[논문 리뷰] MIS-FM: 3D Medical Image Segmentation using Foundation Models Pretrained on a Large-Scale Unannotated Dataset
MIS-FM은 볼륨 융합(Volume Fusion)이라는 3D 의료 영상 분할용 자체 감독 사전 학습 전략을 도입하며, 주석이 없는 데이터를 활용해 전체 분할 모델을 사전 학습하고, 병렬 컨볼루션 및 트랜스포머 네트워크(PCT-Net)를 도입해 다운스트림 작업으로의 전이를 촉진합니다.
Pretraining with large-scale 3D volumes has a potential for improving the segmentation performance on a target medical image dataset where the training images and annotations are limited. Due to the high cost of acquiring pixel-level segmentation annotations on the large-scale pretraining dataset, pretraining with unannotated images is highly desirable. In this work, we propose a novel self-supervised learning strategy named Volume Fusion (VF) for pretraining 3D segmentation models. It fuses several random patches from a foreground sub-volume to a background sub-volume based on a predefined set of discrete fusion coefficients, and forces the model to predict the fusion coefficient of each voxel, which is formulated as a self-supervised segmentation task without manual annotations. Additionally, we propose a novel network architecture based on parallel convolution and transformer blocks that is suitable to be transferred to different downstream segmentation tasks with various scales of organs and lesions. The proposed model was pretrained with 110k unannotated 3D CT volumes, and experiments with different downstream segmentation targets including head and neck organs, thoracic/abdominal organs showed that our pretrained model largely outperformed training from scratch and several state-of-the-art self-supervised training methods and segmentation models. The code and pretrained model are available at https://github.com/openmedlab/MIS-FM.
연구 동기 및 목표
- 대규모 비주석 3D 의학 영상에서 분할 모델의 사전 학습을 통해 주석 데이터가 한정될 때 성능을 향상시키려는 동기 부여.
- 수작업 주석 없이 쌍 입력과 분할 레이블을 제공하는 자체 감독형 의사 분할(pretext) 작업으로서 Volume Fusion을 제안합니다.
- 다중 스케일 분할 작업으로의 효과적인 전이를 위해 병렬 컨볼루션과 트랜스포머 블록을 결합한 PCT-Net을 도입합니다.
- 대부분의 두경부, 흉부, 복부 장기 분할에서 대규모 사전 학습을 통해 효과를 입증합니다.
- 110k CT 스캔에서 사전 학습된 모델을 공개하여 더 넓은 임상 전이를 가능하게 합니다.
제안 방법
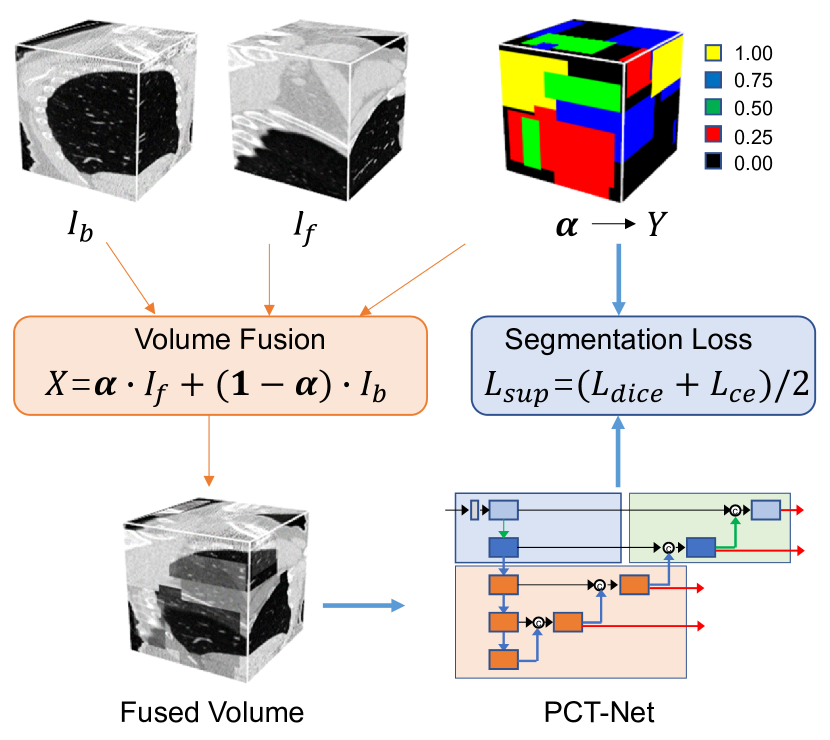
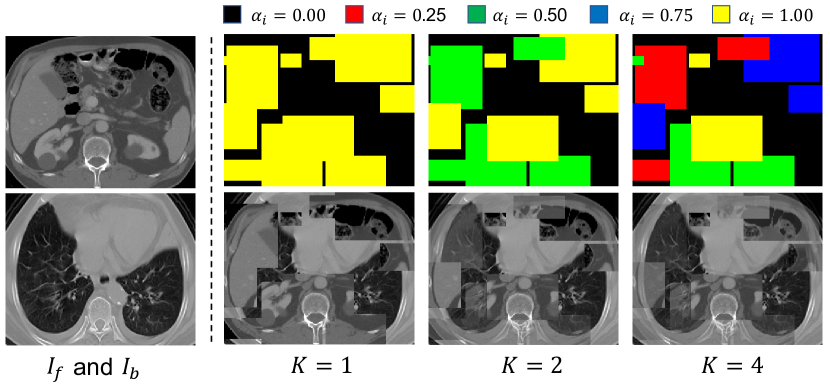
- Volume Fusion(VF): 한 스캔의 전경 부분 부피를 다른 스캔의 배경 부분 부피와 이산 융합 계수 지도(discrete fusion coefficient map)를 사용하여 융합하고, 보셀-단위 융합 범주를 분할 사전 학습 과제로 전환합니다.
