[논문 리뷰] Model evaluation for extreme risks
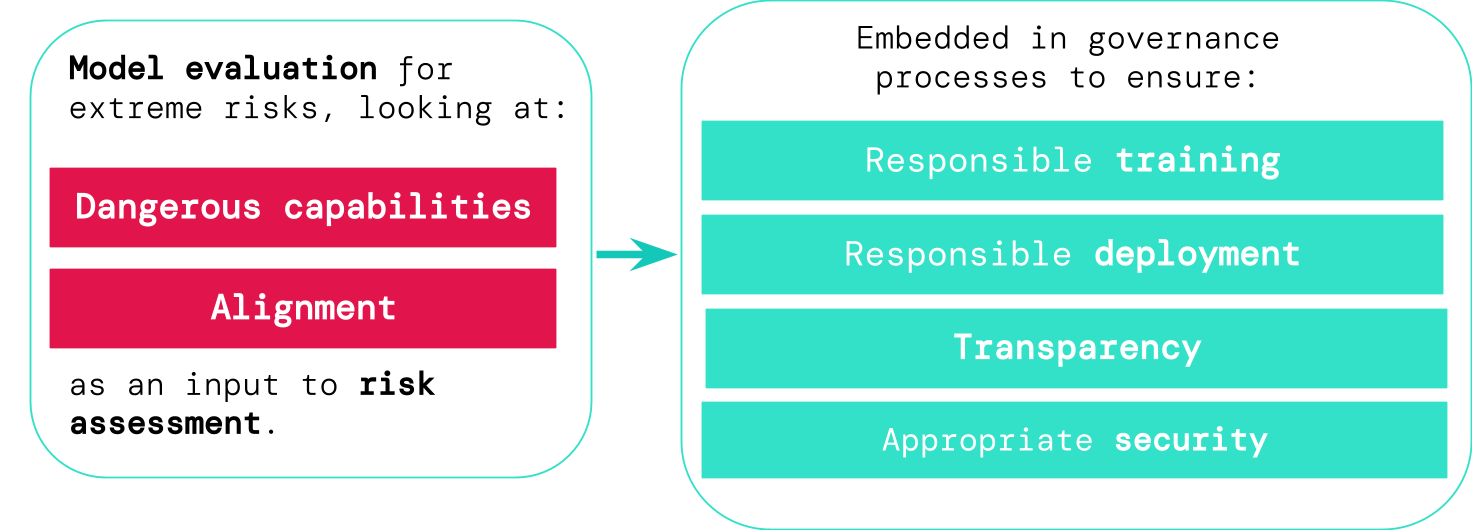
논문은 두 축의 평가 프레임워크—dangerous capabilities와 alignment—를 통해 일반-purpose 모델로부터의 극단적 위험을 평가하고, 이러한 평가가 거버넌스, 학습, 배포, 투명성 및 보안에 어떻게 포함되어야 하는지 개요를 제시한다.
Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
연구 동기 및 목표
- 최전선/일반 목적 AI 모델로부터의 극단적 위험에 대한 집중을 이끌고, dangerous capabilities와 misalignment 위험의 범위를 정의한다.
- 학습, 배포, 투명성 및 보안 프로세스에 모델 평가를 내재화하는 거버넌스 지향 프레임워크를 제안한다.
- 극단적 위험 평가의 향후 개발을 이끌 초기 작업, 설계 기준 및 한계를 개요한다.
- 개발자와 정책입안자가 평가를 학습 관리, 배포 및 위험 완화에 활용하는 방법을 권고한다.
제안 방법
- 두 가지 핵심 평가 목표를 정의한다: (a) 모델이 가질 수 있는 dangerous capabilities를 탐지하고, (b) 이러한 능력을 해롭게 적용할 성향(정합성 관련)을 평가한다.
- 내부 평가, 외부 연구 접근 및 독립적 감사가 학습 리스크 평가, 배포 리스크 평가 및 사건 보고에 정보를 제공하는 엔드-투-엔드 거버넌스 워크플로를 설명한다.
- 포괄성, 자동화, 행동 및 기계적 분석, 결함 탐지, 잠재 능력 발현, 라이프사이클 커버리지, 해석 가능성 등 극단적 위험 평가를 위한 설계 기준을 제시한다.
- 평가 결과에 따라 학습/배포를 중단하거나 조정하고 점진적 배포 및 배포 후 모니터링을 포함하는 책임 있는 학습 및 배포 관행을 옹호한다.
- 투명성 메커니즘(사건 보고, 사전 배포 리스크 평가, 과학적 보고, 교육적 시연)과 보안 관행(레드 팀핑, 격리, 신속 대응, 시스템 무결성)을 강조한다.
- 초기 이니셔티브(ARC Evals, OpenAI, Google DeepMind)를 위험한 능력과 정합성 평가를 실제로 보여주는 예로 참조한다.
실험 결과
연구 질문
- RQ1 frontier 일반-purpose 모델이 가질 수 있는 위험한 능력은 무엇이며, 이를 어떻게 신뢰성 있게 탐지할 수 있는가?
- RQ2다양한 환경에서 능력을 잘못 적용할 가능성(정합성)을 어떻게 평가할 수 있는가?
- RQ3극단적 위험 평가를 학습, 배포 및 거버넌스에 어떻게 통합하여 극단적 위험 노출을 줄일 수 있는가?
- RQ4극단적 위험 평가의 한계와 위험은 무엇이며, 이를 어떻게 완화할 수 있는가?
주요 결과
- 극단적 위험을 평가하기 위한 두 카테고리의 평가 프레임워크를 제안한다: 위험한 능력(dangerous capabilities)과 정합성(alignment)으로 평가한다.
- 평가를 리스크 평가, 학습, 배포 및 보안 의사결정에 통합하는 거버넌스 워크플로를 개요한다.
- 위험 증가를 야기하는 다양한 위험한 능력의 비포괄적 집합을 식별하고, 조합이 위험을 어떻게 증가시키는지 논의한다.
- 포괄성, 자동화, 결함 탐지 및 모델 수명주기 고려를 포함한 평가 포트폴리오에 바람직한 특성을 설명한다.
- 예상치 못한 행동 및 모델 업데이트로 인해 배포 후에도 지속적인 평가 및 모니터링이 필요함을 강조한다.
- 알 수 없는 위협 모델, emergent 현상, 정보 누출 위험 등 평가의 한계 및 잠재적 위험을 인정한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.