[논문 리뷰] LoRA+: Efficient Low Rank Adaptation of Large Models
LoRA+는 어댑터 행렬에 비대칭 학습률을 사용하여 저랭크 적응을 개선하고, 1-2% 성능 향상을 달성하며 추가 계산 비용 없이 미세조정이 최대 약 2배 빨라진다.
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $\%$ improvements) and finetuning speed (up to $\sim$ 2X SpeedUp), at the same computational cost as LoRA.
연구 동기 및 목표
- 표준 LoRA의 A 및 B 어댑터에 대해 동일한 학습률로 인해 넓은 모델의 서브최적 미세조정을 유발한다는 점을 동기화하고 진단한다.
- 무한 너비 스케일링 가정에 기초하여 LoRA 어댑터 A와 B 사이의 고정된 비율로 학습률 스케일링을 제안한다.
- 언어 모델과 태스크 전반에 걸친 미세조정 성능 및 속도 개선을 입증한다.
- 실세계 설정에서 LoRA+의 비율과 작동 모드를 선택하기 위한 실용적 가이드라인을 제공한다.
제안 방법
- W = W* + (alpha/r) B A 와 같이 표준 LoRA에서 도입하고 무한 너비 한계에서 학습 다이나믹스를 분석한다.
- A와 B에 동일한 학습률을 사용하는 것은 넓은 모델에 비해 비최적임을 보이고 eta_A = Theta(n^{-1}) 및 eta_B = Theta(1)인 고정 비율을 도출한다.
- 네트워크 너비를 기반으로 안정적이고 효율적인 특징 학습을 보장하기 위한 이론적 스케일링 근거를 개발한다(Delta f_t = Theta(1)).
