[논문 리뷰] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets 은 심층 분리 가능 합성곱을 도입하여 모바일 및 임베디드 비전용의 가볍고 낮은 대기시간 CNN을 구축하며, 정확도, 크기, 속도 사이를 조정하기 위한 두 가지 간단한 하이퍼파라미터(폭 배수와 해상도 배수)를 제공한다.
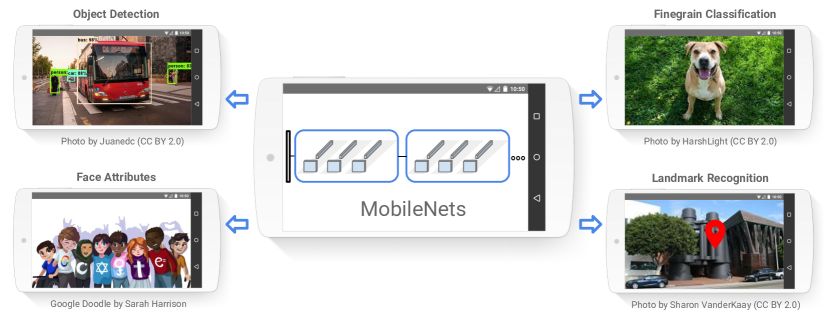
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce two simple global hyper-parameters that efficiently trade off between latency and accuracy. These hyper-parameters allow the model builder to choose the right sized model for their application based on the constraints of the problem. We present extensive experiments on resource and accuracy tradeoffs and show strong performance compared to other popular models on ImageNet classification. We then demonstrate the effectiveness of MobileNets across a wide range of applications and use cases including object detection, finegrain classification, face attributes and large scale geo-localization.
연구 동기 및 목표
- 모바일/임베디드 기기에 적합한 작고 빠른 비전 모델의 필요성을 동기 부여한다.
- 계산량과 파라미터를 줄이기 위한 깊이별 분리 합성곱에 기반한 경량 아키텍처를 제안한다.
- 지연 시간, 정확도, 모델 크기를 trade-off하기 위한 두 개의 글로벌 하이퍼파라미터(폭 배수와 해상도 배수)를 도입한다.
- 이미지넷 및 다양한 응용 분야에서 MobileNets를 실험적으로 평가하여 자원-정확도 트레이드오프를 보여준다.
- 실세계 제약하에서 모델 구성을 선택하는 실무자를 위한 가이드를 제공한다.
제안 방법
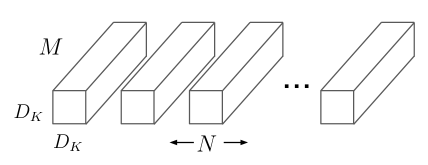
- 표준 합성을 깊이별 공간 필터와 1x1 포인티의 합성곱으로 인수분해하기 위해 깊이별 분리 합성곱을 채택한다.
- 깊이별 및 포인티우스 레이어를 포함하여 28층으로 MobileNet 아키텍처를 구성하고 각 층 뒤에 배치 정규화와 ReLU를 사용한다.
- 채널 수를 각 층에서 확장하기 위해 폭 배수 alpha를 도입하여 계산량을 대략 제곱적으로 감소시킨다.
- 입력 및 모든 내부 표현을 확장하기 위해 해상도 배수 rho를 도입하여 계산량을 rho^2만큼 감소시킨다.
- 작은 모델에 맞추기 위해 최소한의 정규화와 데이터 증강으로 RMSProp를 사용해 텐서플로우로 학습한다.
실험 결과
연구 질문
- RQ1깊이별 분리 합성곱이 표준 합성곱에 비해 정확도와 계산 비용에 어떤 영향을 미치는가?
- RQ2폭 배수와 해상도 배수를 다양하게 조정할 때 MobileNets의 자원-정확도 트레이드오프는 어떤가?
- RQ3MobileNets가 이미지넷 및 다운스트림 작업에서 파라미터와 FLOPs를 크게 줄이면서도 경쟁력 있는 정확도를 달성할 수 있는가?
- RQ4객체 인식, 미세한 구분 인식, 지오로컬라이제션, 얼굴 속성 등 다양한 응용 분야에서 MobileNets의 성능은 어느 정도인가?
주요 결과
| 모델 | ImageNet 정확도 | 멀티-어즈(백만) | 매개변수(백만) |
|---|---|---|---|
| 1.0 MobileNet-224 | 70.6% | 569 | 4.2 |
| GoogleNet | 69.8% | 1550 | 6.8 |
| VGG16 | 71.5% | 15300 | 138 |
- 깊이별 분리 합성곱은 전체 합성곱과 비교해 약 8-9배의 계산량을 줄이면서 이미지넷 정확도에서 약 1%의 손실만을 보인다.
- 더 얇은 (폭-멀) MobileNets은 유사한 계산 및 파라미터 수에서 더 얕은 버전에 비해 성능이 더 좋을 수 있다.
- 폭 배수 alpha가 감소하고 입력 해상도 rho가 감소함에 따라 정확도가 매끄럽게 감소하여 조정 가능한 트레이드오프를 가능하게 한다.
- VGG16 및 GoogleNet보다 훨씬 적은 파라미터와 FLOPs로 이미지넷에서 경쟁력 있는 정확도를 달성한다(표 8).
- 더 작은 MobileNets는 미세한 구분 인식, 지오로케이션, 얼굴 속성, 객체 탐지, 얼굴 임베딩에서 모델 크기와 계산이 크게 감소해도 경쟁력 있는 성능을 달성한다(표 9-14).
- 증류 MobileNet 변형은 다중 추가의 일부만 사용해도 얼굴 속성 분류에서 성능을 유지할 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.