[논문 리뷰] MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback
MINT는 다중 턴 설정에서 LLM을 평가하는 벤치마크로, 도구 사용으로 얻는 이득과 기존 데이터셋에서 재사용된 다양한 과제들에 대한 시뮬레이션된 자연어 피드백을 측정합니다.
To solve complex tasks, large language models (LLMs) often require multiple rounds of interactions with the user, sometimes assisted by external tools. However, current evaluation protocols often emphasize benchmark performance with single-turn exchanges, neglecting the nuanced interactions among the user, LLMs, and external tools, while also underestimating the importance of natural language feedback from users. These oversights contribute to discrepancies between research benchmark evaluations and real-world use cases. We introduce MINT, a benchmark that evaluates LLMs' ability to solve tasks with multi-turn interactions by (1) using tools and (2) leveraging natural language feedback. To ensure reproducibility, we provide an evaluation framework where LLMs can access tools by executing Python code and receive users' natural language feedback simulated by GPT-4. We repurpose a diverse set of established evaluation datasets focusing on reasoning, coding, and decision-making and carefully curate them into a compact subset for efficient evaluation. Our analysis of 20 open- and closed-source LLMs offers intriguing findings. (a) LLMs generally benefit from tools and language feedback, with performance gains (absolute, same below) of 1-8% for each turn of tool use and 2-17% with natural language feedback. (b) Better single-turn performance does not guarantee better multi-turn performance. (c) Surprisingly, on the LLMs evaluated, supervised instruction-finetuning (SIFT) and reinforcement learning from human feedback (RLHF) generally hurt multi-turn capabilities. We expect MINT can help measure progress and incentivize research in improving LLMs' capabilities in multi-turn interactions, especially for open-source communities where multi-turn human evaluation can be less accessible compared to commercial LLMs with a larger user base.
연구 동기 및 목표
- 문제 해결 중 다중 턴 도구 사용으로 LLM이 얻는 이점을 평가한다.
- 다중 턴 LLM 성능에 대한 자연어 피드백의 영향을 평가한다.
- 다양한 기존 데이터셋을 재활용하여 작고 재현 가능한 MINT 평가 세트를 만든다.
- 도구 보강 및 피드백 활용 다중 턴 설정에서 오픈 소스와 폐쇄형 LLM을 비교한다.
- 다중 턴 평가에서 드러난 아티팩트와 실패 패턴을 분석하여 향후 모델 개발에 정보를 제공한다.
제안 방법
- 도구 사용을 위해 LLM이 파이썬 인터프리터를 통해 파이썬 코드를 실행할 수 있는 재현 가능한 평가 프레임워크를 제공한다.
- 피드백을 활용하는 LLM의 능력을 측정하기 위해 GPT-4로 사용자 자연어 피드백을 시뮬레이션한다.
- 추론, 코딩, 의사결정을 포괄하는 여덟 개 데이터셋에서 29,307개의 인스턴스 중 586개의Compact 부분집합을 선별한다.
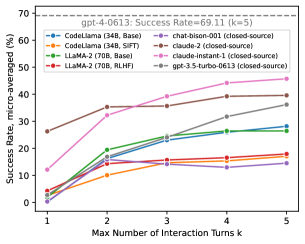
- 기본형, SIFT, RLHF 변형을 포함한 4개의 폐쇄형 및 16개의 오픈 소스 LLM을 서로 다른 상호 작용 턴(k=1..5)에서 평가한다.
- 주요 지표로 SR(성공률)을 사용하고, 도구 증강 이득을 정량화하기 위해 회귀에서 도출된 개선율(Delta_tools)을 사용한다.

실험 결과
연구 질문
- RQ1다중 턴 도구 사용이 허용될 때 LLM은 문제 해결에서 얼마나 개선되는가?
- RQ2다중 턴 상호작용에서 시뮬레이션된 자연어 피드백을 활용해 성능을 얼마나 효과적으로 개선할 수 있는가?
- RQ3다중 턴, 도구-활용, 피드백 강화 평가에서 오픈 소스 모델이 폐쇄형 모델과의 격차를 좁히는가?
- RQ4SIFT와 RLHF 훈련 방식이 다중 턴 도구 사용 및 피드백 활용에 어떤 영향을 미치는가?
