[논문 리뷰] MixSpeech: Cross-Modality Self-Learning with Audio-Visual Stream Mixup for Visual Speech Translation and Recognition
MixSpeech를 제안하는 크로스 모달리티 자기학습 프레임워크로, 혼합 음성-시각 정보를 사용해 시각적 말하기 번역과 립 리딩을 규제하고 AVMuST-TED 및 LRS/LRS2/CMLR 데이터셋에서 최첨단 성능을 달성합니다.
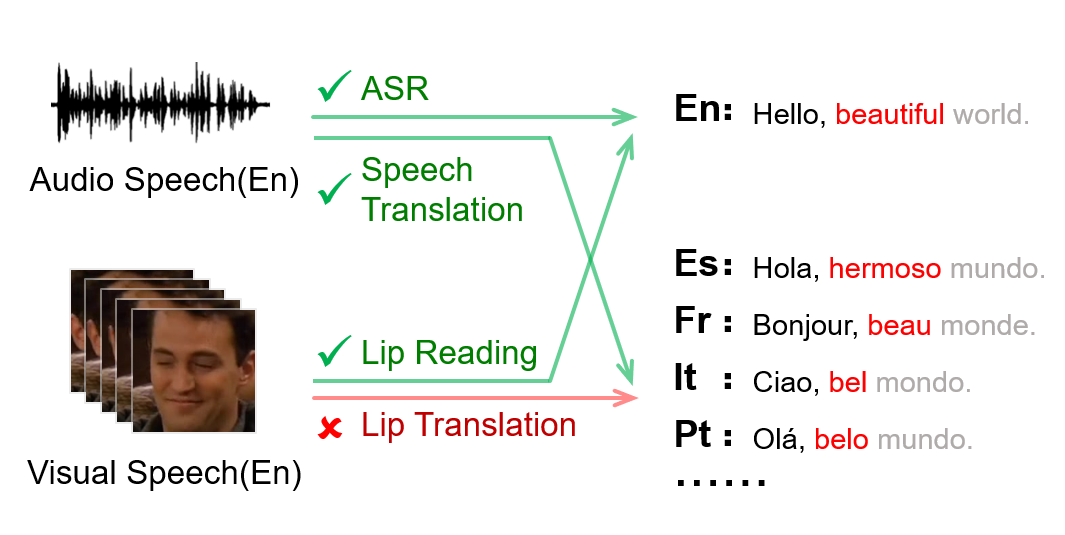
Multi-media communications facilitate global interaction among people. However, despite researchers exploring cross-lingual translation techniques such as machine translation and audio speech translation to overcome language barriers, there is still a shortage of cross-lingual studies on visual speech. This lack of research is mainly due to the absence of datasets containing visual speech and translated text pairs. In this paper, we present extbf{AVMuST-TED}, the first dataset for extbf{A}udio- extbf{V}isual extbf{Mu}ltilingual extbf{S}peech extbf{T}ranslation, derived from extbf{TED} talks. Nonetheless, visual speech is not as distinguishable as audio speech, making it difficult to develop a mapping from source speech phonemes to the target language text. To address this issue, we propose MixSpeech, a cross-modality self-learning framework that utilizes audio speech to regularize the training of visual speech tasks. To further minimize the cross-modality gap and its impact on knowledge transfer, we suggest adopting mixed speech, which is created by interpolating audio and visual streams, along with a curriculum learning strategy to adjust the mixing ratio as needed. MixSpeech enhances speech translation in noisy environments, improving BLEU scores for four languages on AVMuST-TED by +1.4 to +4.2. Moreover, it achieves state-of-the-art performance in lip reading on CMLR (11.1\%), LRS2 (25.5\%), and LRS3 (28.0\%).
연구 동기 및 목표
- 번역이 있는 시각적 말하기의 희소성으로 인해 다중언어 시각적 말하기 연구의 동기를 부여한다.