- 융합 계수 alpha_i는 이산 집합 {0, 1/K, ..., 1}에서 오며, 보셀에 대해 C = K+1개의 클래스를 생성합니다; 모델은 alpha_i에 해당하는 보셀 클래스 Y를 예측합니다.
- 사전 학습 목표 L_sup은 Dice 손실과 교차 엔트로피 손실을 결합하여 의사 분할 작업에 대해 엔드-투-엔드로 전체 분할 모델을 학습합니다.
- PCT-Net: 로컬 CNN 특징과 장거리 Transformer 기반 컨텍스트를 결합하는 이중 분기 PCT 블록을 사용하는 세 수준의 피라미드 아키텍처(로컬 Conv 분기 및 글로벌 자기 주의 분기).
- Embedding 모듈은 고해상도에서 2D 컨벌루션을, 저해상도에서 3D 컨벌루션을 사용하여 비등방성 3D CT 데이터를 처리합니다; 예측은 다중 스케일에서 심층 감독과 함께 생성됩니다.
- 학습 설정은 110k개의 비주석 CT 부피(PData-110k)를 사전 학습에 사용하고, 이후 표준 Dice 및 ASSD 지표를 사용한 다운스트림 분할 데이터셋에 대해 파인 튜닝합니다.
실험 결과
연구 질문
- RQ1Volume Fusion 사전 학습이 처음부터 학습하는 것 및 기존 SSL 방법과 비교했을 때 다운스트림 3D CT 작업의 분할 성능을 개선합니까?
- RQ2융합 매개변수 K가 VF 사전 학습의 전이 성능 및 맥락 학습에 어떤 영향을 줍니까?
- RQ3사전 학습 데이터 규모(1k, 10k, 110k 부피)가 다운스트림 분할 성능에 어떤 영향을 줍니까?
- RQ4다른 스케일(두경부, 흉부, 복부)의 장기에 대해 VF-사전 학습된 특징을 PCT-Net이 효율적으로 활용할 수 있습니까?
주요 결과
- VF 사전 학습은 특히 흉부 장기에 대한 SegTHOR에서 학습 시작점 학습 및 기타 SSL 방법보다 일관되게 더 나은 성능을 보이며, Dice 88.30%와 ASSD 1.78 mm를 달성합니다.
- MICCAI 2015 Head-Neck 데이터에서 VF를 사용하는 PCT-Net은(nnU-Net, TransUNet, UNETR++ 등)을 포함한 여러 베이스라인보다 더 높은 평균 Dice(82.74)와 낮은 ASSD(0.77 mm)를 달성합니다.
- K=4일 때 가장 좋은 트레이드오프를 제공하며, 테스트 데이터셋에서 가장 낮은 ASSD(1.78 mm)와 경쟁력 있는 Dice를 달성합니다; 큰 K 값이 항상 성능을 개선하는 것은 아닙니다.
- 사전 학습 데이터 규모를 증가시키면(1k → 10k → 110k) 일반적으로 3D U-Net과 PCT-Net 모두에서 다운스트림 Dice가 향상되며, 특히 PCT-Net 아키텍처에서 더 큰 이득이 관찰됩니다.
- Patch Swapping, Model Genesis, MIM과 비교할 때 VF가 SegTHOR에서 평균 Dice(88.30%)와 가장 낮은 ASSD(1.78 mm)로 최고를 기록합니다.
- VF+PCT-Net은 VF 단독 또는 베이스라인 아키텍처보다 다운스트림 결과를 개선하는 양상을 보여, 전이 학습 및 컨텍스트 학습이 이익이 됨을 시사합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.