[논문 리뷰] LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
SelfExtend는 미세조정 없이 추론 시 LLM의 컨텍스트 창을 확장하고, 먼 토큰에는 그룹화된 어텐션을, 가까운 토큰에는 인접 이웃 어텐션을 결합하며, 바닥 기반 relpos 매핑을 통해 이를 수행합니다.
It is well known that LLMs cannot generalize well to long contexts whose lengths are larger than the training sequence length. This poses challenges when employing LLMs for processing long input sequences during inference. In this work, we argue that LLMs themselves have inherent capabilities to handle long contexts without fine-tuning. To achieve this goal, we propose SelfExtend to extend the context window of LLMs by constructing bi-level attention information: the grouped attention and the neighbor attention. The grouped attention captures the dependencies among tokens that are far apart, while neighbor attention captures dependencies among adjacent tokens within a specified range. The two-level attentions are computed based on the original model's self-attention mechanism during inference. With minor code modification, our SelfExtend can effortlessly extend existing LLMs' context window without any fine-tuning. We conduct comprehensive experiments on multiple benchmarks and the results show that our SelfExtend can effectively extend existing LLMs' context window length. The code can be found at \url{https://github.com/datamllab/LongLM}.
연구 동기 및 목표
- LLM이 사전 학습 한계에도 불구하고 자체적으로 장기 컨텍스트 능력을 보유하고 있음을 동기 부여한다.
- 장기 맥락 추론에서 상대 위치 인코딩의 분포 외 문제를 해결한다.
- 추론 중 컨텍스트 길이를 확장하는 튜닝 없는 메커니즘을 제안한다.
- SelfExtend를 언어 모델링, 합성 장기 맥락, 실제 긴 맥락 작업에 걸쳐 평가한다.
제안 방법
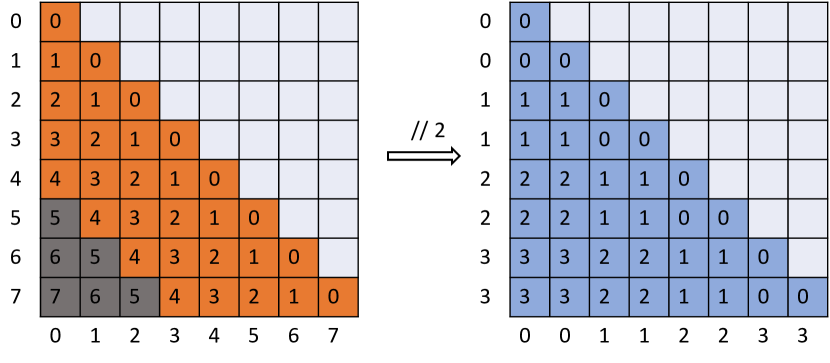
- 먼 토큰에 대한 바닥 나눗셈 위치 매핑을 적용하는 그룹화된 어텐션을 도입한다.
- 정의된 윈도우 내 이웃 토큰에 대해 표준 어텐션을 유지한다.
- 소프트맥스 이전에 그룹화된 어텐션과 이웃 어텐션을 합쳐 SelfExtend 어텐션을 형성한다.
- 미세조정이 필요 없는 그라데이션 없는 플러그인 추론 시 변경으로 제공한다.
- SelfExtend 하에서 달성 가능한 최대 길이를 정량화하는 확장 컨텍스트 길이 공식을 도출한다.
실험 결과
연구 질문
- RQ1LLM이 사전 학습을 넘어 더 긴 컨텍스트를 본래의 미세조정 없이 처리할 수 있는가?
- RQ2보지 못한 큰 상대 위치를 알려진 위치로 매핑하여 일관성을 유지할 수 있는가?
- RQ3SelfExtend가 짧은 맥락 성능 저하 없이 여러 모델과 작업에서 장기 맥락 성능을 개선하는가?
주요 결과
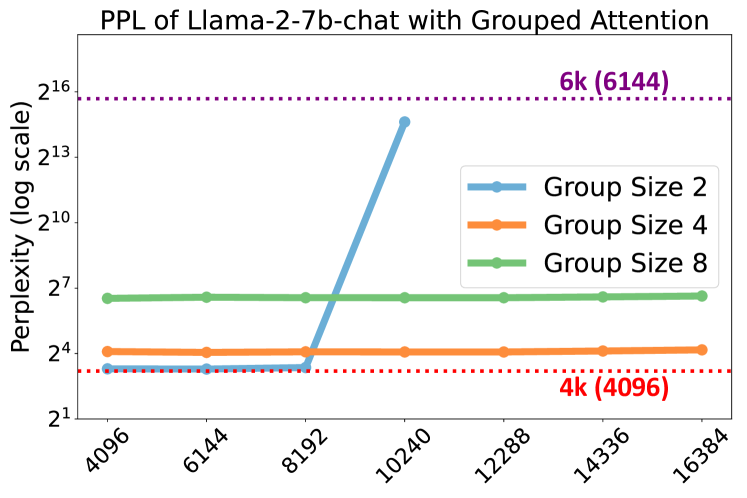
- 그룹화된 어텐션을 사용할 때 SelfExtend가 사전 학습 컨텍스트 창을 넘어도 낮은 당황도(perplexity)를 유지한다.
- 패스키 검색 작업은 깊이와 컨텍스트에 관계없이 SelfExtend를 사용하면 100% 정확도를 보여줘 진정한 장기 맥락 접근을 시사한다.
- 실세계 장기 맥락 벤치마크에서 SelfExtend는 튜닝 기반 확장과 경쟁력 있거나 우수한 결과를 보인다.
- SelfExtend는 짧은 맥락 작업 성능을 보존하면서 긴 맥락 기능을 향상시키고 학습 없이 플러그인 형태로 채택 가능하다.
- 다양한 모델(Llama-2, Mistral, SOLAR, Phi-2)을 아우르는 실험에서 방법의 폭넓은 적용 가능성을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.