[논문 리뷰] Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
이 논문은 AlpacaEval의 길이 편향을 제거하기 위한 회귀 기반 디바이싱 방법을 제시하여 AlpacaEval-LC를 만들어내고, 이는 인간의 순위와 더 잘 일치하며 말투 신호에 대해 더 강건하다.
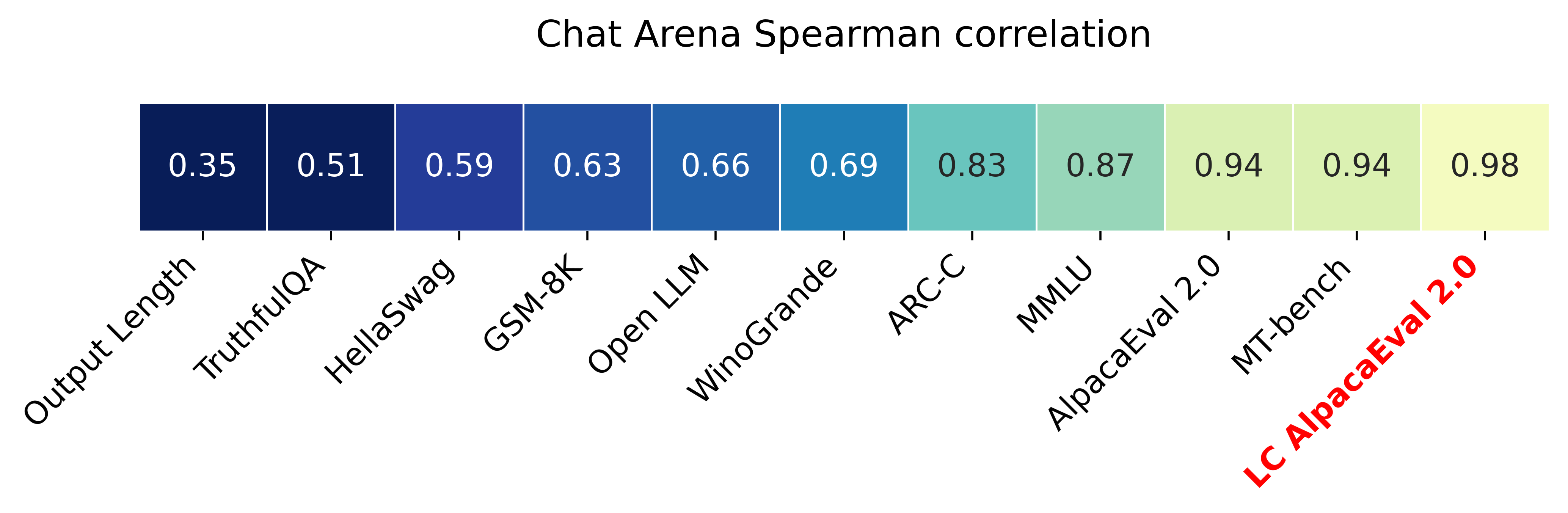
LLM-based auto-annotators have become a key component of the LLM development process due to their cost-effectiveness and scalability compared to human-based evaluation. However, these auto-annotators can introduce biases that are hard to remove. Even simple, known confounders such as preference for longer outputs remain in existing automated evaluation metrics. We propose a simple regression analysis approach for controlling biases in auto-evaluations. As a real case study, we focus on reducing the length bias of AlpacaEval, a fast and affordable benchmark for instruction-tuned LLMs that uses LLMs to estimate response quality. Despite being highly correlated with human preferences, AlpacaEval is known to favor models that generate longer outputs. We introduce a length-controlled AlpacaEval that aims to answer the counterfactual question: "What would the preference be if the model's and baseline's output had the same length?" To achieve this, we first fit a generalized linear model to predict the biased auto-annotator's preferences based on the mediators we want to control for (length difference) and other relevant features. We then obtain length-controlled preferences by predicting preferences while conditioning the GLM with a zero difference in lengths. Length-controlling not only improves the robustness of the metric to manipulations in model verbosity, but we also find that it increases the Spearman correlation with LMSYS Chatbot Arena from 0.94 to 0.98.
연구 동기 및 목표
- 채팅 LLM의 자동 평가에서 잘못된 길이 기반 편향을 줄인다.
- AlpacaEval의 바람직한 특성을 보존하는 간단하고 해석 가능한 디바이싱 방법을 제공한다.
- 인간 판단(Chatbot Arena)과의 상관관계를 향상시키고 길이 변경에 의한 게임화에 대한 강건성을 높인다.
- 리더보드 및 RLHF 맥락에서 사용할 수 있는 편향 제거된 접근 가능한 평가 프레임워크를 제공한다.
제안 방법
- 세 가지 구성요소(모델 신원, 출력 길이, 지시 난이도)를 사용하여 자동 평가자의 선호를 예측하기 위해 일반화 선형 모델을 적합한다.
- 정상화된 길이 차이의 tanh로 모델링된 길이 항을 가진 로지스틱 회귀를 사용하여 체감 수익 감소를 반영한다.
- 길이 항을 제거하여 길이 제어된 승률을 얻고, 출력이 동일한 길이를 갖는 반사실적 추정치를 갖는다.
- 새로운 모델을 추가할 때의 강건성을 보장하기 위해 교차 검증된 L2 규제 적합과 별개의 모델별 계수를 사용하여 GLM을 훈련한다.
- 길이-결합 항에 약한 규제를 도입하여 악의적인 잘림 공격에 저항한다.
- LC 승률을 직관적인 반사실적 구성으로 일반 승률로 해석하고 두 리더보드 모델 간의 쌍대 예측을 가능하게 한다.
실험 결과
연구 질문
- RQ1출력 길이가 AlpacaEval 판단에 얼마나 영향을 미치는가?
- RQ2회귀 기반 디바이싱이 모델 신원과 과제 난이도 효과를 보존하면서 길이 관련 분산을 제거할 수 있는가?
- RQ3길이 제어 AlpacaEval(AlpacaEval-LC)이 원래 지표보다 인간 평가(Chatbot Arena)와 더 잘 상관되는가?
- RQ4AlpacaEval-LC가 출력 자르기와 같은 간단한 적대적 게임에 강건한가?
주요 결과
- AlpacaEval-LC는 원래의 AlpacaEval에 비해 길이 기반 게임성에 대한 취약성을 줄인다.
- AlpacaEval-LC가 Chatbot Arena와의 Spearman 상관관계를 0.94에서 0.98로 높인다.
- 길이 제어는 길이가 짧은 경향이 있는 독점 모델의 리더보드 순위를 개선하고, 오픈 소스 모델은 상대적으로 불이익을 받는다.
- GLM 기반 디바이싱은 승률로 해석 가능하며 리더보드 기준선들 간의 쌍별 결과를 예측할 수 있다.
- 규제는 표준 모델의 성능을 유지하면서 악의적 자르기 공격을 줄인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.