[논문 리뷰] MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
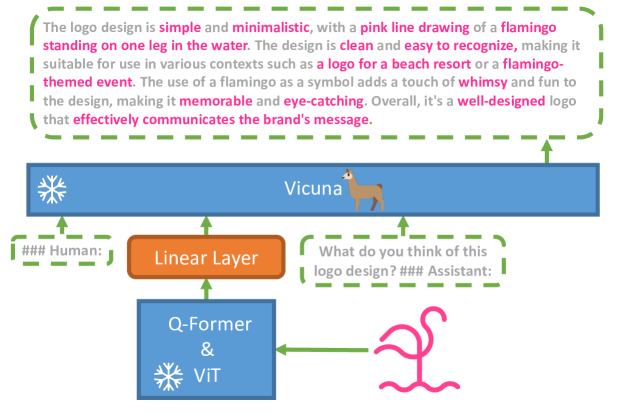
MiniGPT-4은 한 개의 투영 계층으로 고정된 비전 인코더를 고정된 고급 LLM(Vicuna)과 정렬하여 두 단계 학습과 고품질 데이터 큐레이션을 통해 GPT-4 수준의 비전-언어 능력을 갖춘다.
The recent GPT-4 has demonstrated extraordinary multi-modal abilities, such as directly generating websites from handwritten text and identifying humorous elements within images. These features are rarely observed in previous vision-language models. However, the technical details behind GPT-4 continue to remain undisclosed. We believe that the enhanced multi-modal generation capabilities of GPT-4 stem from the utilization of sophisticated large language models (LLM). To examine this phenomenon, we present MiniGPT-4, which aligns a frozen visual encoder with a frozen advanced LLM, Vicuna, using one projection layer. Our work, for the first time, uncovers that properly aligning the visual features with an advanced large language model can possess numerous advanced multi-modal abilities demonstrated by GPT-4, such as detailed image description generation and website creation from hand-drawn drafts. Furthermore, we also observe other emerging capabilities in MiniGPT-4, including writing stories and poems inspired by given images, teaching users how to cook based on food photos, and so on. In our experiment, we found that the model trained on short image caption pairs could produce unnatural language outputs (e.g., repetition and fragmentation). To address this problem, we curate a detailed image description dataset in the second stage to finetune the model, which consequently improves the model's generation reliability and overall usability. Our code, pre-trained model, and collected dataset are available at https://minigpt-4.github.io/.
연구 동기 및 목표
- 고급 LLM과 시각적 특징을 정렬하는 것이 GPT-4–유사 비전-언어 능력을 가능하게 하는지 조사한다.
- 단일 투영 계층만으로 비전과 언어 모델을 효과적으로 융합할 수 있는지 demonstr пов?
- 고품질 이미지 설명에 대한 두 번째 단계 파인튜닝이 생성의 신뢰성 및 사용성을 향상시키는지 보여준다.
제안 방법
- 고정된 BLIP-2 스타일 비전 인코더(ViT-G/14 with Q-Former)와 고정된 Vicuna LLM을 언어 디코더로 사용한다.
- 비전 특징을 Vicuna 임베딩과 정렬하기 위한 단일 선형 투영 계층을 추가한다.
- 두 단계 학습: (i) 대규모 이미지-캡션 쌍에 대해 컴포넌트를 고정한 상태로 사전 학습; (ii) 정제된 고품질 이미지-설명 데이터 세트와 설계된 대화 템플릿으로 파인튜닝.
- 모델을 Vicuna 스타일의 대화 형식으로 프롬프트하고 품질 관리를 위해 ChatGPT로 후처리하여 상세한 이미지 설명을 생성한다.
- 고급 비전-언어 작업 및 COCO 캡션화에 대한 질적 시연 및 정량 벤치마크로 평가한다.
