[논문 리뷰] MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
MoE-LLaVA는 세 단계의 MoE-Tuning 전략과 희소 MoE 기반 LVLM을 도입하여 활성화 매개변수의 아주 작은 비율만 사용하면서도 일정한 계산으로 대규모 매개변수 수를 가능하게 하고 시각-언어 대비 성능에서 경쟁력을 갖춘다.
Recent advances demonstrate that scaling Large Vision-Language Models (LVLMs) effectively improves downstream task performances. However, existing scaling methods enable all model parameters to be active for each token in the calculation, which brings massive training and inferring costs. In this work, we propose a simple yet effective training strategy MoE-Tuning for LVLMs. This strategy innovatively addresses the common issue of performance degradation in multi-modal sparsity learning, consequently constructing a sparse model with an outrageous number of parameters but a constant computational cost. Furthermore, we present the MoE-LLaVA, a MoE-based sparse LVLM architecture, which uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. Extensive experiments show the significant performance of MoE-LLaVA in a variety of visual understanding and object hallucination benchmarks. Remarkably, with only approximately 3B sparsely activated parameters, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmark. Through MoE-LLaVA, we aim to establish a baseline for sparse LVLMs and provide valuable insights for future research in developing more efficient and effective multi-modal learning systems. Code is released at https://github.com/PKU-YuanGroup/MoE-LLaVA.
연구 동기 및 목표
- 희소 전문가 혼합을 통해 LVLM 용량을 확장하면서 계산량을 감소시키는 것을 동기화한다.
- 성능 저하 없이 LVLM에 맞게 MoE를 적응시키기 위한 MoE-Tuning을 제안한다.
- 추론 시 상위 K개의 전문가만 활성화하는 MoE 기반의 희소 LVLM인 MoE-LLaVA를 도입한다.
제안 방법
- 세 단계 MoE-Tuning 학습: 1단계는 이미지 토큰을 LLM에 맞게 적응시키기 위해 MLP를 학습; 2단계는 다중 모달 이해를 위한 LLM 백엔드를 학습; 3단계는 FFN 가중치에서 MoE 전문가를 초기화하고 MoE 계층만 학습한다.
- MoE-LLaVA 아키텍처는 비전 인코더, 시각 투영 MLP, 텍스트 임베딩 계층을 갖춘 MoE 인코더 계층을 LLM에 연결하여 구축된다.
- 하드/라우터 설계 세부사항: 소프트 라우터가 토큰을 상위 K개의 전문가에 할당; 라우터 가중치 W가 x를 소프트맥스 통해 전문가 확률로 매핑.
- 토큰 전역에 걸친 전문가 활용의 균형을 촉진하기 위해 보조 부하 균형 손실이 사용된다.
- 자가회귀 손실이 이미지 및 텍스트 입력에 대한 LLM 출력을 학습시키고 보조 부하 균형 손실은 균형 항으로 보완한다.
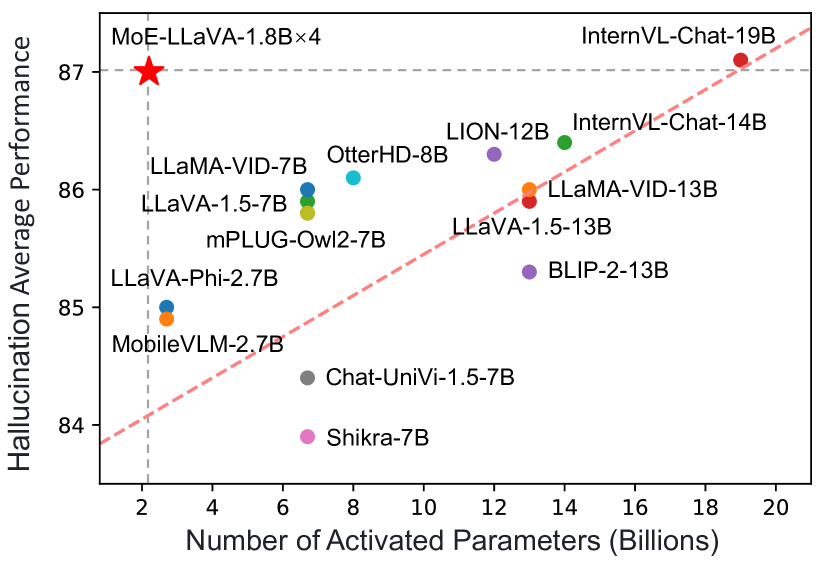
실험 결과
연구 질문
- RQ1매우 적은 수의 활성화 매개변수로도 희소 MoE LVLM이 Dense LVLM에 필적하거나 능가할 수 있는가?
- RQ2세 단계 MoE-Tuning 워크플로가 학습을 안정시키고 LVLM의 효과적인 희소화를 가능하게 하는가?
- RQ3dense 베이스라인과 비교하여 MoE-LLaVA의 이미지 이해 및 객체 환각 벤치마크에서의 성능은 어떠한가?
- RQ4다중모달 MoE-LLaVA 모델에서의 라우팅 패턴과 전문가 workload은 무엇인가?
주요 결과
- 약 3B 활성화 매개변수를 갖는 MoE-LLaVA는 시각 이해 벤치마크에서 LLaVA-1.5-7B와 비슷한 성능을 달성한다.
- 약 2.2B 활성화 매개변수를 가진 MoE-LLaVA는 POPE 객체 환각 벤치마크에서 LLaVA-1.5-13B를 능가할 수 있다.
- 3.6B 활성화 매개변수를 가진 MoE-LLaVA는 ScienceQA, POPE, MMBench, LLaVA-W, MM-Vet 등 여러 벤치마크에서 LLaVA-1.5-7B를 상회한다.
- MoE-LLaVA의 라우팅은 초기 계층에서 토큰을 전문가들 간에 대략 고르게 분배하고, 모달리티에 독립적인 라우팅 경향을 보이며, 심층 계층에서 각 전문가가 특정 작업 부하 패턴을 개발한다.
- 세 단계 학습 전략이 필수적이며, 적절한 지시-튜닝 초기화 없이 FFN을 MoE로 단순 대체하면 성능이 떨어진다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.