[논문 리뷰] Multi-Concept Customization of Text-to-Image Diffusion
Custom Diffusion 미세조정은 교차 어텐션 가중치의 작은 하위 집합을 학습에 사용하여 few examples에서 새로운 개념을 학습, 구성적 생성 및 기존 확산 모델과의 다중 개념 병합을 효율적으로 가능하게 한다.
While generative models produce high-quality images of concepts learned from a large-scale database, a user often wishes to synthesize instantiations of their own concepts (for example, their family, pets, or items). Can we teach a model to quickly acquire a new concept, given a few examples? Furthermore, can we compose multiple new concepts together? We propose Custom Diffusion, an efficient method for augmenting existing text-to-image models. We find that only optimizing a few parameters in the text-to-image conditioning mechanism is sufficiently powerful to represent new concepts while enabling fast tuning (~6 minutes). Additionally, we can jointly train for multiple concepts or combine multiple fine-tuned models into one via closed-form constrained optimization. Our fine-tuned model generates variations of multiple new concepts and seamlessly composes them with existing concepts in novel settings. Our method outperforms or performs on par with several baselines and concurrent works in both qualitative and quantitative evaluations while being memory and computationally efficient.
연구 동기 및 목표
- 대규모 텍스트-이미지 모델을 사용자별 개념(예: 애완동물, 객체)으로 사전 학습에 없던 개인화 가능성을 동기 부여한다.
- 기존 개념 지식을 보존하면서 새로운 개념을 학습하는 간결한 미세조정 방법을 개발한다.
- 고전적 망각 없이 단일 이미지 생성에서 다중 새로운 개념의 구성을 가능하게 한다.
- 실용적인 수준으로 학습 시간과 메모리 풋프린트를 최소화한다.
제안 방법
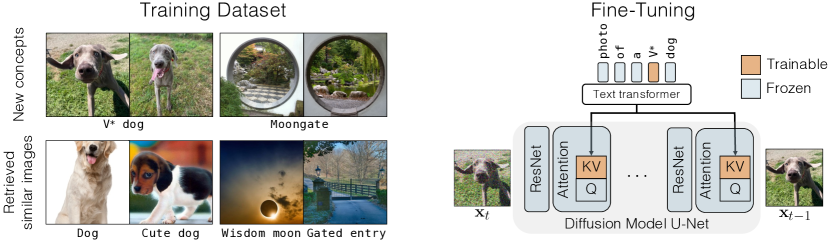
- 미세조정 동안 업데이트할 cross-attention 레이어의 최소하고 영향력 있는 매개변수 하위 집합(키와 값 투영)을 식별한다.
- 개인화된 개념을 나타내는 새로운 수정 토큰 V*를 사용하고 cross-attention 행렬과 함께 임베딩을 최적화한다.
- 언어 드리프트 및 과적합을 방지하기 위해 유사한 캡션을 가진 실제 이미지의 정규화 데이터세트를 포함한다.
- 수렴 개선을 위해 미세조정 중 증강(이미지 크기 조정 및 관련 프롬프트)을 적용한다.
- 다중 개념의 경우 공동으로 학습하거나 폐쇄 형식의 제약 최적화(최소제곱법)를 통해 개념을 병합하여 구성 가능성을 높인다.
- 목표 개념 매핑을 미리 계산된 정규화 매핑과 정렬하는 제약 최적화 목표를 통해 구성을 지지한다.
실험 결과
연구 질문
- RQ1소수의 cross-attention 가중치 하위 집합으로도 소수의 예제로 새로운 개념을 학습할 수 있는가?
- RQ2cross-attention의 키와 값만 업데이트해도 기존 지식을 보존하면서 새로운 개념 학습이 가능할까?
- RQ3다중 새로운 개념을 공동 학습하고 새로운 프롬프트에서 일관되게 구성할 수 있는가?
- RQ4다중 미세조정 개념을 병합하기 위한 폐쇄 형식 제약 최적화는 얼마나 효과적인가?
주요 결과
| 방법 | 텍스트 정렬 | 이미지 정렬 | KID (검증) |
|---|---|---|---|
| Single-concept: Textual Inversion | 0.670 | 0.827 | 22.27 |
| Single-concept: DreamBooth | 0.781 | 0.776 | 32.53 |
| Single-concept: Ours (w/ fine-tune all) | 0.795 | 0.748 | 19.27 |
| Single-concept: Ours | 0.795 | 0.775 | 20.96 |
| Multi-concept: Textual Inversion | 0.544 | 0.630 | — |
| Multi-concept: DreamBooth | 0.783 | 0.695 | — |
| Multi-concept: Ours (w/ fine-tune all) | 0.787 | 0.691 | — |
| Multi-concept: Ours (Sequential) | 0.797 | 0.700 | — |
| Multi-concept: Ours (Optimization) | 0.800 | 0.695 | — |
| Multi-concept: Ours (Joint) | 0.801 | 0.706 | — |
- 교차 어텐션 가중치 업데이트가 비례적으로 큰 영향을 미치며, 모델 파라미터의 약 3%만 업데이트해도 개념 학습이 가능하다.
- 정규화 세트로 미세조정하면 과적합과 언어 드리프를 줄이고 이미지-텍스트 정렬을 향상시킨다.
- 기법은 베이스라인에 비해 더 빠른 미세조정(~2대 A100 GPU에서 약 6분)과 더 작은 저장 용량(개념당 약 75MB)을 달성한다.
- 다중 개념 학습 및 폐쇄 형식 구성은 공유된 장면에서 일관된 생성을 가능하게 하며 대부분의 경우 베이스라인을 능가하거나 일치한다.
- DreamBooth 및 Textual Inversion에 비해 Custom Diffusion은 단일 개념 시나리오에서 더 높은 텍스트-및 이미지 정렬과 더 낮은 KID를 달성한다.
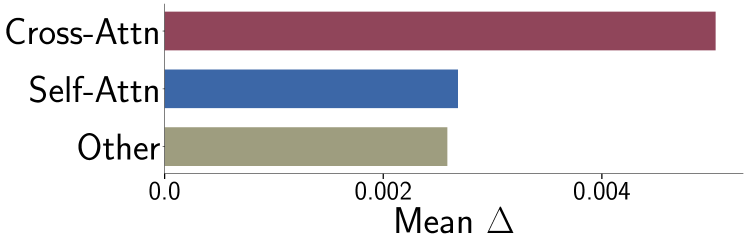
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.