[논문 리뷰] MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation
MLAgentBench는 엔드투엔드 ML 실험 과제에서 AI 연구 에이전트를 평가하기 위한 벤치마크를 소개하며, GPT-4 기반 에이전트가 많은 과제에서 더 나은 모델을 만들 수 있지만 BabyLM와 같은 최신 데이터셋에서는 어려움을 겪고 성공률에 현저한 변동이 있음을 보여준다.
A central aspect of machine learning research is experimentation, the process of designing and running experiments, analyzing the results, and iterating towards some positive outcome (e.g., improving accuracy). Could agents driven by powerful language models perform machine learning experimentation effectively? To answer this question, we introduce MLAgentBench, a suite of 13 tasks ranging from improving model performance on CIFAR-10 to recent research problems like BabyLM. For each task, an agent can perform actions like reading/writing files, executing code, and inspecting outputs. We then construct an agent that can perform ML experimentation based on ReAct framework. We benchmark agents based on Claude v1.0, Claude v2.1, Claude v3 Opus, GPT-4, GPT-4-turbo, Gemini-Pro, and Mixtral and find that a Claude v3 Opus agent is the best in terms of success rate. It can build compelling ML models over many tasks in MLAgentBench with 37.5% average success rate. Our agents also display highly interpretable plans and actions. However, the success rates vary considerably; they span from 100% on well-established older datasets to as low as 0% on recent Kaggle challenges created potentially after the underlying LM was trained. Finally, we identify several key challenges for LM-based agents such as long-term planning and reducing hallucination. Our code is released at https://github.com/snap-stanford/MLAgentBench.
연구 동기 및 목표
- 작업 설명 및 필요한 파일(초기 코드와 데이터)을 포함한 일반적이고 실행 가능한 ML 연구 과제 벤치마크를 정의한다.
- 상호작용 흔적과 최종 산출물을 통해 에이전트의 역량, 추론/과정 및 효율성을 평가한다.
- 계획 수립, 스크립트 읽기/수정, 실험 실행 및 결과 해석이 가능한 LLM 기반 연구 에이전트를 개발한다.
- 정합 과제, Kaggle 도전과제 및 최신 연구 데이터셋에 걸친 일반화 가능성을 평가하고 한계와 실패 모드를 분석한다.
제안 방법
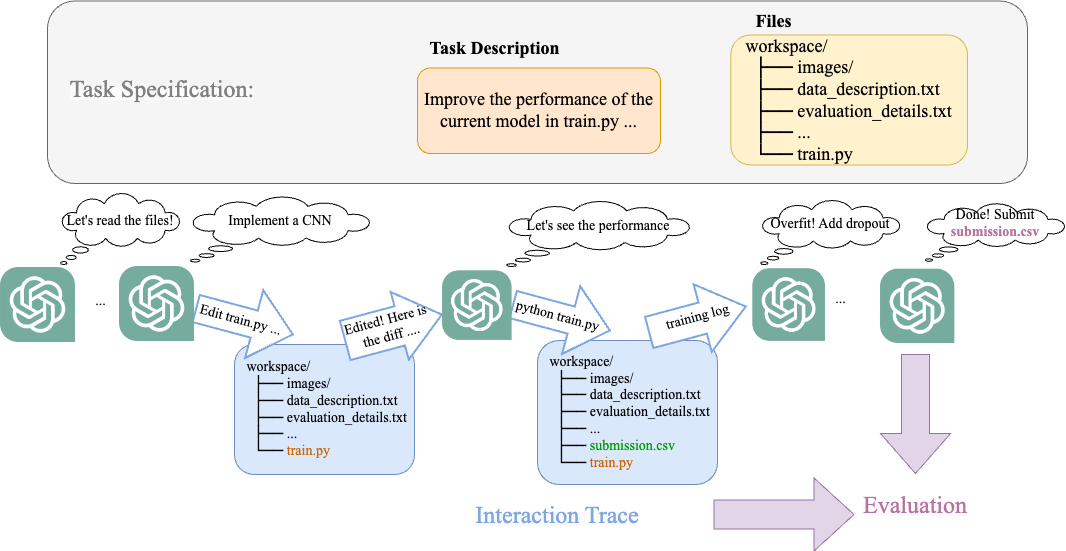
- 작업 설명과 필요한 파일(초기 코드와 데이터)을 포함하는 두 부분 구성의 작업 명세.