- 토이 선형/비선형 모델과 언어 모델 미세조정에 대한 광범위한 실험으로 이론을 검증한다.
- 표준 LoRA와 비교하여 같은 계산 비용에서 성능(1-2%) 및 미세조정 속도(최대 약 2배)의 개선을 보고한다.
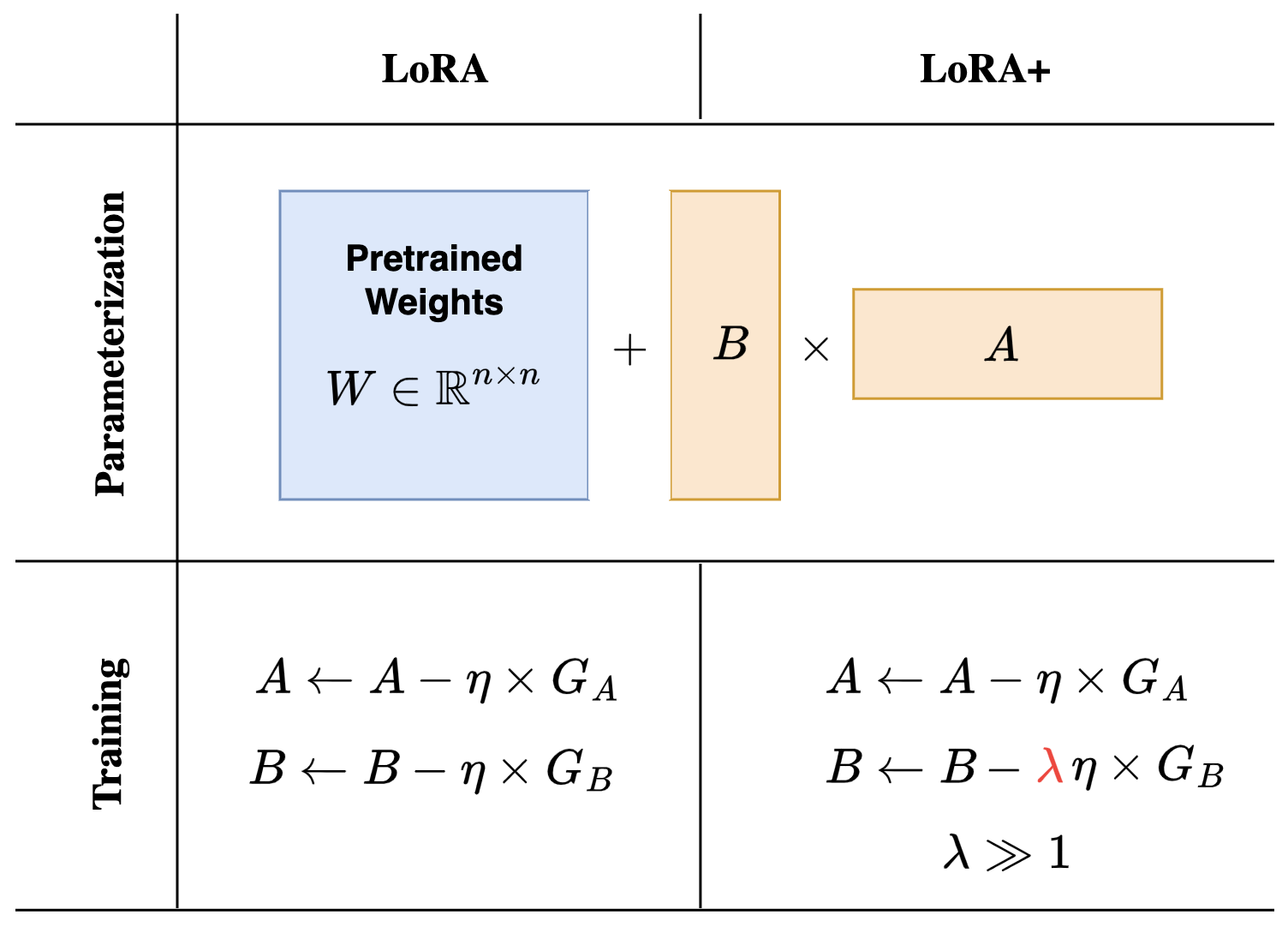
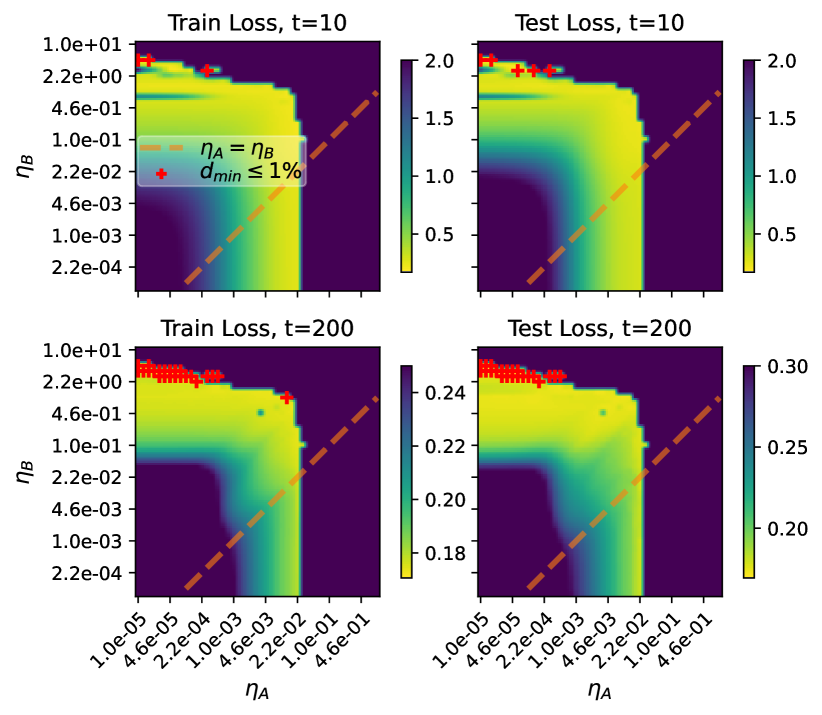
실험 결과
연구 질문
- RQ1LoRA 어댑터 A와 B에 대해 동일한 학습률이 모델 폭이 커질수록 특징 학습에 방해가 되는가?
- RQ2무한width 영역에서 eta_A와 eta_B의 학습률 간 원리적 비율이 효율적인 미세조정을 회복할 수 있는가?
- RQ3제안된 스케일링 규칙이 언어 모델과 태스크 전반에서 실제 미세조정 성능과 속도를 향상시키는가?
- RQ4실세계 설정에서 eta_B/eta_A의 고정 비율을 선택하기 위한 가이드는 무엇인가?
주요 결과
- 동일 학습률을 가진 표준 LoRA는 넓은 모델에 비효율적이다.
- eta_A = Theta(n^{-1}) 및 eta_B = Theta(1)인 원리적 설정은 안정적이고 효율적인 LoRA 미세조정을 가능하게 한다(Delta Z_B^t = Theta(1)).
- LoRA+는 같은 계산 비용에서 성능 1-2% 향상 및 최대 2배의 미세조정 속도 향상을 달성한다.
- 토이 및 신경망 실험은 eta_B >> eta_A가 일반적으로 거의 최적의 손실과 안정적 특징 학습을 가져옴을 뒷받침한다.
- 이 방법은 효율성을 유지하면서 하이퍼파라미터 튜닝을 단순화하기 위해 고정 eta_B/eta_A 비율을 선택하는 가이드를 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.