[논문 리뷰] Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Magnetic-One은 오케스트레이터에 의해 조정되는 오픈 소스 일반ist 멀티 에이전트 시스템으로, 전문 에이전트에 작업을 분담하고 오류를 회복하며 GAIA, AssistantBench, WebArena 벤치마크에서 경쟁력 있는 성능을 달성합니다. 또한 엄격한 에이전트 평가를 위한 AutoGenBench를 도입합니다.
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
연구 동기 및 목표
- 다양한 도메인에서 복잡한 task를 해결할 수 있는 일반ist 에이전트 시스템 개발 동기를 제시합니다.
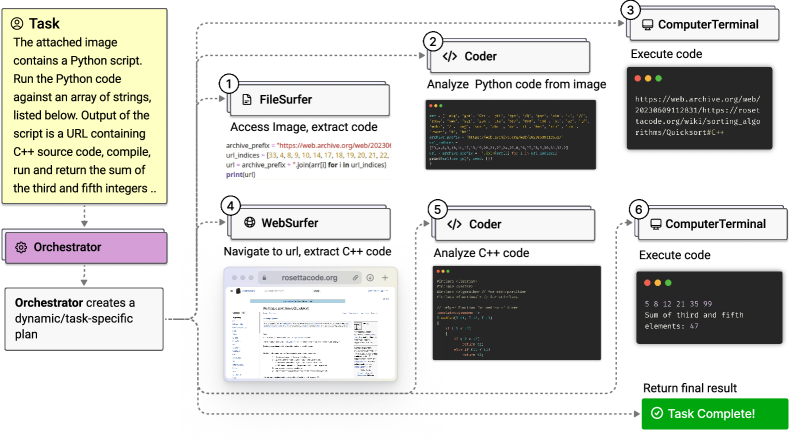
- 오케스트레이터가 전문 에이전트(WebSurfer, FileSurfer, Coder, ComputerTerminal)를 조정하는 모듈식 멀티 에이전트 아키텍처를 제안합니다.
- stateful 환경에서 에이전트 시스템을 엄격하고 재현 가능한 평가를 위한 AutoGenBench를 소개합니다.
- 모듈식 멀티 에이전트 구성이 핵심 아키텍처 변경 없이도 다수 벤치마크에서 최첨단 성능에 근접할 수 있음을 Demonstrate합니다.
- 에이전트 확장성, 에이전트 추가/제거의 용이성, 향후 시나리오 적응 가능성을 강조합니다.
제안 방법
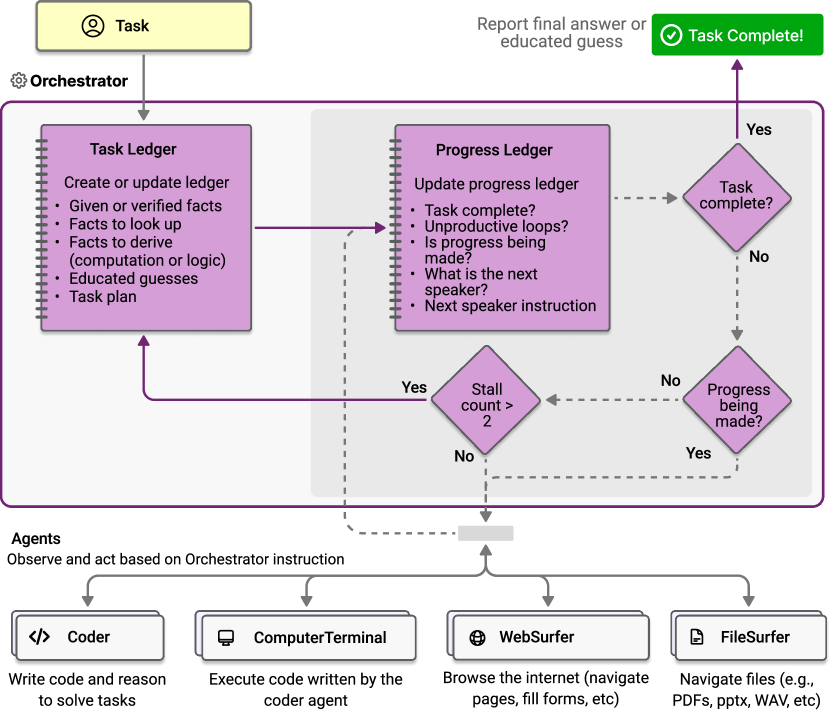
- Magnetic-One의 이중 루프 오케스트레이션을 제안합니다: 외부 루프는 작업 원장을 유지(plan, facts, educated guesses)을, 내부 루프는 진행 원장을 유지(task assignments and progress tracking)을 수행합니다.
- 오케스트레이터를 사용하여 단계별 계획을 생성하고 전문 에이전트에게 하위 작업을 할당하며, 정지 또는 오류에서 회복하기 위한 재설정/재계획을 수행합니다.
- 공유 제어 흐름 아래에서 브라우저/웹 작업용 WebSurfer, 파일 상호작용용 FileSurfer, 코드/산출물 생성용 Coder, 코드 실행용 ComputerTerminal로 구성된 전문 에이전트 팀을 배치합니다.
