QUICK REVIEW
[논문 리뷰] LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril|arXiv (Cornell University)|2023. 02. 27.
Natural Language Processing Techniques인용 수 3,849
한 줄 요약
LLaMA는 7B에서 65B 파라미터의 공개 데이터로 학습된 기초 언어 모델을 제시하며, 더 큰 폐쇄형 모델과 경쟁력 있는 성능을 달성하고 보통의 하드웨어에서 추론이 가능하다.
ABSTRACT
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
연구 동기 및 목표
- 공개 데이터만을 사용하여 LLM 연구에 대한 접근성을 민주화한다.
- 특정 학습/추론 예산에서 더 작은 모델이 더 큰 모델을 능가할 수 있음을 시연한다.
- 표준 벤치마크에서 13B–65B 모델의 경쟁력 있는 성능을 최고의 모델들과 비교하여 보인다.
- 연구자들을 위한 학습/추론 효율성과 실용적 배포 고려사항을 강조한다.
제안 방법
- 사전 정규화(pre-normalization), SwiGLU 활성화 및 RoPE 로터리 임베딩이 있는 트랜스포머 기반 아키텍처를 활용한다.
- 약 1.0–1.4조 토큰에서 코사인 학습률 스케줄과 AdamW 옵티마이저로 7B, 13B, 33B, 65B 등 여러 모델 크기를 학습한다.
- 메모리 효율적인 인과(attention) 구현과 체크포인팅을 사용하여 대형 GPU에서 학습 속도를 높인다.
- 공개적으로 이용 가능한 데이터셋(CommonCrawl, C4, GitHub, Wikipedia, Books, ArXiv, Stack Exchange)을 혼합한 데이터로 사전학습하며, 중복 제거와 언어 필터링을 신중히 수행한다.
- SentencePiece를 통한 BPE로 토크나이즈하고, 광범위한 커버리지를 위해 숫자 분할 및 UTF-8 대체를 포함한다.
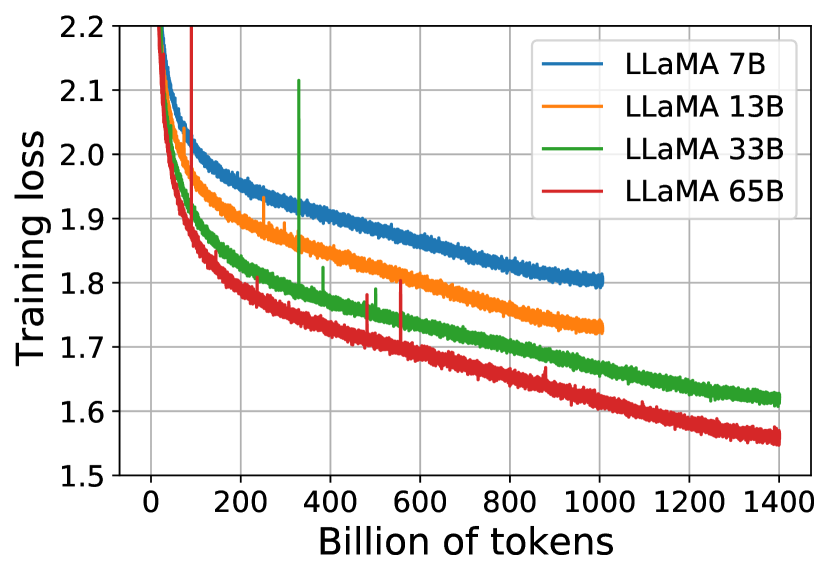
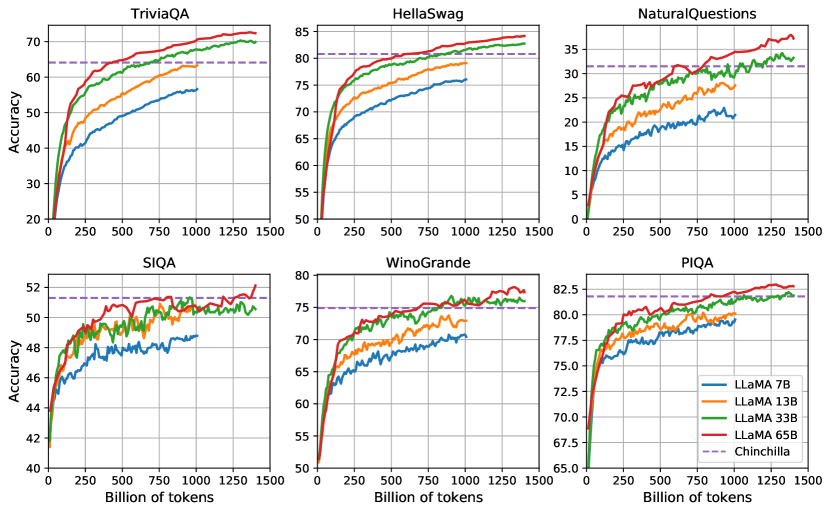
실험 결과
연구 질문
- RQ1공개적으로 수집된 공개 데이터로 7B–65B 규모의 다중 스케일에서 고품질의 기초 모델을 학습시킬 수 있는가?
- RQ2다양한 추론 예산 하에서 작은 공개 모델이 표준 벤치마크에서 더 큰 독점 모델에 비해 어떻게 성능을 보이는가?
- RQ3대형 언어 모델의 강력한 성능과 실용적 추론 효율성을 얻기 위한 어떤 아키텍처 및 학습 최적화가 있는가?
- RQ4광범위한 맞춤 데이터 없이도 지시어 미세조정(instruction-finetuning)이 오픈 모델의 작업 성능을 얼마나 향상시킬 수 있는가?
- RQ5공개 데이터로 학습된 개방형 기초 모델의 편향성, 독성 발현 및 탄소 발자국 영향은 무엇인가?
주요 결과
- LLaMA-13B는 대부분의 벤치마크에서 175B의 GPT-3를 능가하지만 크기는 10배 작다.
- LLaMA-65B는 여러 평가에서 최상위 모델들(Chinchilla-70B 및 PaLM-540B)과 경쟁력이 있다.
- LLaMA-65B는 Natural Questions와 TriviaQA에서 제로/휼샷 설정에서 강한 성능을 보이며, 65B가 일부 작업에서 최신 연구 수준과 유사한 결과를 달성한다.
- 코드 생성 능력(HumanEval, MBPP)은 코드-튜닝이 없는 여러 베이스라인보다 LLaMA가 우수하게 나타나며, 파라미터 수가 많아질수록 더 큰 이점을 보인다.
- 지시어 미세조정(LLaMA-I)은 MMLU 성능을 향상시키며 65B에서 68.9%에 도달해, 같은 규모의 다른 지시어 미세조정 모델 중 일부를 능가한다.
- 본 연구는 편향성 및 독성 패턴(RealToxicityPrompts, CrowS-Pairs, WinoGender)을 문서화하고 GPT-3 및 OPT와의 비교를 제공하며 크기 관련 경향과 영역별 편향을 언급한다.
- 공통 데이터 센터 맥락에서 서로 다른 모델을 학습할 때의 탄소 발자국에 대한 상세한 분석을 제시하며, 상당한 에너지 사용과 향후 배출 감소를 위한 개방성 의도를 강조한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.