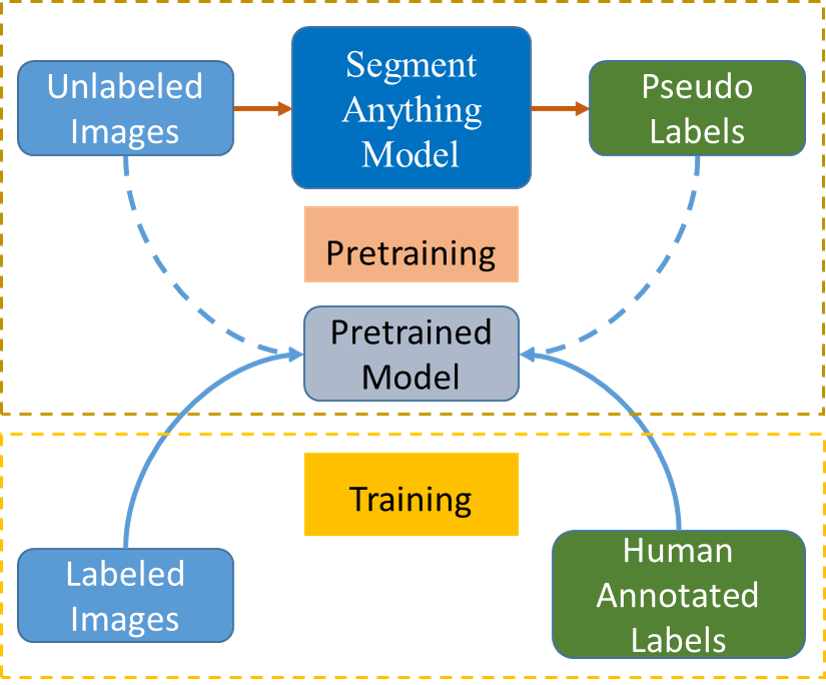
이 논문은 SAM(Segment Anything Model)을 사용하여 열화상 세그멘테이션 모델의 사전학습을 위한 가짜 라벨을 생성하고 SATIR(100k+ images)을 만들어 지식 증류를 통해 SODA 실제 하위집합 세그멘테이션 성능을 향상시켰다.
The Segment Anything Model (SAM) is a promptable segmentation model recently introduced by Meta AI that has demonstrated its prowess across various fields beyond just image segmentation. SAM can accurately segment images across diverse fields, and generating various masks. We discovered that this ability of SAM can be leveraged to pretrain models for specific fields. Accordingly, we have proposed a framework that utilizes SAM to generate pseudo labels for pretraining thermal infrared image segmentation tasks. Our proposed framework can effectively improve the accuracy of segmentation results of specific categories beyond the SOTA ImageNet pretrained model. Our framework presents a novel approach to collaborate with models trained with large data like SAM to address problems in special fields. Also, we generated a large scale thermal infrared segmentation dataset used for pretaining, which contains over 100,000 images with pixel-annotation labels. This approach offers an effective solution for working with large models in special fields where label annotation is challenging. Our code is available at https://github.com/chenjzBUAA/SATIR
연구 동기 및 목표
- Motivate pretraining segmentation models in specialized domains using large-scale models like SAM.
- Propose a knowledge distillation framework to convert SAM masks into pseudo labels for thermal IR data.
- Create a large-scale SATIR dataset with pixel-level annotations for pretraining.
- Demonstrate improved segmentation performance on a real thermal IR dataset (SODA).
