[논문 리뷰] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
Magpie는 pre-query 템플릿만으로 정렬된 LLM에 프롬프트를 제공하여 자율 지시 생성, 최대 4 million 개의 지시를 생성하고 300K 고품질 인스턴스를 선택하여 open-weight 모델을 미세조정합니다.
High-quality instruction data is critical for aligning large language models (LLMs). Although some models, such as Llama-3-Instruct, have open weights, their alignment data remain private, which hinders the democratization of AI. High human labor costs and a limited, predefined scope for prompting prevent existing open-source data creation methods from scaling effectively, potentially limiting the diversity and quality of public alignment datasets. Is it possible to synthesize high-quality instruction data at scale by extracting it directly from an aligned LLM? We present a self-synthesis method for generating large-scale alignment data named Magpie. Our key observation is that aligned LLMs like Llama-3-Instruct can generate a user query when we input only the left-side templates up to the position reserved for user messages, thanks to their auto-regressive nature. We use this method to prompt Llama-3-Instruct and generate 4 million instructions along with their corresponding responses. We perform a comprehensive analysis of the extracted data and select 300K high-quality instances. To compare Magpie data with other public instruction datasets, we fine-tune Llama-3-8B-Base with each dataset and evaluate the performance of the fine-tuned models. Our results indicate that in some tasks, models fine-tuned with Magpie perform comparably to the official Llama-3-8B-Instruct, despite the latter being enhanced with 10 million data points through supervised fine-tuning (SFT) and subsequent feedback learning. We also show that using Magpie solely for SFT can surpass the performance of previous public datasets utilized for both SFT and preference optimization, such as direct preference optimization with UltraFeedback. This advantage is evident on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
연구 동기 및 목표
- 사람이 작성한 데이터나 API 접근에 대한 의존도를 줄여 LLM 정렬 데이터의 민주화를 촉진한다.
- 선행 질의 템플릿(pre-query templates)을 사용하여 정렬된 LLM으로부터 직접 다양한 지시를 추출하는 자기합성(self-synthesis) 방법을 제안한다.
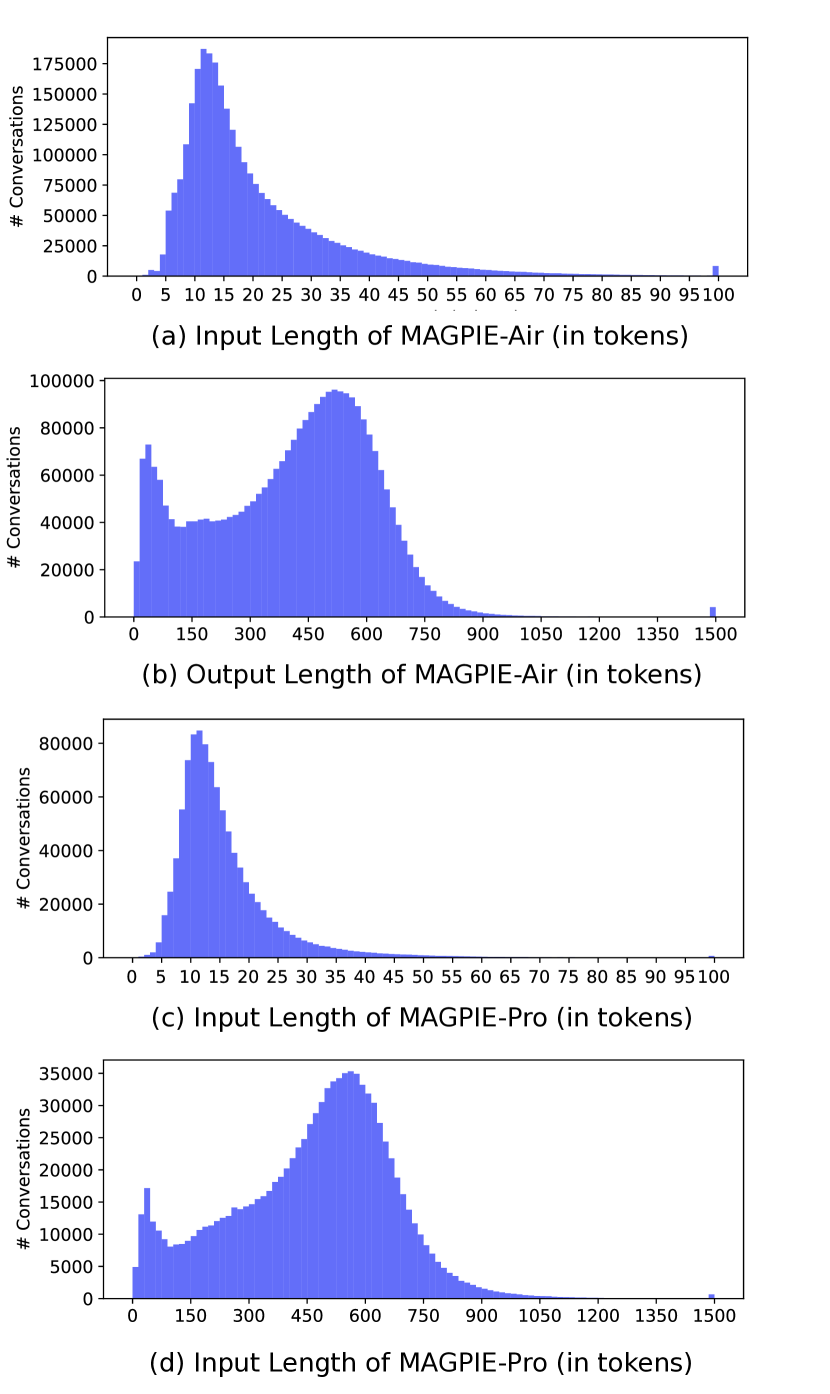
- 시드 프롬프트나 씨드를 사용하지 않고 대규모 지시 데이터셋(Magpie-Air 및 Magpie-Pro)과 다중 턴 변형을 생성한다.
