[논문 리뷰] Limitations of the LLM-as-a-Judge Approach for Evaluating LLM Outputs in Expert Knowledge Tasks
이 논문은 식단학 및 정신 건강 분야의 도메인 특화 과제에서 LLM을 판단자로 평가하고 SME-LLM 합의가 제한적임을 발견하여 지속적인 SME 참여를 권고합니다.
The potential of using Large Language Models (LLMs) themselves to evaluate LLM outputs offers a promising method for assessing model performance across various contexts. Previous research indicates that LLM-as-a-judge exhibits a strong correlation with human judges in the context of general instruction following. However, for instructions that require specialized knowledge, the validity of using LLMs as judges remains uncertain. In our study, we applied a mixed-methods approach, conducting pairwise comparisons in which both subject matter experts (SMEs) and LLMs evaluated outputs from domain-specific tasks. We focused on two distinct fields: dietetics, with registered dietitian experts, and mental health, with clinical psychologist experts. Our results showed that SMEs agreed with LLM judges 68% of the time in the dietetics domain and 64% in mental health when evaluating overall preference. Additionally, the results indicated variations in SME-LLM agreement across domain-specific aspect questions. Our findings emphasize the importance of keeping human experts in the evaluation process, as LLMs alone may not provide the depth of understanding required for complex, knowledge specific tasks. We also explore the implications of LLM evaluations across different domains and discuss how these insights can inform the design of evaluation workflows that ensure better alignment between human experts and LLMs in interactive systems.
연구 동기 및 목표
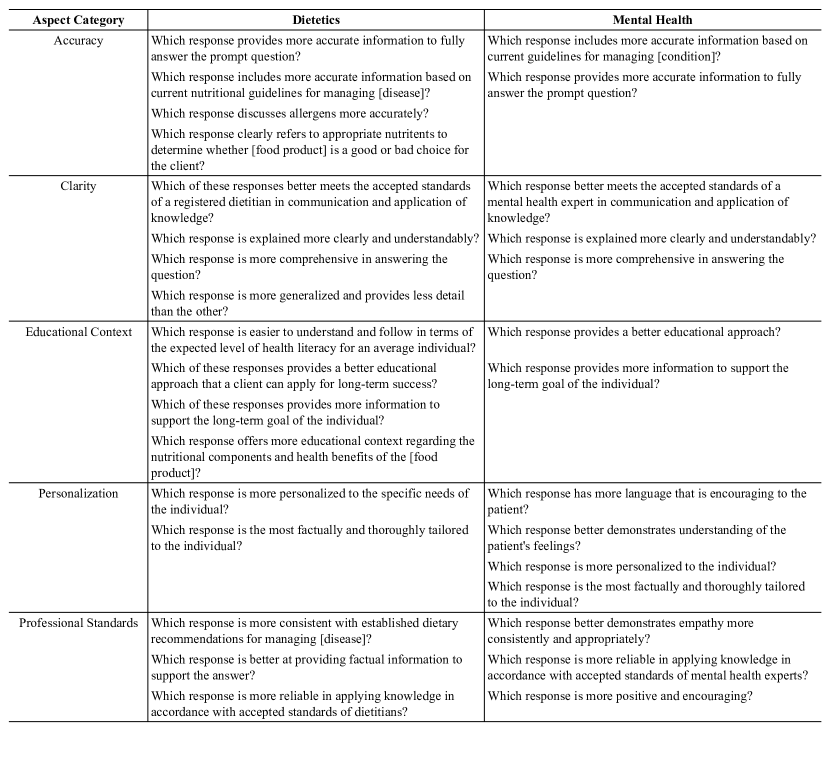
- 도메인 특화된 전문 지식 과제에서 LLM 기반 평가가 주제 전문의(SME) 판단과 어떻게 일치하는지 평가한다.
- 식단학 및 정신 건강 도메인 전반에서 SME와 LLM 판단 사이의 일치/불일치에 영향을 미치는 요인을 조사한다.
- 전문가 페르소나가 LLM 판단과 SME 간의 일치에 어떤 영향을 미치는지 살펴본다.
- SME와 LLM 양측의 질적 설명을 분석하여 평가 차이를 이해한다.
제안 방법
- 식단학 및 정신 건강에 대한 도메인 특화 지시사항 25개를 선별했다.
- 지시당 2개의 모델 출력물을 SME와 LLM 판단자에 의한 쌍대 평가로 비교한다.
- 일치도에 대한 영향를 테스트하기 위해 전문가 페르소나 프롬프트를 사용한다.
- 설명과 함께 LLM 기반 순위를 위한 AlpacaEval 프레임워크를 적용한다.
- 순위 설명에 대한 반성적 주제 분석을 수행하여 주제를 식별한다.
실험 결과
연구 질문
- RQ1RQ1: 도메인 특화 과제에 대해 LLM-판단자 평가가 SME 평가와 어떻게 비교되는가?
- RQ2RQ2: LLM과 SME 간 평가 차이와 설명에 기여하는 요인은 무엇인가?
주요 결과
| 질문 유형 | Dietetics (General Model) | Dietetics (Expert Persona) | Mental Health (General Model) | Mental Health (Expert Persona) |
|---|---|---|---|---|
| Clarity | 55% | 60% | 70% | 40% |
| Accuracy | 56% | 67% | 80% | 80% |
| Professional Standards | 80% | 80% | 64% | 73% |
| Education Context | 55% | 45% | 60% | 70% |
| Personalization | 56% | 44% | 67% | 67% |
| General Preference | 64% | 68% | 60% | 64% |
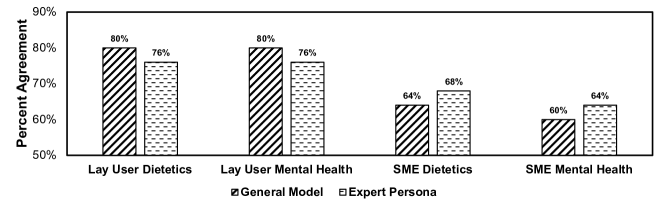
- 식단학에서 SME는 LLM 판단자와 68%, 정신 건강에서 64%의 전반적 선호도에 동의했다.
- SMEs 간의 동의율은 정신 건강 72%, 식단학 75%이다.
- 전문가 페르소나 프롬프트가 일반 선호도에서 SME–LLM 일치를 약 4% 향상시켰다.
- 일치는 도메인 특화 측면에 따라 달랐으며, 여러 범주에서 정신 건강이 식단학보다 일반적으로 더 높은 편이었다.
- SMEs는 정확성, 최신 증거, 전문 표준, 명확한 소통을 우선시했고; LLM은 종종 지시 이행과 세부사항을 강조했다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.