- 정지 시 복구를 가능하게 하는 카운터 기반의 내부 루프와 반성 단계(reflection step)로 제한적 오류 복구를 가능하게 합니다.
- 외부에서 독립적으로 제어되는 평가 프레임워크로 AutoGenBench를 도입하여 에이전트 시스템에 대한 고립되고 재현 가능한 벤치마킹을 보장합니다.
- 세 가지 벤치마크(GAIA, AssistantBench, WebArena)에서 평가하며, 오픈 소스 구현 및 변형 분석을 제공합니다.
실험 결과
연구 질문
- RQ1Magentic-One이 다양한 에이전트 기반 벤치마크(GAIA, AssistantBench, WebArena)에서 경쟁력 있는 작업 완료율이나 정확도를 달성할 수 있는가?
- RQ2모듈식 멀티 에이전트 설계(오케스트레이터와 전문 에이전트)가 프롬프트 학습이나 핵심 아키텍처 변경 없이 성능과 일반화에 어떻게 기여하는가?
- RQ3평가 프레임워크(AutoGenBench)가 재현성, 안전성, 에이전트 작업의 편차에 미치는 영향은 무엇인가?
- RQ4각 에이전트의 개별 기여도는 전체 성능에 어떤 영향을 주며 주요 실패 모드는 어디에 있는가?
- RQ5기존의 LLM 변동(GPT-4o 대 o1-preview 등)에서 시스템의 성능이 유지되는가?
주요 결과
| 방법 | GAIA | AssistantBench (EM) | AssistantBench (정확도) | WebArena |
|---|---|---|---|---|
| ;; omne v0.1 (GPT-4o, o1) | 40.53 ± 5.6 | – | – | – |
| ;; Trase Agent v0.2 (GPT-4o, o1, Gemini) | 39.53 ± 5.5 | – | – | – |
| ;; Multi Agent (NA) | 38.87 ± 5.5 | – | – | – |
| ;; das agent v0.4 (GPT-4o) | 38.21 ± 5.5 | – | – | – |
| ;; Sibyl (GPT-4o) [56] | 34.55 ± 5.4 | – | – | – |
| ;; HF Agents (GPT-4o) | 33.33 ± 5.3 | – | – | – |
| ;; FRIDAY (GPT-4T) [61] | 24.25 ± 4.8 | – | – | – |
| ;; GPT-4 + plugins [29] | 14.60 ± 4.0 | – | – | – |
| ;; SPA -> CB (Claude) [71] | – | 13.8 ± 5.0 | 26.4 ± 6.4 | – |
| ;; SPA -> CB (GPT-4T) [71] | – | 9.9 ± 4.3 | 25.2 ± 6.3 | – |
| ;; Infogent (GPT-4o) | – | 5.5 ± 3.3 | 14.5 ± 5.1 | – |
| ;; Jace.AI (NA) | – | – | – | 57.1 ± 3.4 |
| ;; WebPilot (GPT-4o) [75] | – | – | – | 37.2 ± 3.3 |
| ;; AWM (GPT-4) [57] | – | – | – | 35.5 ± 3.3 |
| ;; SteP (GPT-4) [49] | – | – | – | 33.5 ± 3.2 |
| ;; BrowserGym (GPT-4o) [10] | – | – | – | 23.5 ± 2.9 |
| ;; GPT-4 | 6.67 ± 2.8 [29] | 6.1 ± 3.5 [71] | 16.5 ± 5.4 [71] | 14.9 ± 2.4 [79] |
| ;; Human | 92.00 ± 3.1 | – | – | 78.2 ± 2.8 |
| ;; Magentic-One (GPT-4o) | 32.33 ± 5.3 | 11.0 ± 4.6 | 25.3 ± 6.3 | 32.8 ± 3.2 |
| ;; Magentic-One (GPT-4o, o1) | 38.00 ± 5.5 | 13.3 ± 4.9 | 27.7 ± 6.5 | * |
- Magentic-One은 GAIA에서 38%, WebArena에서 32.8%, AssistantBench에서 27.7%의 작업 완료율을 달성하며 GPT-4o 및 o1 구성에서 SOTA 벤치마스에 대해 통계적으로 경쟁력 있는 성능을 보인다.
- GPT-4o만을 사용한 경우, Magentic-One은 보고된 설정에서 GAIA 32.33%, AssistantBench EM 11.0%, AssistantBench 정확도 25.3%, WebArena 32.8%를 달성합니다; GPT-4o 및 o1을 사용하면 GAIA 38.00%, AssistantBench EM 13.3%, 27.7% 정확도로 개선됩니다.
- 변형 분석은 각 에이전트의 전반적 성능에 대한 추가 가치를 시사하고 명확한 오류 모드를 드러내어 개선의 기회를 제공합니다.
- AutoGenBench는 초기 조건을 고정하고 실행 간의 고립을 보장하며 상태 유지 작업의 안전한 평가를 통해 제어되고 재현 가능한 벤치마킹을 가능하게 합니다.
- 결과는 핵심적인 에이전트 능력이나 협력 체계의 변경 없이도 웹 및 파일 기반 작업을 수행할 수 있는 일반ist 에이전트 시스템의 실현 가능성을 보여줍니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.