[논문 리뷰] Liger Kernel: Efficient Triton Kernels for LLM Training
Liger-Kernel은 LLM 학습을 위한 Triton 커널의 오픈 소스 라이브러리로, 커널 융합과 입력 청크화를 사용하여 HuggingFace 구현에 비해 처리량을 높이고 GPU 메모리 사용량을 줄입니다. 모듈식 API, 프레임워크와의 쉬운 통합, 다수 모델에 대한 벤치마크를 제공합니다.
Training Large Language Models (LLMs) efficiently at scale presents a formidable challenge, driven by their ever-increasing computational demands and the need for enhanced performance. In this work, we introduce Liger-Kernel, an open-sourced set of Triton kernels developed specifically for LLM training. With kernel optimization techniques like kernel operation fusing and input chunking, our kernels achieve on average a 20% increase in training throughput and a 60% reduction in GPU memory usage for popular LLMs compared to HuggingFace implementations. In addition, Liger-Kernel is designed with modularity, accessibility, and adaptability in mind, catering to both casual and expert users. Comprehensive benchmarks and integration tests are built in to ensure compatibility, performance, correctness, and convergence across diverse computing environments and model architectures. The source code is available under a permissive license at: github.com/linkedin/Liger-Kernel.
연구 동기 및 목표
- LLM 학습 효율성을 향상시키기 위한 커널 수준 최적화의 필요성을 동기 부여한다.
- Liger-Kernel을 LLM용으로 모듈식이며 사용하기 쉬운 Triton 커널 라이브러리로 소개한다.
- 커널 융합과 입력 청크화가 메모리를 줄이고 처리량을 증가시키는 방법을 보여준다.
- 인기 프레임워크 및 배포 환경과의 호환성을 입증한다.
- 정합성 및 수렴을 보장하기 위한 벤치마크와 통합 테스트를 제공한다.
제안 방법
- 공통 연산의 융합에 중점을 둔 LLM 학습용 Triton 커널 라이브러리를 제안한다.
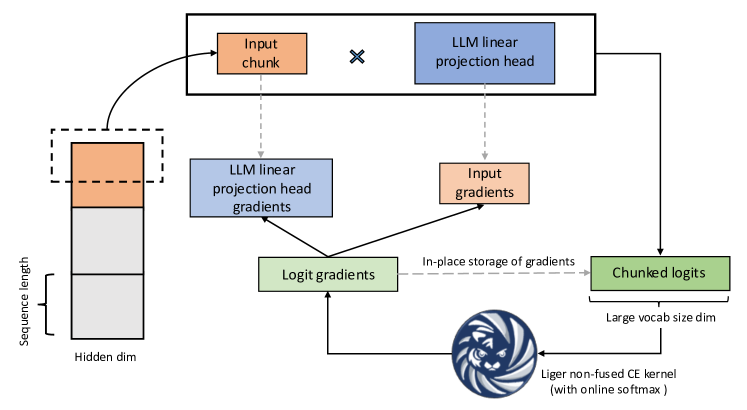
- RMSNorm, LayerNorm, RoPE, SwiGLU, GeGLU, CrossEntropy 및 융합된 Linear+CrossEntropy (FLCE) 접근법에 대한 커널 설계를 설명한다.
- AutoLigerKernelForCausalLM, 모델별 패칭 API, 그리고 맞춤 커널의 구성 등을 지원하는 API 설계를 설명한다.
- 대형 어휘의 로짓 계산 시 메모리를 감소시키는 청크된 FLCE 접근법을 제시한다.
- 정합성, 성능, 수렴성을 위한 테스트 모범 사례를 자세히 다루며 연속성(contiguity)과 대차원 처리 등을 포함한다.
- Hugging Face 및 기타 프레임워크와의 엔드투엔드 벤치마킹 설정과 통합을 요약한다.
실험 결과
연구 질문
- RQ1Liger-Kernel 커널이 기본 HuggingFace 구현 대비 학습 처리량을 개선하고 GPU 메모리를 줄일 수 있는가?
- RQ2커널 융합과 입력 청크화가 일반적인 LLM 연산에서 메모리 사용량과 속도에 어떻게 영향을 미치는가?
- RQ3Liger 커널을 사용할 때 PyTorch FSDP, DeepSpeed ZeRO, ZeRO++와의 통합이 수렴성과 정합성을 유지하는가?
- RQ4Liger-Kernel의 API 설계가 초보자와 고급 사용자 모두에게 접근하기 쉽고 여전히 높은 구성 가능성을 제공하는가?
- RQ5표준 벤치마크에서 다수의 LLM(LLaMA, Qwen, Gemma, Mistral, Phi3 등)에 대한 엔드투엔드 성능 향상은 어느 정도인가?
주요 결과
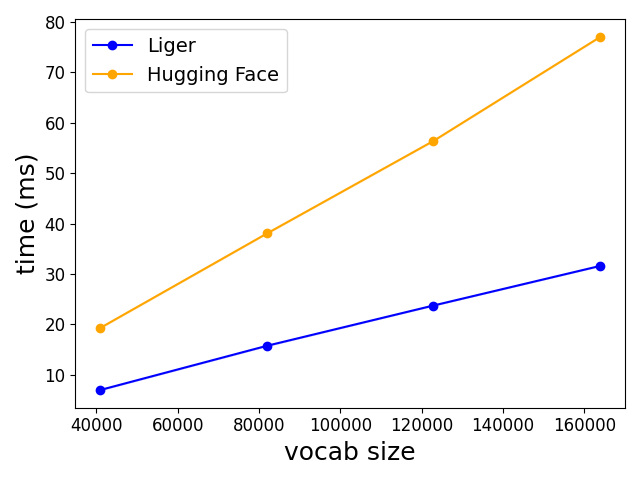
- Liger-Kernel은 HuggingFace 구현 대비 평균 약 20%의 학습 처리량 증가와 GPU 메모리 감소 60%를 달성한다.
- 온라인 소프트맥스와 제자리(인플레이스) 그래디언트 치환을 갖춘 CrossEntropy 커널은 대형 어휘 크기에서 약 3배의 속도 증가와 약 5배의 메모리 감소를 달성한다.
- RMSNorm 및 LayerNorm 커널은 정규화를 스케일링 및 캐싱과 융합하여 계산 시간을 각각 최대 약 7배 및 약 30% 감소시키며 메모리 영향은 보통이다.
- RoPE 커널은 flattened, 반복 블록 회전 행렬을 사용하여 효율을 높이고 큰 숨김 크기에서 약 8배의 속도 증가와 약 3배의 메모리 절감을 달성한다.
- GeGLU 및 SwiGLU 커널은 베이스라인과 속도 동등성을 유지하면서 긴 시퀀스에서 피크 메모리를 약 1.6배 감소시킨다.
- 엔드투엔드 벤치마크는 모델 전반에 걸쳐 실질적인 개선을 보이며: LLaMA 3-8B 처리량 +42.8% 및 메모리 -54.8%; Qwen2 처리량 +25.5% 및 메모리 -56.8%; Gemma 처리량 +11.9% 및 메모리 -51.8%; Mistral 처리량 +27% 및 메모리 -21%; Phi3 처리량 +17% 및 메모리 -13%.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.