- 4개 언어에 대한 최초의 오디오-시각 멀티모달 말하기 번역 데이터셋인 AVMuST-TED를 소개한다.
- 고식별 오디오 말하기를 이용하여 시각적 말하기 번역을 규제하는 크로스 모달리티 자기학습 프레임워크를 개발한다.
- 믹스된 말하기로 모달리티 간 차이를 줄여 노이즈 환경에서 지식 전달과 로버스트성을 향상시킨다.
- 다수의 데이터셋에서 최첨단 립 번역 및 립 리딩을 입증한다.
- 다중언어 시각적 말하기 번역에 대한 통찰과 잠재적 응용을 제시한다.
제안 방법
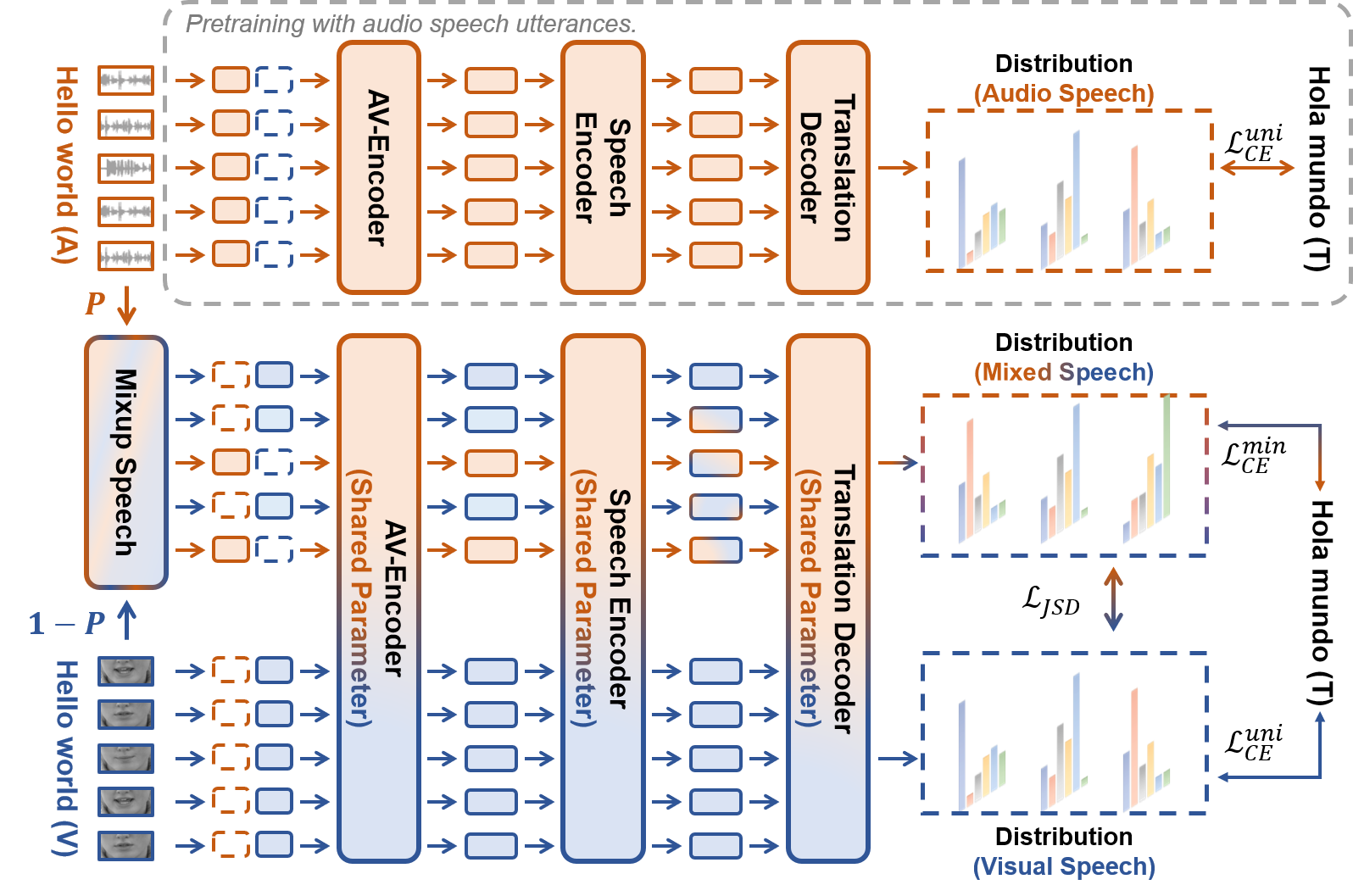
- 고식별 음성 말하기에서 번역 디코더를 사전학습하여 소스 음소에서 대상 언어 텍스트로의 언어 간 매핑을 학습한다.
