[논문 리뷰] mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
mPLUG-Owl은 고정된 언어 모델과 학습 가능한 시각 지식 모듈 및 시각 추상기를 사용하는 모듈형 학습 패러다임을 도입하여 다중 모달 이해 및 다회 대화를 가능하게 하며 OwlEval에서 평가되었습니다.
Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
연구 동기 및 목표
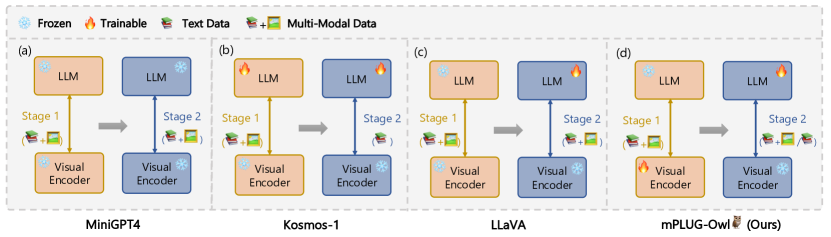
- LLM에서 대형 언어 모델을 전체 재학습하지 않고도 다중 모달 능력을 활성화하는 것을 모티브로 삼는다.
- 시각 기본 모델, 시각 지식 모듈, 시각 추상기를 결합한 모듈식 아키텍처를 제안한다.
- 이미지와 텍스트를 정렬하면서 LLM의 생성 능력을 보존하는 2단계 학습 패러다임을 개발한다.
- 공동 지시 미세조정을 통해 단일 모달 및 다중 모달 지시 이해와 다회 대화에서 향상된 성능을 보여준다.
제안 방법
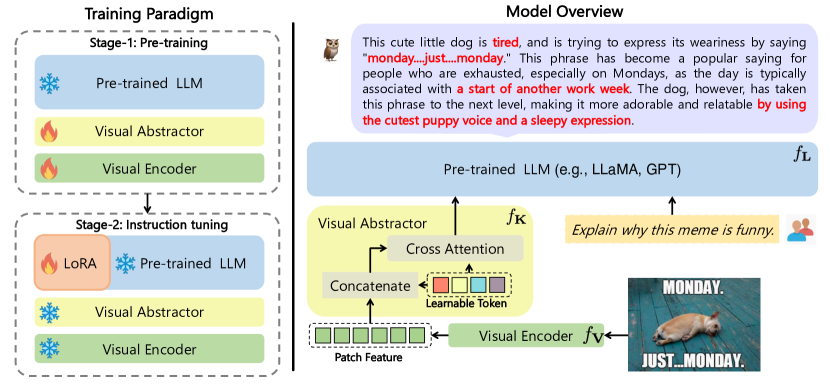
- 시각 기본 모델 f_V를 사용하여 시각 특징을 추출한다.
- 시각 특징을 학습 가능한 토큰으로 요약하는 시각 추상자 f_K를 도입한다.
- 이미지-텍스트 표현을 정렬하기 위해 시각 구성요소를 학습시키는 동안 언어 기본 모델 f_L을 고정한다.
- Step 1: 이미지-캡션 쌍을 사용하여 고정된 LLM과 함께 시각 지식 및 추상자를 학습한다.
- Step 2: f_V를 고정하고 LoRA를 f_L 및 f_K에 학습시켜 언어전용 및 다중 모달 데이터를 통한 공동 지시 미세조정을 수행한다.
실험 결과
연구 질문
- RQ1모듈식 비전-언어 구성이 고정된 LLM과 시각 지식을 정렬하여 다중 모달 이해를 가능하게 할 수 있는가?
- RQ2다중 모달 및 텍스트-전용 데이터로의 2단계 학습이 기준선 대비 단일 모달 및 다중 모달 지시 수행을 향상시키는가?
- RQ3모듈식 다중 모달 학습에서 어떤 새롭게 나타나는 능력이 생기는가(예: 다중 이미지 상관관계, 장면 문자 이해, 다국어 대화 등)?
주요 결과
- mPLUG-Owl은 OwlEval에서 지시 이해 및 시각 작업에서 MiniGPT-4 및 LLaVA와 같은 기준선보다 우수하다.
- 다중 모달 사전학습 및 공동 지시 미세조정을 포함하는 2단계 학습 체계가 최상의 성능을 낸다.
- 공동 다중 모달 및 텍스트 전용 지시 데이터는 지식 전달 및 추론 능력을 향상시킨다.
- 절차 분석에서 지시 미세조정 시 다중 모달 데이터가 시각 지식 정렬 및 텍스트 전용 작업 성능을 개선한다.
- 정성적 분석에서 다중 이미지 상관관계 및 다국어 대화와 같은 새롭게 나타나는 능력이 확인된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.