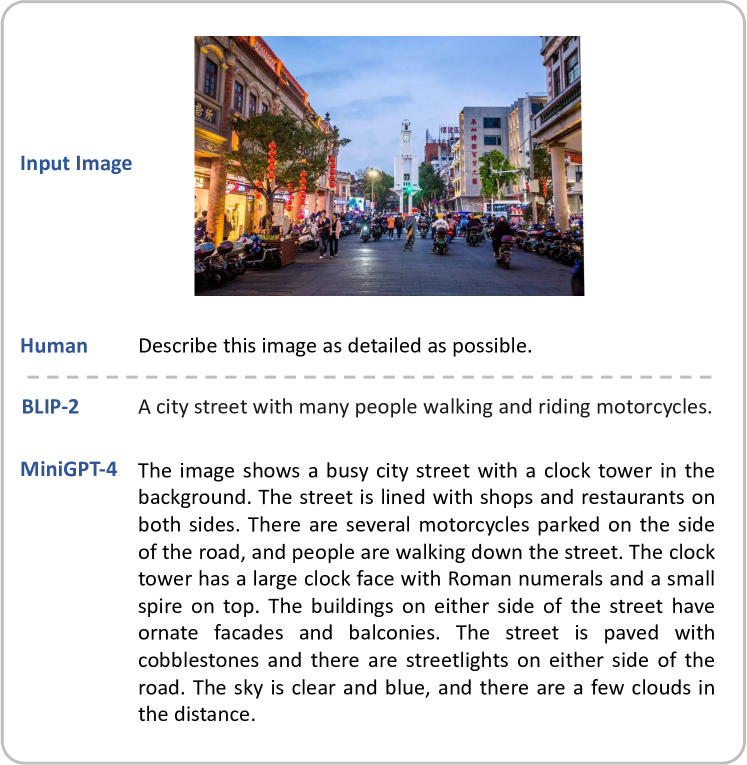
실험 결과
연구 질문
- RQ1고급 LLM과 시각적 특성을 정렬하는 것이 전체 아키텍처를 업데이트하지 않고도 GPT-4 수준의 비전-언어 능력을 가능하게 하는가?
- RQ2제한된 데이터에서 단일 투영 계층으로 시각-언어 모델을 효과적으로 정렬할 수 있는가?
- RQ3상세한 이미지 설명으로 된 두 번째 단계 파인튜닝이 생성의 신뢰성과 사용성을 향상시키는가?
- RQ4미니GPT-4는 기준선 비전-언어 모델과 비교해 어떤 새로운 능력을 보이는가?
주요 결과
| 모델 | 밈 | 레시피 | 광고 | 시 | 평균 |
|---|---|---|---|---|---|
| BLIP-2 | 0/25 | 4/25 | 1/25 | 0/25 | 5/100 |
| MiniGPT-4 | 8/25 | 18/25 | 19/25 | 20/25 | 65/100 |
| Table 2: COCO caption evaluation (Correctness) | BLIP-2 1376/5000 (27.5%) | MiniGPT-4 3310/5000 (66.2%) | |||
| Table 3: Failure rates before/after stage-2 (Detailed caption) | Before stage-2 35% | After stage-2 2% | |||
| Table 3: Failure rates before/after stage-2 (Poem) | Before stage-2 32% | After stage-2 1% | |||
| Table 4: Ablation on architecture (AOK-VQA / GQA) | MiniGPT-4 58.2 / 32.2 | a) w/o Q-Former 56.9 / 33.4 | b) +3 Layers 49.7 / 31.0 | c) + Finetune Q-Former 52.1 / 28.0 | |
| Table 5: Hallucination Evaluation (CHAIR_i / Avg. Length) | BLIP-2 1.3 / 6.5 | MiniGPT-4 (short) 7.2 / 28.8 | MiniGPT-4 (long) 9.6 / 175 |
- MiniGPT-4는 손으로 쓴 초안에서 상세한 이미지 설명, 밈 해석, 웹사이트 생성과 같은 고급 능력을 달성한다.
- 고정된 비전 인코더를 Vicuna와 정렬하는 데 단일 선형 투영 계층이 충분하며, 4개의 A100 GPU에서 약 10시간의 학습으로 GPT-4 스타일의 능력을 달성한다.
- curated 고품질 이미지-설명 데이터셋으로의 2단계 파인튜닝은 생성 실패를 크게 감소시키고(상세 캡션과 시 포함) 언어 자연성을 향상시킨다.
- 고급 작업에서 MiniGPT-4는 밈, 레시피, 광고, 시에 대해 BLIP-2보다 사용자 평가 응답에서 현저히 뛰어나며(질적 테스트에서 약 65%의 전반적 성공률).
- COCO 캡션화에서 ChatGPT로 평가할 때 MiniGPT-4가 BLIP-2보다 실제 정답 범위를 더 잘 포착한다(66.2% 대 27.5%).
- 어블레이션 및 아키텍처 변형은 Q-Former를 제거하거나 레이어를 추가하더라도 한 프로젝션 설계보다 데이터가 제한된 상황에서 개선되지 않음을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.