[논문 리뷰] LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
본 논문은 LLM-Adapters라는 프레임워크를 제시하여 PEFT 어댑터를 오픈 소스 LLM에 통합하고, 수학 및 일반상식 추론 과제에서 어댑터 유형, 배치(placements), 하이퍼파라미터를 실증적으로 연구하며, 어댑터를 갖춘 더 작은 모델이 특정 설정에서 대형 모델과 맞먹거나 더 나아질 수 있음을 보여준다.
The success of large language models (LLMs), like GPT-4 and ChatGPT, has led to the development of numerous cost-effective and accessible alternatives that are created by finetuning open-access LLMs with task-specific data (e.g., ChatDoctor) or instruction data (e.g., Alpaca). Among the various fine-tuning methods, adapter-based parameter-efficient fine-tuning (PEFT) is undoubtedly one of the most attractive topics, as it only requires fine-tuning a few external parameters instead of the entire LLMs while achieving comparable or even better performance. To enable further research on PEFT methods of LLMs, this paper presents LLM-Adapters, an easy-to-use framework that integrates various adapters into LLMs and can execute these adapter-based PEFT methods of LLMs for different tasks. The framework includes state-of-the-art open-access LLMs such as LLaMA, BLOOM, and GPT-J, as well as widely used adapters such as Series adapters, Parallel adapter, Prompt-based learning and Reparametrization-based methods. Moreover, we conduct extensive empirical studies on the impact of adapter types, placement locations, and hyper-parameters to the best design for each adapter-based methods. We evaluate the effectiveness of the adapters on fourteen datasets from two different reasoning tasks, Arithmetic Reasoning and Commonsense Reasoning. The results demonstrate that using adapter-based PEFT in smaller-scale LLMs (7B) with few extra trainable parameters yields comparable, and in some cases superior, performance to powerful LLMs (175B) in zero-shot inference on both reasoning tasks.
연구 동기 및 목표
- 다양한 어댑터를 하나의 프레임워크에 통합하여 LLM에서 PEFT를 가능하게 하고 활성화한다.
- 작업과 모델 전반에 걸친 최적의 어댑터 배치 및 구성을 조사한다.
- 오픈 소스 LLM을 사용한 수학 추론 및 일반상식 추론 데이터셋에서 어댑터 기반 PEFT를 평가한다.
제안 방법
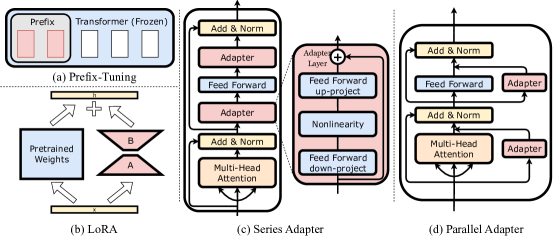
- Prefix-Tuning, Series Adapter, LoRA, Parallel Adapter를 LLM에 통합하는 LLM-Adapter 프레임워크를 개발한다.
- Series, Parallel, LoRA 어댑터의 최적 위치를 식별하기 위한 배치 실험을 수행한다.
- 하이퍼파라미터(vt: Prefix-Tuning용; bn: Series/Parallel 어댑터용; r: LoRA용)을 조정하여 최적 설정을 찾는다.
- 교사-생성 합리적 추론과 작업 템플릿을 사용하여 Math10K와 Commonsense170K 미세조정 데이터셋을 생성한다.
- 선정된 PEFT 방법으로 7B/13B 오픈 LLM(LLaMA, BLOOMz, GPT-J)을 미세조정하고 산술 및 일반상식 추론에 걸친 14개 데이터셋에서 평가한다.
- GPT-3.5 (175B) 및 ChatGPT를 포함한 베이스라인과 PEFT 결과를 비교한다.
실험 결과
연구 질문
- RQ1다양한 PEFT 방법의 최적 배치 및 구성은 무엇인가?
- RQ2다양한 어댑터가 다운스트림 과제에서 어떻게 성능을 발휘하는가?
- RQ3PEFT 방법의 인-디스트리션(in-distribution)과 아웃-오브-디스트리뷰션(out-of-distribution) 시나리오 간 성능 차이는 무엇인가?
주요 결과
- 최적의 배치: Series Adapter는 MLP 층 뒤에; Parallel Adapter는 MLP 층 내에; LoRA는 Attention과 MLP 층 모두 뒤에 배치한다.
- PEFT를 사용하는 더 작은 LLM이 간단한 수학 과제에서 더 큰 모델보다 우수한 성능을 보일 수 있다(예: MultiArith, AddSub, SingleEq에서 LoRA를 적용한 LLaMA-13B vs GPT-3.5).
- LLaMA-13B에 LoRA를 적용하면 여섯 개 수학 데이터셋에서 평균 65.4%를 달성하여 해당 과제에서 GPT-3.5의 성능에 근접(약 92.8% 수준)합니다.
- 일반상식 추론에서 Series/Parallel/LoRA 어댑터를 갖춘 LLaMA-13B가 베이스라인을 능가하고, Parallel가 평균 81.5%로 차별화되며 ChatGPT보다 약 4.5% 포인트 높다.
- LLaMA-13B의 세 가지 어댑터 모두 Commonsense170K에서 강력한 결과를 보이며, 세 가지 중 Parallel 어댑터의 평균(81.5%)이 가장 높다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.