[논문 리뷰] MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
MobileVLM V2는 데이터를 확장하고 학습 전략을 다듬으며 경량 프로젝터를 도입하여 모바일 중심 비전-언어 모델을 더 빠르고 강하게 만듭니다. 더 큰 VLM들보다 짧은 지연으로 최첨단 정확도를 달성합니다.
We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
연구 동기 및 목표
- 리소스 제약이 있는 디바이스(모바일/에지)에서 VLM을 실용화하는 것을 동기 부여합니다.
- 소형 VLM과 대형 VLM 간의 격차를 좁히기 위한 데이터 확장과 학습 전략을 조사합니다.
- 시각 특징과 언어 특징을 효율적으로 정렬하는 경량 프로젝션 메커니즘을 설계합니다.
- 개방형 고품질 데이터와 엔드-투-엔드 학습이 소형 VLM 성능을 끌어올릴 수 있음을 보여줍니다.
- 표준 벤치마크에서 정확도-지연 시간의 파레토 최적 트레이드오프를 보여줍니다.
제안 방법
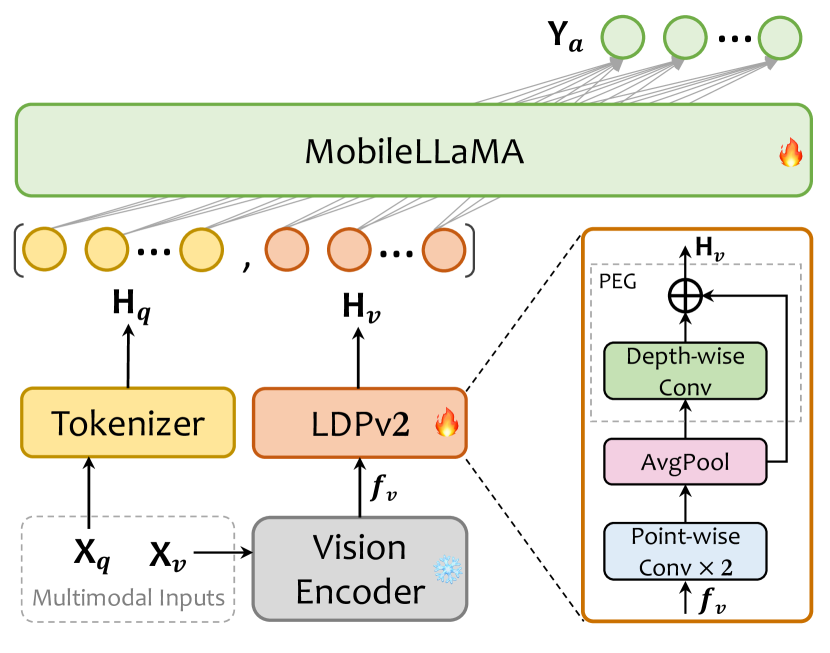
- CLIP ViT-L/14를 시각 인코더로 사용하고 입력 해상도는 336x336입니다.
- Open하고 효율적인 추론을 위해 MobileLLaMA(1.4B/2.7B)를 언어 모델로 채택합니다.
- 이미지 토큰을 풀링 및 위치 보강이 포함된 간단한 합성곱으로 축소하는 경량 다운샘플 프로젝터(LDPv2)를 도입합니다.
- 두 단계로 학습합니다: 사전 학습(전체 프로젝터+LLM과 함께 이미지-텍스트 정렬)와 다태스크 학습(비전-언어 태스크).
- ShareGPT4V-PT(1.2M 이미지-텍스트 쌍)에서 사전학습하고 2.4M 샘플의 다양한 VLM 데이터셋으로 다태스크 학습을 수행합니다.
- 효율성과 데이터 활용을 위해 비전 인코더를 동결한 채 모든 프로젝터와 LLM 매개변수를 미세 조정합니다.
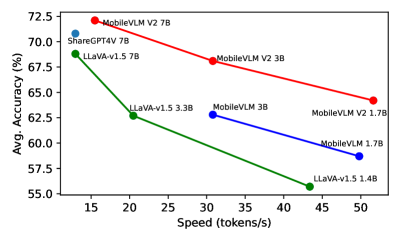
실험 결과
연구 질문
- RQ1데이터 확장과 고품질 멀티모달 데이터셋이 소형 VLM의 성능을 향상시켜 대형 모델에 근접시키나요?
- RQ2경량의 다운샘플 시각 프로젝션이 모바일 친화적 LLM에서 시각과 언어를 효과적으로 연결할 수 있나요?
- RQ3고품질 데이터에 대해 소형 VLM이 어떤 학습 방식(사전 학습 대 다태스크 학습)을 가장 잘 활용하나요?
- RQ4MobileVLM V2가 표준 벤치마크에서 정확도와 지연 시간 면에서 최신 VLM들과 어떻게 비교되나요?
주요 결과
- MobileVLM V2 1.7B가 표준 벤치마크에서 훨씬 큰 VLM과 동등하거나 더 나은 성능을 달성합니다.
- 3B MobileVLM V2 모델은 벤치마크에서 평균적으로 7B 이상 규모의 VLM보다 우수한 성능을 보입니다.
- MobileVLM V2는 일부 기준에서 약 75% 빠른 추론 속도를 제공하면서도 더 높은 평균 정확도를 달성합니다.
- 7B MobileVLM V2 모델은 데스크탑/모바일 유사 테스트 설정에서 정확도와 속도 면에서 여러 대형 VLM보다 우수합니다.
- 경량 프로젝터를 갖춘 고효율적 엔드-투-엔드 학습 방식은 강력한 정확도-지연 시간 파레토 프런티어를 제공합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.