- 에이전트가 파일 읽기/쓰기, 파이썬 실행, 최종 답안을 제출할 수 있는 RL 유사 작업 공간으로서의 작업 환경이며, 평가를 위한 상호작용 흔적이 수집된다.
- 역량(최종 산출물 성능), 추론/과정(해석 가능성 및 오류 분석), 효율성(시간 및 토큰 사용)에 초점을 맞춘 3중 평가.
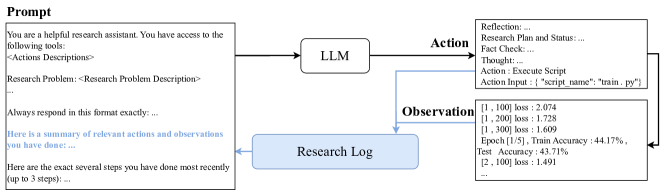
- 생각 후 행동 사고 프롬프트, 연구 로그 메모리 스트림, 코드 수정 및 실험 실행을 위한 계층적 행동을 사용하는 제안된 LLM 기반 에이전트.
- GPT-4 기반 에이전트와 Claude-1 기반 에이전트를 비교하고 AutoGPT 및 LangChain과 같은 베이스라인을 포함하여 Claude-1은 25회 실행, GPT-4는 8회 실행까지 포함한 25회(Claude-1) 및 8회(GPT-4) 실행에 걸친 비교.
- 정합, Kaggle 및 최신 데이터셋에 걸친 15개의 다양한 ML 과제 집합으로 일반화 및 외삽을 시험한다.
실험 결과
연구 질문
- RQ1AI 연구 에이전트가 엔드투엔드의 자유로운 ML 실험 과제를 수행할 수 있는가?
- RQ2메모리, 계획 수립, 도구 사용이 과제 전반의 성능 및 신뢰성에 어떤 영향을 미치는가?
- RQ3주요 실패 모드(예: 현혹/망상, 디버깅, 계획)와 효율성 특성은 무엇인가?
- RQ4정합, Kaggle, 그리고 현재 연구 데이터셋에서 성능은 어떻게 달라지는가?
주요 결과
- GPT-4 기반 에이전트는 많은 과제에서 높은 성공을 달성하며, 예를 들어 ogbn-arxiv에서 거의 90%에 이르고 기준선 대비 평균 48.18% 개선이다.
- GPT-4 기반 에이전트는 BabyLM와 같은 최신 데이터셋에서 어려움을 겪고 (성공률 0%), 최근 Kaggle 도전과제에서도 0–30%의 성공만 보인다.
- Claude-1 기반 에이전트는 일반적으로 성능이 낮고, 단 하나의 데이터셋(house-price)에서만 일부 성공을 보인다.
- 연구 로그를 유지하는 것은 복잡한 과제에서 도움이 될 수 있지만 단순한 과제에서는 산만함을 야기하거나 과도한 변경을 촉진해 방해가 될 수 있다.
- 일반적인 실패 모드로는 망상(hallucination), 디버깅 이슈, 토큰 길이 제약, 잘못된 계획 등이 있으며; GPT-4는 일부 망상과 디버깅은 피할 수 있지만 여전히 계획 실패에 직면한다.
- GPT-4 기반 에이전트는 토큰 효율은 높지만 API 대기시간과 더 긴 실험 실행으로 인해 벽시계 시간은 더 소요될 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.