[논문 리뷰] MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
MindEye2는 다수 피험자에 걸쳐 단일 모델을 사전학습하고 held-out 피험자 fMRI 데이터의 단 1시간으로 미세조정하여 최첨단 fMRI-to-image 재구성 및 검색을 달성하며, 공유 피험자 잠재 공간과 미세 조정된 unCLIP/SDXL 파이프라인을 사용합니다.
Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
연구 동기 및 목표
- 실용적인 fMRI-to-image 재구성에 필요한 최소한의 피험자 특이 데이터의 필요성을 제시한다.
- 다양한 뇌를 공통 잠재 공간으로 매핑하기 위한 공유-피험자 기능적 정합을 개발한다.
- fMRI를 CLIP 공간으로 매핑하고 미세 조정된 unCLIP/SDXL 모델로 이미지를 재구성하는 통합 파이프라인을 구현한다.
- 강력한 검색 및 자막 생성 능력을 높은 보존 재구성들과 함께 시연한다.
제안 방법
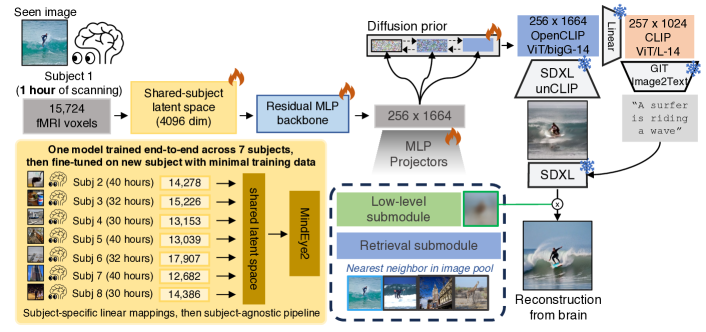
- 7명의 피험자 fMRI 데이터에 대해 단일 모델을 사전 학습한 후 held-out 8th 피험자에서 미세 조정한다.
- Voxel 반응을 4096-d 공유-피험자 잠재 공간으로 매핑하는 선형 리지 맵핑을 사용하고, 이어서 OpenCLIP ViT-bigG/14 임베딩으로 잔여 MLP 백본을 적용한다.
- fMRI 잠재를 OpenCLIP 이미지 공간으로 매핑하기 위한 확산 사전(prior)을 학습하고, 검색 서브모듈은 대조적으로 학습한다.
- 세밀한 구조를 보존하고 SDXL 재구성에 도움을 주기 위한 저수준 서브모듈을 도입한다.
- 이미지 임베딩을 텍스트 대신 수용하도록 unCLIP를 적합시키고, 자막 가이던스를 사용하여 기본 SDXL로 출력을 정제한다.
실험 결과
연구 질문
- RQ1새로운 피험자에서 아주 적은 데이터로도 공유-피험자 잠재 공간이 고품질 fMRI-to-image 재구성을 가능하게 할 수 있는가?
- RQ2다중 피험자 사전학습이 scratch에서 학습된 단일 피험자 모델에 비해 held-out 피험자에 대한 일반화를 향상시키는가?
- RQ3정합, 확산 사전, 서브모듈이 재구성 및 검색 성능에 어떻게 기여하는가?
- RQ4추가 가이드로 이미지 자막 생성을 포함하는 것이 재구성에 미치는 영향은 무엇인가?
- RQ5정제된 재구성은 객관적 지표에서 미정제보다 우수한가, 아니면 인간 선호도에서 차이가 있는가?
주요 결과
- 7명의 피험자에서의 사전 학습 및 새로운 피험자 데이터 1시간으로 미세 조정하여 최첨단 재구성 및 검색 지표를 달성한다.
- 4096-d 잠재 공간으로의 공유-피험자 선형 정합과 단일 파이프라인은 데이터가 제한된 상황에서 일반화를 향상시킨다.
- CLIP 이미지 임베딩을 받도록 SDXL unCLIP를 미세 조정하면 실제 이미지와 근접한 고충실 재구성이 가능하다.
- 예상된 이미지 자막은 최종 정제 단계에서 유용한 조건적 가이던스를 제공하고 의미적 충실도를 향상시킨다.
- 정제된 재구성은 인간 평가자들에 의해 미세하지 않은 결과보다 선호되지만, 일부 지표는 미세하지 않은 출력을 선호한다.
- MindEye2는 1 hour의 데이터로도 특정 지표에서 ~40x 더 많은 데이터로 학습한 단일 피험자 모델에 비해 비슷한 성능을 보인다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.