[논문 리뷰] Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation
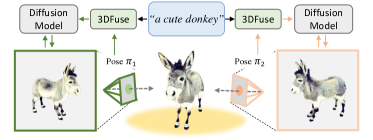
3DFuse는 coarse 3D priors에서 깊이 맵을 조건으로 하고 semantic coding과 LoRA를 사용해 SDS 기반 텍스트-3D 생성에서 3D 일관성을 개선하여 사전 학습된 2D 확산 모델에 3D 인식을 주입합니다.
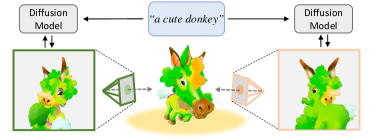
Text-to-3D generation has shown rapid progress in recent days with the advent of score distillation, a methodology of using pretrained text-to-2D diffusion models to optimize neural radiance field (NeRF) in the zero-shot setting. However, the lack of 3D awareness in the 2D diffusion models destabilizes score distillation-based methods from reconstructing a plausible 3D scene. To address this issue, we propose 3DFuse, a novel framework that incorporates 3D awareness into pretrained 2D diffusion models, enhancing the robustness and 3D consistency of score distillation-based methods. We realize this by first constructing a coarse 3D structure of a given text prompt and then utilizing projected, view-specific depth map as a condition for the diffusion model. Additionally, we introduce a training strategy that enables the 2D diffusion model learns to handle the errors and sparsity within the coarse 3D structure for robust generation, as well as a method for ensuring semantic consistency throughout all viewpoints of the scene. Our framework surpasses the limitations of prior arts, and has significant implications for 3D consistent generation of 2D diffusion models.
연구 동기 및 목표
- SDS 기반 텍스트-3D 생성에서 3D 불일치(“Janus 문제”)를 동기 부여하고 해결합니다.
- 사전 학습된 2D 확산 모델에 3D 인식 조건 메커니즘을 도입합니다.
- 다양한 시점에서 강건하고 기하학적으로 일관된 3D 장면 생성을 가능하게 합니다.
- 의미 부호화 및 LoRA를 통해 3D 생성에서 의미적 일관성과 제어 가능성을 향상합니다.
제안 방법
- 텍스트 임베딩을 최적화하여 생성된 이미지에 맞춰 시맨틱 코드 s=(hat{x}, hat{e})를 얻는 시맨틱 코드 샘플링.
- 오프 더 셸프 3D 모델을 사용해 시맨틱 코드 이미지에서 coarse 3D 점 구름을 구성하고 각 시점에 대한 깊이 맵 p를 투영합니다.
- 프로젝션된 깊이 맵을 Diffusion U-Net에 ControlNet 스타일 잔여 방식으로 공급하는 희소 깊이 주입 모듈을 도입하여 3D 인식 조건을 제공합니다.
- Diffusion 모델을 고정된 상태로 유지한 채 깊이 주입기를 학습하고 필요 시 LoRA 계층만 선택적으로 학습하여 효율적인 파인 튜닝을 가능하게 합니다.
- LoRA를 Diffusion U-Net에 적용하여 시점 간 의미적 일관성을 개선하고 저차원 적합 레이어를 조정합니다.
- DreamFusion, SJC, ProlificDreamer 기반의 다중 SDS 기반 벤치마크와 MCC 기반 3D priors에 걸친 적응을 시연합니다.
실험 결과
연구 질문
- RQ1 coarse 3D priors에서 시점별 깊이 맵으로 사전 학습된 2D 확산 모델을 조건화하는 것이 SDS 기반 텍스트-3D 생성에서 3D 일관성을 개선할 수 있습니까?
- RQ2시맨틱 코딩이 프롬프트의 모호성을 줄여 시점 간 의미적으로 일관된 3D 장면을 제공합니까?
- RQ33D 인식 조건화가 서로 다른 벤치마크에서 충실도 및 기하학적 강건성에 어떤 영향을 줍니까?
- RQ43D 생성에서 의미적 일관성을 위해 LoRA를 사용하는 것이 어떤 효과를 냅니까?
- RQ5제안된 접근이 다양한 2D 확산 백본과 3D priors에 확장 가능합니까?
주요 결과
| Method | Variance |
|---|---|
| SJC + 3DFuse (Ours) | 0.0499 |
| SJC (Wang et al. 2022a) | 0.0870 |
- 3DFuse는 DreamFusion, SJC, ProlificDreamer 벤치마크에서 3D 일관성과 충실도를 크게 향상시킵니다.
- COLMAP 기반 지표에서 3DFuse가 벤치마크 SJC 방법보다 3D 불일치 분산이 작습니다(0.0499 대 0.0870).
- 사용자 연구(102명)에서 3D 응집성, 프롬프트 준수 및 전반적 품질 측면에서 3DFuse 강화 결과를 선호합니다.
- 시맨틱 코딩은 시점에 따른 의미적 및 기하학적 불일치를 축소합니다.
- LoRA 기반 미세 조정은 확산 모델의 무거운 수정 없이 의미적 일관성을 추가로 개선합니다.
- 질적 결과가 MCC 기반 3D priors에서도 강건함을 확인합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.