[논문 리뷰] LIMA: Less Is More for Alignment
65B LLaMa 모델을 1,000개의 신중하게 선별된 프롬프트/응답으로 미세조정(no RLHF)을 수행하면 강력한 정렬(정합성)을 달성하며, 인간 평가에서 종종 베이스라인에 필적하거나 이를 능가하고, 사전 학습이 작은 수준의 지시 튜닝을 넘어서 우위를 차지함을 시사한다.
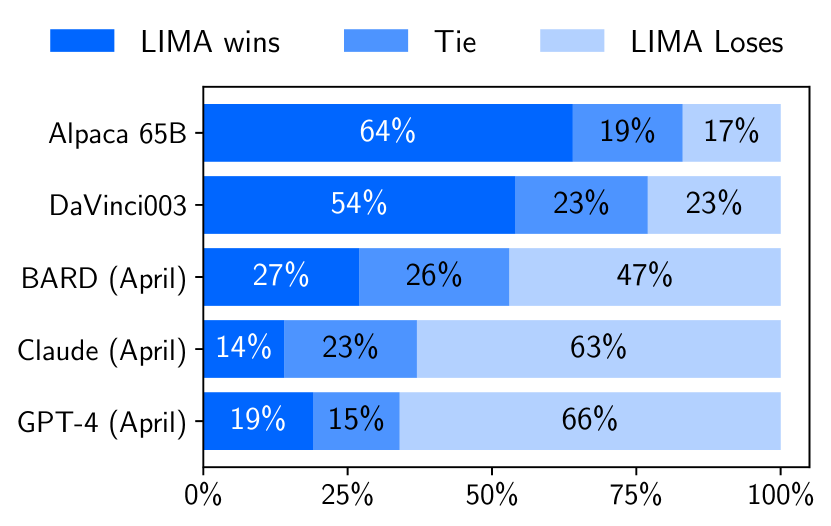
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
연구 동기 및 목표
- 강력한 사전 학습 언어 모델을 RLHF나 인간 선호도 모델링 없이 단 1,000개의 고품질 시연만으로도 효과적으로 정렬할 수 있음을 증명한다.
- LIMA를 최첨단 기준선과 비교 평가하여 정렬이 주로 사전학습에 의존하는지 아니면 지시 튜닝에 의존하는지 확인한다.
- 정렬 데이터에서 데이터 다양성과 품질 대 양에 대한 관계를 조사하고 다중 턴 대화 능력을 평가한다.
제안 방법
- 표준 감독 학습 손실을 사용하여 1,000개의 시연(커뮤니티 소스에서 750개, 수동으로 작성된 250개)을 대상으로 65B 매개변수 LLaMa 모델(LLaMa-65B)을 미세조정한다.
- 미세조정 중 사용자/도우미 차례를 구별하기 위해 특별한 엔드-오브-턴 토큰을 도입한다.
- 사람 선호도와 GPT-4+ 주석자 실험에서 300개 프롬프트에 걸쳐 LIMA를 RLHF으로 튜닝된 baselines 및 기타 기준선과 비교한다.
- 각 요소의 효과를 고립하기 위해 데이터 다양성, 품질 및 양에 대한 소거 실험을 7B 모델을 사용하여 각 요인의 효과를 분리해 분석한다.
- 제로샷 및 보강된 대화 체인 확장을 통해 다중 턴 대화 능력을 평가한다.
- 안전 관련 프롬프트 세트를 소량 사용하여 안전 동작을 평가하고 실패 모드를 분석한다.

실험 결과
연구 질문
- RQ1RLHF나 선호도 모델링 없이 단 1,000개의 시연으로도 미리 학습된 LLM을 효과적으로 정렬할 수 있는가?
- RQ2데이터 다양성과 품질이 순수한 양에 비해 정렬 성능에 어떤 영향을 미치는가?
- RQ3선별된 대화 데이터의 극소량이 다중 턴 대화 능력을 어느 정도까지 향상시키는가?
- RQ4LIMA가 인간 평가 및 GPT-4 기반 평가에서 최첨단 정렬 모델과 어떻게 비교되는가?
주요 결과
- LIMA는 인간 평가 및 GPT-4 주석자 평가에서 DaVinci003 및 Alpaca에 대해 경쟁력 있는 성능을 보인다.
- LIMA 출력의 절대 품질 평가에서 절반이 우수로 평가된다.
- 데이터 양만 늘리는 경우 프롬프트 다양성과 데이터 품질의 증가 없이 점진적 수익 감소를 보인다.
- 30개의 수작업으로 작성된 대화 체인을 추가하면 다중 턴 대화 품질이 크게 향상된다(45.2%에서 76.1% 우수로).
- LIMA의 일관된 다중 턴 대화는 대화 데이터 없이도 나타나지만, 품질은 표적 대화 보강으로 증가한다.
- 안전 프롬프트에서 LIMA는 학습에 안전 중심의 소수 부분이 포함된 경우 80%의 사례에서 안전하게 응답한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.