- RQ5다중 턴 설정에서 어떤 실패 패턴이 나타나고, GPT-4 피드백이 인간 피드백만큼 효과적일 수 있는가?
주요 결과
| 모델 | 크기 | 유형 | k=1 | k=2 | k=3 | k=4 | k=5 | 개선 | R^2 |
|---|---|---|---|---|---|---|---|---|---|
| CodeLLaMA | 7B | Base | 0.3 | 4.1 | 7.2 | 7.2 | 4.3 | +1.1 | 0.38 |
| CodeLLaMA | 7B | SIFT | 0.3 | 7.8 | 10.2 | 9.7 | 8.7 | +1.9 | 0.53 |
| CodeLLaMA | 13B | Base | 0.5 | 13.7 | 17.9 | 19.3 | 18.4 | +4.1 | 0.70 |
| CodeLLaMA | 13B | SIFT | 1.5 | 12.6 | 13.1 | 15.0 | 14.5 | +2.8 | 0.64 |
| CodeLLaMA | 34B | Base | 0.2 | 16.2 | 23.0 | 25.9 | 28.2 | +6.6 | 0.85 |
| CodeLLaMA | 34B | SIFT | 2.6 | 10.1 | 14.7 | 15.4 | 17.1 | +3.4 | 0.86 |
| LLaMA-2 | 7B | Base | 0.2 | 5.6 | 7.3 | 8.9 | 9.7 | +2.2 | 0.87 |
| LLaMA-2 | 7B | RLHF | - | 4.3 | 6.7 | 6.5 | 7.3 | +1.5 | 0.83 |
| LLaMA-2 | 13B | Base | 0.2 | 11.4 | 15.5 | 15.2 | 14.5 | +3.2 | 0.63 |
| LLaMA-2 | 13B | RLHF | 4.1 | 12.5 | 12.5 | 13.3 | 11.9 | +1.7 | 0.47 |
| LLaMA-2 | 70B | Base | 1.9 | 19.4 | 24.6 | 26.4 | 26.4 | +5.6 | 0.73 |
| LLaMA-2 | 70B | RLHF | 4.3 | 14.3 | 15.7 | 16.6 | 17.9 | +3.0 | 0.73 |
| Lemur-v1 | 70B | Base | 1.0 | 17.9 | 23.6 | 25.3 | 26.3 | +5.8 | 0.77 |
| Lemur-v1 | 70B | SIFT | 3.8 | 27.0 | 35.7 | 37.5 | 37.0 | +7.7 | 0.73 |
| Vicuna-v1.5 | 7B | - | 0.0 | 6.7 | 12.3 | 15.4 | 12.6 | +3.4 | 0.77 |
| Vicuna-v1.5 | 13B | - | 0.0 | 2.2 | 4.4 | 6.7 | 8.4 | +2.1 | 1.00 |
- 모든 모델은 도구 사용과 언어 피드백의 이점을 보이며, 추가 도구 턴당 1–8%의 절대 이득과 피드백으로 2–17%의 이득을 얻는다.
- 강한 단일 턴 성능이 모든 경우에서 반드시 더 나은 다중 턴 성능을 보장하지는 않는다.
- 오픈 소스 모델은 일반적으로 다중 턴 성능에서 최상위 폐쇄형 모델보다 뒤처지나, 일부 오픈 모델은 언어 피드백으로 격차를 상당히 좁힌다(예: Lemur-70b-chat-v1).
- SIFT와 RLHF 훈련은 종종 다중 턴 능력을 저하시킬 수 있지만 예외도 있다(예: Vicuna-7B, Lemur-70b-chat-v1).
- GPT-4 시뮬레이션 피드백은 많은 설정에서 인간 피드백만큼 도움이 되며, 인간 평가자들은 GPT-4 피드백이 종종 실제 피드백만큼 유용하고 인간과 흡사하다고 평가한다.
- 피드백 제공 능력은 문제 해결 능력과 서로 직교적일 수 있으며, 강한 해법가가 항상 강한 피드백 제공자는 아니고 그 반대도 마찬가지다.
- MINT는 학습 데이터의 아티팩트와 실패 패턴(예: ShareGPT 아티팩트)을 감지하고 일부 모델에서 형식화 또는 구문 분석 문제를 드러낸다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.