[논문 리뷰] Mistral 7B
Mistral 7B는 7B 언어 모델로, GQA와 SWA를 적용하여 여러 벤치마크에서 오픈/오픈-가중치 기준선을 능가하고 instruct-finetuned 변형을 포함합니다.
We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
연구 동기 및 목표
- 작고 효율적으로 설계된 7B 모델이 다양한 벤치마크에서 더 큰 오픈 모델을 능가할 수 있음을 시연한다.
- 추론 속도와 시퀀스 처리 개선을 위한 아키텍처 혁신(GQA + SWA)을 도입한다.
- 지시문-미세조정 버전을 제공하고 더 큰 채팅 모델과의 경쟁력을 보여준다.
- 실무 배치를 위한 도구와 리스크 관리/콘텐츠 조정 기능을 실세계 활용에 적용한다.
제안 방법
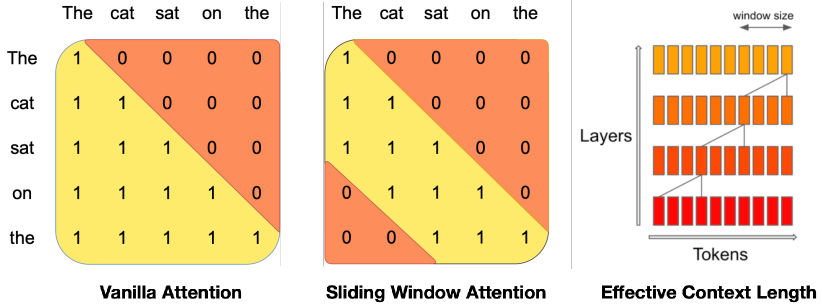
- 추론 속도를 높이고 디코딩 중 메모리 사용을 줄이기 위해 grouped-query attention (GQA)을 채택한다.
- 보다 낮은 비용으로 효과적인 맥락 길이를 확장하기 위해 sliding window attention (SWA)을 사용한다.
- 디코딩 중 메모리 사용을 상한하기 위한 롤링 버퍼 캐시를 구현한다.
- 생성 도중 주의(attention) 관리와 캐시를 위해 긴 프롬프트를 사전 채우고 청크화한다.
- 지시사항 데이터셋에 대해 모델의 버전을 미세조정하여 Mistral 7B – Instruct를 만든다.
- 참고 구현 및 vLLM, Skypilot, Hugging Face와의 통합을 공개한다.
실험 결과
연구 질문
- RQ17B 모델이 추론, 수학, 코드 생성 등을 포함한 다양한 벤치마크에서 더 큰 오픈 모델(7B/13B/34B)을 이길 수 있는가?
- RQ2아키텍처 혁신(GQA + SWA)이 성능을 희생하지 않으면서 실질적인 속도 향상과 메모리 절감을 제공하는가?
- RQ3채팅형 벤치마크에서 기본 7B 모델과 지시문-미세조정 변형 사이의 성능 차이는 어느 정도인가?
- RQ4가벼운 모델과 함께 배포될 때 가드레일 및 콘텐츠 조정 기능은 어떻게 작동하는가?
- RQ5Mistral 7B가 채팅 및 지시 따르기 설정에서 기존의 오픈 모델과 어떻게 비교되는가?
주요 결과
| 모델 | 모달리티 | MMLU | Hellaswag | WinoG | PIQA | Arc-e | Arc-c | NQ | TriviaQA | HumanEval | MBPP | MATH | GSM8K |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA 2 7B | Pretrained | 44.4% | 77.1% | 69.5% | 77.9% | 68.7% | 43.2% | 24.7% | 63.8% | 11.6% | 26.1% | 3.9% | 16.0% |
| LLaMA 2 13B | Pretrained | 55.6% | 80.7% | 72.9% | 80.8% | 75.2% | 48.8% | 29.0% | 69.6% | 18.9% | 35.4% | 6.0% | 34.3% |
| Code-Llama 7B | Finetuned | 36.9% | 62.9% | 62.3% | 72.8% | 59.4% | 34.5% | 11.0% | 34.9% | 31.1% | 52.5% | 5.2% | 20.8% |
| Mistral 7B | Pretrained | 60.1% | 81.3% | 75.3% | 83.0% | 80.0% | 55.5% | 28.8% | 69.9% | 30.5% | 47.5% | 13.1% | 52.2% |
- Mistral 7B는 모든 평가 벤치마크에서 Llama 2 13B를 능가한다.
- 수학 및 코드 생성 벤치마크에서도 Llama 1 34B를 능가한다.
- Mistral 7B – Instruct 채팅 모델은 Llama 2 13B – Chat를 능가하고 13B 채팅의 성능과 근접하게 다가간다.
- 효율적인 주의 기전(GQA 및 SWA)은 더 빠른 추론과 더 긴 효과적 맥락을 저메모리로 가능하게 한다.
- 가드레일 및 시스템 프롬프트는 출력을 조정할 수 있으며, 시스템 프롬프트는 안전성을 높이고 유용성은 유지한다.
- Self-reflection 콘텐츠 조정은 높은 정밀도(99.4%)와 강력한 재현성(95.6%)을 보인다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.