[논문 리뷰] Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models
본 논문은 sparse MoE 모델이 instruction tuning으로 크게 이익을 얻어 더 낮은 compute로 최첨단 결과를 달성함을 보여주며; 특히 Flan-MoE-32B가 Flan-PaLM-62B를 약 1/3의 FLOPs에서 능가한다.
Sparse Mixture-of-Experts (MoE) is a neural architecture design that can be utilized to add learnable parameters to Large Language Models (LLMs) without increasing inference cost. Instruction tuning is a technique for training LLMs to follow instructions. We advocate combining these two approaches, as we find that MoE models benefit more from instruction tuning than dense models. In particular, we conduct empirical studies across three experimental setups: (i) Direct finetuning on individual downstream tasks devoid of instruction tuning; (ii) Instructiontuning followed by in-context few-shot or zero-shot generalization on downstream tasks; and (iii) Instruction tuning supplemented by further finetuning on individual downstream tasks. In the first scenario, MoE models overall underperform dense models of identical computational capacity. This narrative, however, dramatically changes with the introduction of instruction tuning (second and third scenario), used independently or in conjunction with task-specific finetuning. Our most powerful model, FLAN-MOE-32B, surpasses the performance of FLAN-PALM-62B on four benchmark tasks, while using only a third of the FLOPs. The advancements embodied byFLAN-MOE inspire a reevaluation of the design principles of large-scale, high-performance language models in the framework of task-agnostic learning.
연구 동기 및 목표
- instruction tuning이 유사 용량의 밀집 모델보다 MoE 모델의 성능을 크게 향상시키는지 Demonstrate.
- 직접 미세조정, 맥락 내 일반화, 이후 작업별 미세조정에서 MoE 모델이 instruction tuning에 어떻게 반응하는지 Quantify.
- Flan-MoE를 위한 최적의 관행을 식별하기 위해 라우팅 전략, 전문가 수, 보조 손실을 분석하고 Flan-MoE의 딜레마를 파악하기 위해 ablations를 수행하는 Investigate.
- Flan-MoE의 확장 동작을 밀집 기준 및 PaLM 스타일 모델과의 정확도 및 계산 효율성 측면에서 비교하고 설정하는 Scale up 및 비교가 포함된 Show.
- 다국어 일반화 문제와 MoE 설계 원칙에 대한 시사점 등 한계점을 논의하는 Discuss.
제안 방법
- 대체 레이어에서 피드포워드 네트워크를 MoE 레이어로 교체하여 Transformer 아키텍처에 희소 MoE 계층을 채택한다.
- FLAN 데이터 혼합물에서 prefix-LM 목적어를 사용하여 Flan-MoE를 미세조정하고, 지정된 하이퍼파라미터로 모든 매개변수를 업데이트한다.
- MMLU, BBH, 추론, QA 벤치마크를 대상으로 제로샷 및 소수-shot 프롬프트를 사용하고 정규화된 평균 지표를 포함하여 평가한다.
- Flan-MoE를 동일한 인코더-디코더(T5) 모델과 모델 크기 및 FLOPs에 걸쳐 비교한다.
- Flan-ST-32B(32B 매개변수)로 확장하고 Flan-PaLM-62B 및 다른 벤치마크와 비교하여 계산 효율성을 강조한다.
- ablations를 통해 라우팅 전략(token-choice 대 expert-choice)과 보조 손실(balancing 대 Z-loss)을 조사한다.

실험 결과
연구 질문
- RQ1instruction tuning이 밀집 모델보다 MoE 모델에 더 큰 영향을 미치는가?
- RQ2라우팅 전략과 전문가 수가 다양한 벤치마크에서 instruction-tuned MoE 성능에 어떤 영향을 미치는가?
- RQ3Flan-MoE가 감소된 FLOPs에서 최첨단 밀집 모델과 경쟁적이거나 우수한 성능을 달성할 수 있는가?
- RQ4보조 손실과 매개변수 고정이 MoE instruction-tuning에 미치는 영향은 무엇인가?
- RQ5다국어 시나리오에서 MoE 모델의 한계는 무엇이며 이를 어떻게 완화할 수 있는가?
주요 결과
- instruction tuning은 하위 작업 및 보유 작업 모두에서 Dense 모델 대비 MoE 이점을 크게 높인다.
- Flan-MoE 모델은 두 번째 및 세 번째 실험 설정에서 유사한 Dense 상대 모델보다 우수하며, MMLU, BBH, reasoning, QA 벤치마크에서 눈에 띄는 이점을 보인다.
- 가장 큰 Flan-ST-32B 모델은 강력한 소수-shot 성능을 달성하며 Flan-PaLM-62B를 능가하는 한편 토큰당 FLOPs의 30% 미만을 사용한다.
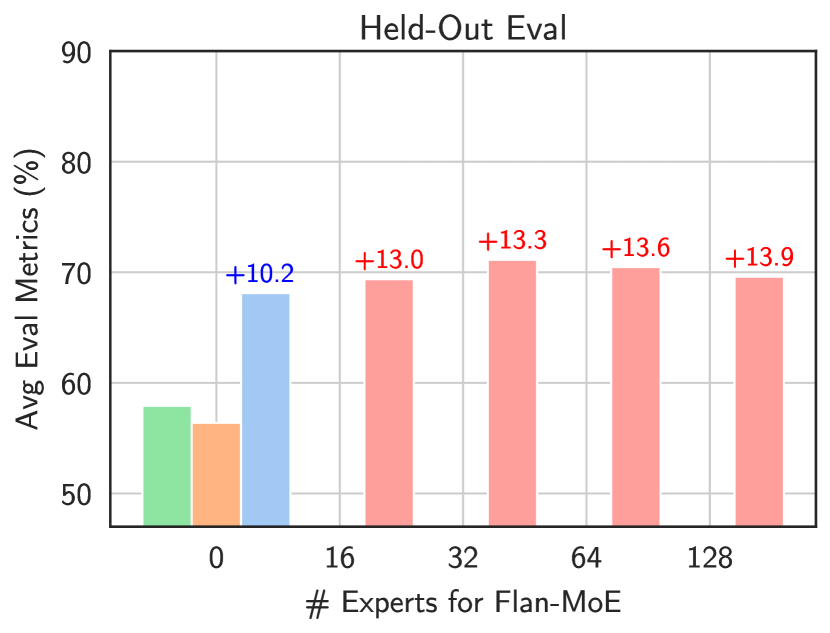
- MoE 성능은 전문가 수가 어느 정도까지 증가하면 포화를 보이는 경향이 있으며, 라우팅 전략(expert-choice 대 token-choice)이 결과에 영향을 준다.
- Instruction tuning은 더 큰 규모에서 MoE 모델에 특히 큰 이익을 주며, Flan-EC(expert-competition) 라우팅은 Task 전반에서 Flan-GS(gate routing)보다 자주 우수하다.
- Flan-MoE가 상당한 이점을 보이지만 다국어 벤치마크(TyDiQA, MGSM)에서의 지속적인 약점은 다국어 커버리지가 다양한 학습 데이터 필요함을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.