- Magpie 데이터를 사용한 오픈-가중치 모델의 미세조정이 기준선보다 우수하고 공식 정렬 모델에 근접함을 입증한다.
제안 방법
- 사전 질의 템플릿만으로 정렬된 LLM에 프롬프트를 제공하여 자율 지시 생성(시드 질문 없음)을 유도한다.
- 정렬된 LLM의 자기회귀 특성을 이용해 end-of-sequence 토큰이 생성될 때까지 다양한 지시를 생성한다.
- 생성된 지시를 사용해 같은 LLM을 질의하여 지시-응답 쌍을 형성함으로써 응답을 생성한다.
- 사람의 개입 없이 Magpie-Air, Magpie-Pro 등 Magpie 데이터셋과 다중 턴 변형(Magpie-Air-MT, Magpie-Pro-MT)을 생성한다.
- 필터링 및 분석을 적용해 미세조정을 위한 고품질 인스턴스를 선별한다(예: 300K 고품질 하위 집합).
- Llama-3-8B-base, Qwen1.5-4B/7B 등의 오픈 가중치 모델을 미세조정하여 평가하고 정렬 벤치마크에서 평가한다.
실험 결과
연구 질문
- RQ1시드나 시드 엔지니어링 없이도 정렬된 LLM으로부터 고품질 지시 데이터를 대규모로 직접 합성할 수 있는가?
- RQ2Magpie로 생성된 데이터세트가 공개 벤치라인이나 비공개 데이터로 학습된 모델의 성능에 필적하거나 이를 능가하도록 오픈-weight 모델을 가능하게 하는가?
- RQ3Magpie 데이터의 품질, 커버리지, 안전성 특성은 무엇이며, 이것이 다운스트림 미세조정에 어떤 영향을 미치는가?
- RQ4전통적인 데이터 생성 파이프라인에 비해 Magpie가 비용 효율적이고 확장 가능한가?
주요 결과
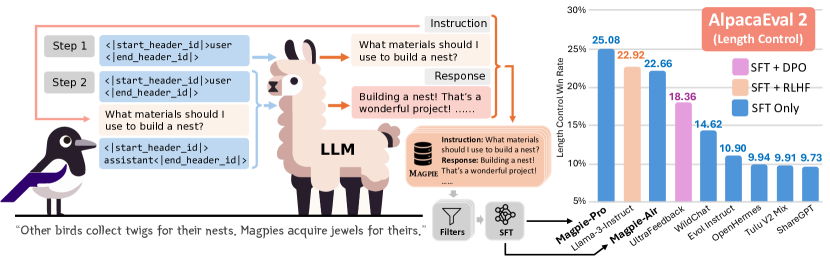
- Magpie는 약 4 million 개의 지시와 응답을 생성할 수 있으며, 효과적인 튜닝을 위한 필터링된 고품질 하위 집합은 300K이다.
- 미세조정 Llama-3-8B-base를 Magpie 데이터로 수행하면 AlpacaEval 2 및 Arena-Hard 성능이 유사 데이터 규모를 사용하는 모델 기준선보다 더 좋다.
- Magpie 데이터로 미세조정된 모델은 공식 Llama-3-8B-Instruct 모델과 견줄 수 있으며, 후자는 SFT 및 RLHF에 1천만 개가 넘는 데이터 포인트를 사용했다는 점에도 불구하고 그렇다.
- Magpie 데이터가 ShareGPT, Evol Instruct, UltraChat, OpenHermes, WildChat 등의 공개 지시 데이터셋과 선호도 튜닝의 조합을 포함한 정렬 벤치마크에서 우수성을 보인다.
- Magpie 데이터를 Qwen 기본 모델에 적용하면 공식 지시 튜닝 대응 모델을 능가하는 성능 향상을 보여준다.
- 필터링 후 Magpie는 넓은 주제 커버리지와 고품질 지시를 달성하고 안전성 위험이 낮다(<1% 잠재적으로 해로운).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.