- 크로스 모달리티 자기학습을 통해 시각적 말하기를 오디오 말하기와 정렬시켜 오디오로 도출된 매핑을 시각적 말하기로 전이한다.
- 프레임 레벨에서 음성 및 시각적 말하기를 보간하여 모달리티 차이를 해소하는 혼합 말하기를 합성한다( MixSpeech ).
- 훈련 중 예측 불확실성에 따라 혼합 비율을 커리큘럼 학습으로 조정한다.
- 제너슨-샤넌 발산으로 시각적 및 혼합 말하기 번역을 규제하여 출력 분포를 정렬하면서 혼합 목표 손실을 통해 오디오-비전 지식을 유지한다.
실험 결과
연구 질문
- RQ1오디오 말하기 사전학습이 시각적 말하기 번역을 개선하고 크로스 모달리티 전이 차이를 감소시킬 수 있는가?
- RQ2음성 스트림과 시각 스트림의 보간(혼합 말하기)이 모달리티 차이를 추가로 줄이고 시각적 말하기 번역 성능을 높일 수 있는가?
- RQ3커리큘럼 기반 혼합 전략이 학습 중 크로스 모달리티 지식 전달을 적응적으로 최적화할 수 있는가?
- RQ4다양한 자원 조건에서 MixSpeech가 AVMuST-TED 립 번역 및 표준 립 리딩 벤치마크(LRS2, LRS3, CMLR)에서 어떤 성능을 보이는가?
주요 결과
| Method | BLEU En-Es | BLEU En-Fr | BLEU En-It | BLEU En-Pt |
|---|---|---|---|---|
| Cascaded V | 12.7 | 11.3 | 11.5 | 13.2 |
| AV-Hubert V | 14.2 | 12.6 | 12.9 | 14.8 |
| Cascaded A(+Noise) | 16.0 | 12.9 | 12.6 | 15.5 |
| AV-Hubert A(+Noise) | 17.6 | 14.5 | 14.1 | 17.1 |
| MixSpeech(V) | 18.5 | 15.1 | 14.3 | 17.2 |
- MixSpeech는 AVMuST-TED에서 네 가지 언어에 대해 BLEU 점수를 baselines 대비 +1.4 ~ +4.2 만큼 향상시킨다.
- End-to-end MixSpeech는 AVMuST-TED에서 최첨단 립 번역, LRS2에서 25.5%, LRS3에서 28.0%, CMLR에서 11.1%의 립 리딩 성능을 달성한다.
- MixSpeech는 혼합 말하기를 사용하여 모달리티 간 차이를 해소하고, 혼합 비율이 적절히 구성될 때(예: En-Es) 뚜렷한 이득을 제공한다.
- 커리큘럼 학습 기반의 혼합 비율은 훈련 중에 적응적으로 작동하여 번역 성능을 더욱 향상시킨다.
- 소음이 섞인 음성 조건에서도 MixSpeech는 로버스트함을 유지하며 시각적 말하기 번역에서 음성 전용 baselines를 능가한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.