[논문 리뷰] MotionGPT: Human Motion as a Foreign Language
MotionGPT 는 모션을 토큰으로 양자화하고 언어 모델 백본을 사용하여 프롬프트로 다양한 모션 작업을 수행함으로써 인간 모션과 언어를 단일 생성 모델로 통합하고, 텍스트-모션, 모션-텍스트, 예측 및 중간 작업에서 강력한 결과를 달성한다.
Though the advancement of pre-trained large language models unfolds, the exploration of building a unified model for language and other multi-modal data, such as motion, remains challenging and untouched so far. Fortunately, human motion displays a semantic coupling akin to human language, often perceived as a form of body language. By fusing language data with large-scale motion models, motion-language pre-training that can enhance the performance of motion-related tasks becomes feasible. Driven by this insight, we propose MotionGPT, a unified, versatile, and user-friendly motion-language model to handle multiple motion-relevant tasks. Specifically, we employ the discrete vector quantization for human motion and transfer 3D motion into motion tokens, similar to the generation process of word tokens. Building upon this "motion vocabulary", we perform language modeling on both motion and text in a unified manner, treating human motion as a specific language. Moreover, inspired by prompt learning, we pre-train MotionGPT with a mixture of motion-language data and fine-tune it on prompt-based question-and-answer tasks. Extensive experiments demonstrate that MotionGPT achieves state-of-the-art performances on multiple motion tasks including text-driven motion generation, motion captioning, motion prediction, and motion in-between.
연구 동기 및 목표
- 대규모 언어 데이터를 모션 작업에 활용하기 위한 통합된 모션-언어 사전학습 프레임워크를 구성하고 활성화한다.
- 연속 모션을 이산 토큰으로 변환하여 모션 어휘를 형성하는 모션 토크나이저를 개발한다.
- 하나의 어휘에서 모션 토큰과 텍스트 토큰을 공동으로 처리하는 모션 인식 언어 모델을 학습한다.
- 다양한 모션 관련 작업에 대해 프롬프트 기반 다중 작업 학습을 가능하게 하기 위해 지시 미세조정을 적용한다.
제안 방법
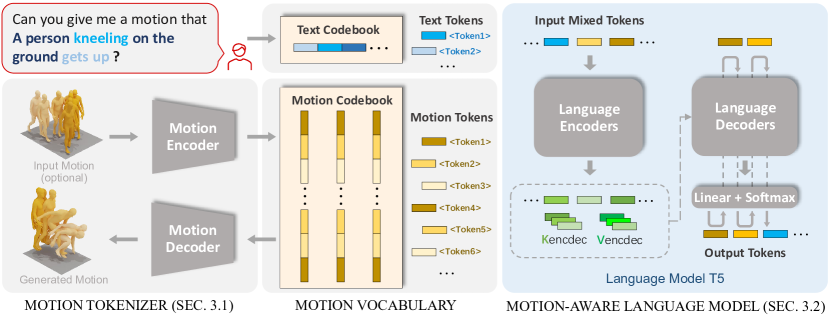
- 학습 가능한 코드북 Z에서 M프레임 모션을 L개의 이산 모션 토큰 시퀀스로 변환하기 위해 VQ-VAE를 이용한 모션 토크나이저를 도입한다.
- 모션 토큰과 텍스트 토큰을 결합해 하나의 공통 어휘 V를 생성하고, 이를 통해 단일 트랜스포머 기반 백본에서 두 모달리티를 모두 처리하고 생성할 수 있게 한다.
- 크로스 모달 시맨틱스를 포착하기 위해 모션 및 언어 데이터의 혼합으로 (T5 기반의) 모션-언어 모델을 사전 학습한다.
- 세 단계 학습 체계를 적용한다: (i) 모션 토크나이저를 학습시키고, (ii) 자가지도 및 지도 학습 목표를 포함한 모션-언어 사전 학습을 수행하고, (iii) 다양한 프롬프트를 사용한 지시 지향 미세조정으로 여러 모션 작업에 대한 지시를 수행한다.
- 모션과 텍스트를 가로질러 원천 시퀀스를 조건으로 대상 토큰 시퀀스의 가능도를 최대화하도록 자기회귀 목표를 활용하여 프롬프트로부터의 유연한 생성을 가능하게 한다.
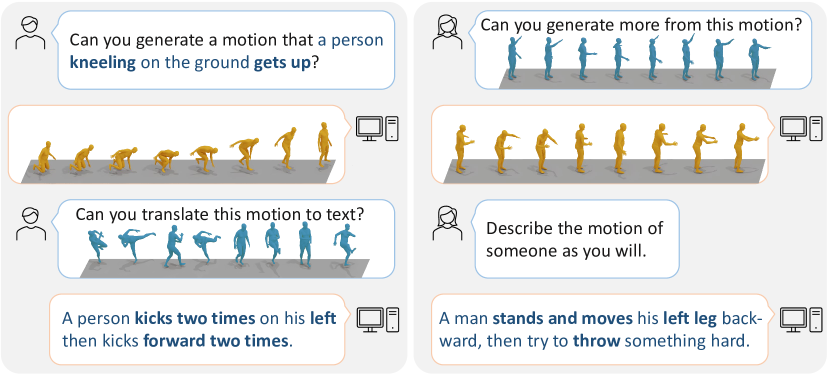
실험 결과
연구 질문
- RQ1하나의 통합 모델이 모션-언어 프레임워크를 통해 텍스트-모션, 모션-텍스트, 예측 및 중간 작업을 모두 처리할 수 있는가?
- RQ2이산 모션 어휘를 학습하고 언어 데이터와 함께 공동 학습하는 것이 미지의 모션-언어 작업에 대한 일반화를 향상시키는가?
- RQ3프롬프트 기반 데이터셋으로의 지시 지향 학습이 다양한 모션 작업에 대해 제로샷 또는 파샷 적응을 가능하게 하는가?
주요 결과
- MotionGPT 는 텍스트-모션, 모션 캡션, 모션 예측, 모션 중간 작업을 포함한 다양한 모션 작업에서 경쟁력 있거나 최첨단 성능을 달성한다.
- VQ-VAE 기반의 모션 토크나이저가 모션을 이산 토큰으로 효과적으로 표현하여 언어 모델과의 통합에 적합하다.
- 모션과 언어를 하나의 공통 어휘 내에서 공동 학습하면 하나의 트랜스포머 백본으로 두 모달리티를 함께 추론할 수 있다.
- 다양한 프롬프트를 포함한 지시 지향 학습은 보이지 않는 작업에서의 다재다능성과 성능을 향상시키지만, 모션 데이터가 충분하지 않은 대형 모델 크기만으로는 항상 이득이 되지 않는다.
- 세 단계 학습 체계(토크나이저 학습, 모션-언어 사전 학습, 지시 지향 미세조정)가 교차 모달 관계를 학습하는 데 효과적임을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.