[논문 리뷰] Multi-Source Conformal Inference Under Distribution Shift
결측 결과 및 분포 이동 하에서 다수의 편향 가능 데이터 소스를 이용해 대상 모집단에 대한 분포 자유 예측 구간을 개발하고, 데이터 적응 가중치 부여 및 프라이버시 보존 연합 업데이트를 적용한다.
Recent years have experienced increasing utilization of complex machine learning models across multiple sources of data to inform more generalizable decision-making. However, distribution shifts across data sources and privacy concerns related to sharing individual-level data, coupled with a lack of uncertainty quantification from machine learning predictions, make it challenging to achieve valid inferences in multi-source environments. In this paper, we consider the problem of obtaining distribution-free prediction intervals for a target population, leveraging multiple potentially biased data sources. We derive the efficient influence functions for the quantiles of unobserved outcomes in the target and source populations, and show that one can incorporate machine learning prediction algorithms in the estimation of nuisance functions while still achieving parametric rates of convergence to nominal coverage probabilities. Moreover, when conditional outcome invariance is violated, we propose a data-adaptive strategy to upweight informative data sources for efficiency gain and downweight non-informative data sources for bias reduction. We highlight the robustness and efficiency of our proposals for a variety of conformal scores and data-generating mechanisms via extensive synthetic experiments. Hospital length of stay prediction intervals for pediatric patients undergoing a high-risk cardiac surgical procedure between 2016-2022 in the U.S. illustrate the utility of our methodology.
연구 동기 및 목표
- 다중 이질적 데이터 소스를 이용하여 타깃 사이트의 결측 결과에 대해 유효한 예측 구간을 제공한다.
- 조건부 결과 분포가 사이트 간에 다른 경우 소스 사이트의 정보를 활용한다.
- 개인 수준 데이터 공유 없이 명목 커버리지를 달성한다.
- 효율성을 유지하면서 nuisance 구성요소에 대한 머신러닝 예측을 도입한다.
제안 방법
- Conformal 점수 S(X,Y)와 대상 분위수 r0를 정의하여 1-α 주변 커버리지를 달성한다.
- CCOD(공통 조건부 결과 분포) 및 랜덤 누락 가정하에서 r0의 효율적 영향 함수를 도출한다.
- 교차 적합 및 SuperLearner 기반 nuisance 추정 을 제시하여 패러메트릭에 근접한 수렴 속도를 달성한다.
- CCOD가 위반될 때 사이트별 분위수 r_k를 결합하기 위한 데이터 적응형 연합 가중치를 도입한다.
- 최소한의 데이터 공유로 밀도 비율 및 사이트별 양을 계산하는 프라이버시 보존 절차를 제공한다.
- 주어진 조건에서 가중 합산이 명목 커버리지를 유지할 수 있음을 보이는 오라클 커버리지 결과를 제공한다.
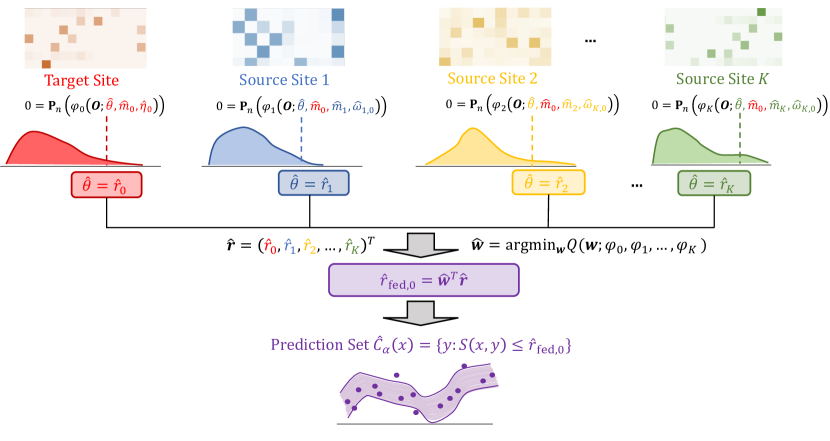
실험 결과
연구 질문
- RQ1다중 이질적 사이트의 데이터로 결측 결과가 있을 때도 타깃 모집단에 대해 유효한 분포 자유 예측 구간을 구성할 수 있는가?
- RQ2조건부 결과 분포가 사이트 간 동일하지 않을 때 소스 사이트의 정보를 어떻게 통합할 수 있는가?
- RQ3공변량 시프트와 이질성을 다루는 효율적 영향 함수 및 다사이트 컨포멀 추론의 추정 전략은 무엇인가?
- RQ4데이터-적응형 연합이 타깃 전용 또는 풀링 샘플 방법과 비교하여 커버리지 및 구간 폭에 어떤 영향을 미치는가?
주요 결과
- 제안된 방법은 MAR 및 CCOD 가정하에 다수 사이트의 정보를 활용하면서 명목 커버리지로 유효한 예측 구간을 제공한다.
- CCOD 하의 효율적 영향 함수가 사이트 간 데이터를 풀링하여 대상 사이트 분위수 r0의 추정을 개선하는 것을 가능하게 한다.
- CCOD가 위반될 때 효율성을 높이기 위해 데이터-적응형 연합 메커니즘이 사이트에 가중치를 할당하고 비정보적 소스에서 오는 바이어스를 줄인다.
- 교차 적합과 SuperLearner는 커버리지를 해치지 않으면서 유연한 nuisance 추정을 가능하게 한다.
- 경험적 결과는 연합형 구간이 타깃 전용 및 풀링 접근법에 비해 더 좁고 다양한 시뮬레이션 시나리오에서도 경쟁력 있게 정확하다는 것을 보여준다.
- 선천성 심장 결손 입원 기간(LOS)에 대한 데이터 적용은 타깃 전용 방법 대비 구간이 실질적으로 단축됨을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.