제안 방법
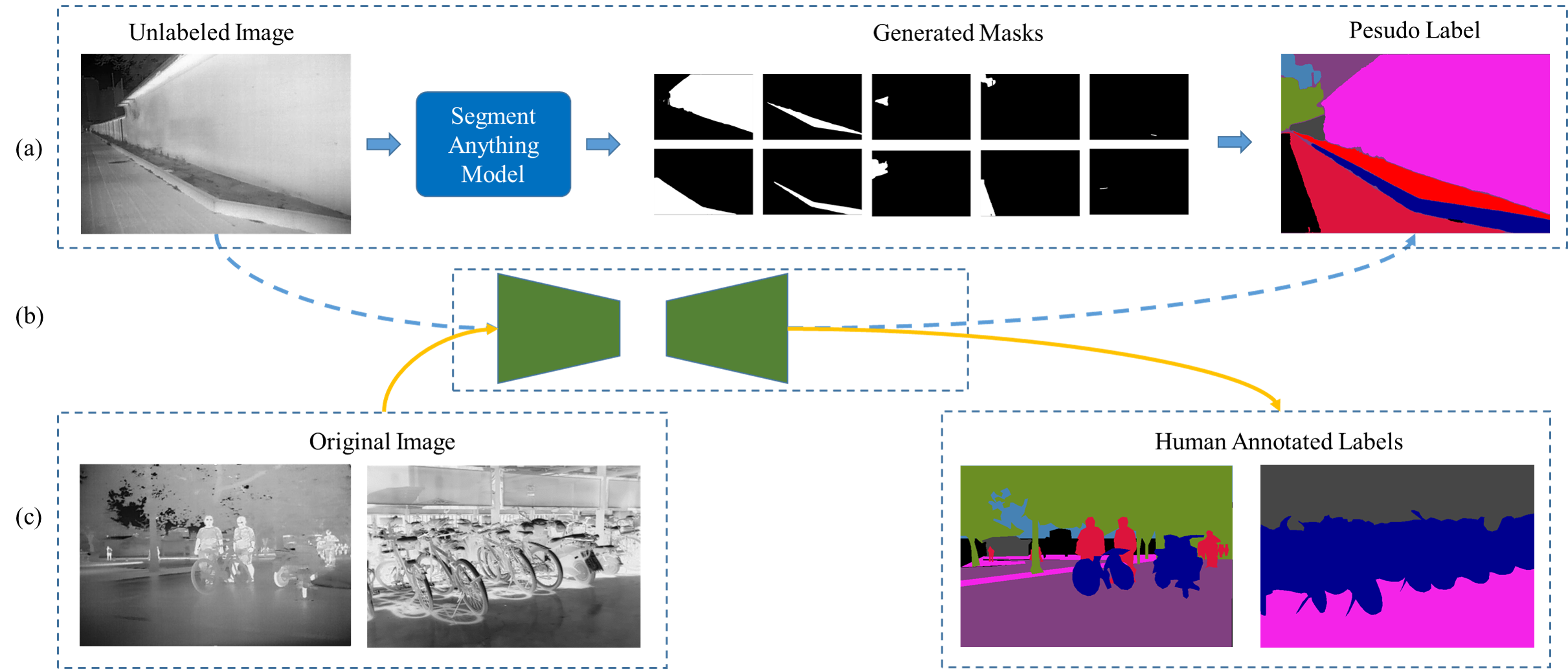
- Apply SAM to unlabeled thermal IR images to generate masks with point/region prompts.
- Construct pseudo labels by ranking SAM masks and assigning category indices to top masks.
- Pretrain a segmentation model using the pseudo-labeled SATIR dataset to obtain a pretrained model.
- Fine-tune the pretrained model on the target thermal IR segmentation task.
- Evaluate the approach using SegFormer as backbone on the SODA real subset.
- Compare against no-pretrain and ImageNet-pretrained baselines.
실험 결과
연구 질문
- RQ1Can SAM-generated masks provide useful pseudo labels for pretraining thermal IR segmentation models?
- RQ2Does knowledge distillation from SAM improve segmentation performance on thermal IR data beyond standard pretraining?
- RQ3What is the impact of SATIR pretraining on downstream performance compared to ImageNet pretraining?
- RQ4How large and diverse does a thermal IR pretraining dataset need to be to yield gains on real-world targets?
주요 결과
| Pretraining | Backbone | mIoU | Fβ^ω |
|---|---|---|---|
| - | SegFormer | 0.6514 | 0.8156 |
| ImageNet | SegFormer | 0.6775 | 0.8374 |
| SATIR | SegFormer | 0.6906 | 0.8426 |
- SATIR-pretrained SegFormer achieves higher mIoU and Fβω on SODA real subset than both no-pretrain and ImageNet-pretrained baselines.
- mIoU improves from 0.6514 (no pretrain) and 0.6775 (ImageNet) to 0.6906 with SATIR.
- Fβω improves from 0.8156 (no pretrain) and 0.8374 (ImageNet) to 0.8426 with SATIR.
- The framework demonstrates that large-model knowledge can benefit specialized domain pretraining, even with crude mask-labeling.
- SATIR contains over 100k thermal IR images with pixel-level pseudo labels generated via SAM masks.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.