[논문 리뷰] Multi-Stage Learning for Grasp-Constrained Object Manipulation with a Simulated Panda Robot
이 논문은 robosuite, MuJoCo 기반의 모듈식 시뮬레이션 프레임워크 및 로봇 학습 벤치마크를 제시하여 재현 가능한 연구를 지원하기 위한 표준화된 작업, 절차적 환경 생성 및 다중 모드 센싱을 제공합니다.
This repository contains code and experiment assets for RAES (Reward-Aligned Expert Sequencing) and RSTB (Reward-Saturated Temporal Branching)—two lightweight reinforcement learning (RL) frameworks for long-horizon robotic manipulation without demonstrations, learned high-level controllers, or heavy task engineering. We study the robosuite [1] Stack benchmark (reach → grasp → lift/align → stack) and show that coupling continuous shaping with discrete endpoints into reward pairs produces a smoother, more learnable landscape. RAES aligns modular experts with these reward pairs (reach–grasp; lift/align–stack) and executes them sequentially. Across 10M timesteps and 5 seeds, RAES achieves the strongest performance under paired rewards, reaching 223.27 ± 28.68 mean return and 19.30% ± 2.55% success—surpassing PPO and curriculum baselines—while remaining fully RL-based (no demonstrations or hand-coded subtasks). Note: RAES and RASE (Reward Aligned Sequence of Experts) are used interchangeably in the codebase 1. Zhu Y, Wong J, Mandlekar A, Martín-Martín R, Joshi A, Lin K, Maddukuri A, Nasiriany S, Zhu Y. robosuite: A Modular Simulation Framework and Benchmark for Robot Learning. arXiv:2009.12293 [cs.RO]; 2025. Available at: https://arxiv.org/abs/2009.12293.
연구 동기 및 목표
- 로봇 조작 환경과 작업을 생성하기 위한 유연하고 모듈식 프레임워크를 제공합니다.
- 진입 장벽을 낮추기 위해 즉시 사용 가능한 현실적인 로봇 제어기와 학습 파이프라인을 제공합니다.
- 엄격한 평가와 재현성을 위한 표준화된 벤치마크 작업을 제공합니다.
- 학습과 데이터 수집을 향상시키기 위해 다중 모달 센싱 및 인간 시연을 지원합니다.
- 다양한 로봇과 작업에서 데이터 기반 로봇 공학 알고리즘의 재현 가능한 벤치마킹을 가능하게 합니다.
제안 방법
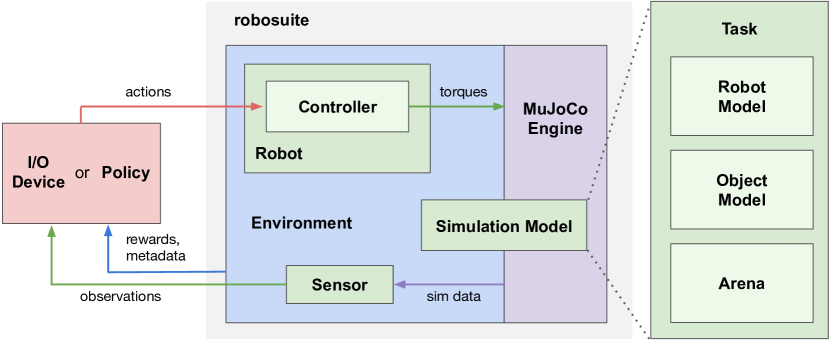
- 두 가지 주요 API: 시뮬레이션 환경을 정의하는 Modeling API와 물리 엔진과의 인터페이스를 위한 Simulation API.
- 작업 구성: 각 Task는 RobotModel, Arena, Object Model을 결합하여 MuJoCo용 MJCF 모델을 형성합니다.
- 환경 객체는 OpenAI Gym 스타일의 인터페이스와 구성 가능한 속성(예: has_renderer, horizon, reward_shaping)을 노출합니다.
- 로봇, 제어기 및 센서는 모듈식으로 구성되어 로봇 팔, 그리핑 장치 및 제어 방식의 플러그 앤 플레이 조합을 가능하게 합니다.
- 센서는 다중 모달 관찰(RGB-D, 고유감각, 힘-토크 등)을 제공하고 환경은 보상 및 작업 메타데이터를 제공합니다.
- 입출력 장치(예: 키보드, SpaceMouse)는 시연 및 디버깅을 위한 실시간 원격 조작과 데이터 수집을 가능하게 합니다.
- 벤치마크 모음은 재현 가능한 실험 설정으로 SAC와 같은 학습 알고리즘을 아홉 개의 표준화된 과제에서 평가합니다.

실험 결과
연구 질문
- RQ1모듈식 프레임워크가 재현 가능한 벤치마킹을 통해 다양한 로봇 조작 작업을 어떻게 지원할 수 있는가?
- RQ2조작 작업에서 제어기 선택과 동작 공간이 학습 효율성에 미치는 영향은 무엇인가?
- RQ3표준화된 환경 모음이 데이터 기반 로봇 공학 방법의 공정한 비교와 진행 추적을 가능하게 할 수 있는가?
- RQ4다중 모달 센싱과 인간 시연이 시뮬레이티드 로봇공학의 학습 파이프라인에 어떻게 통합되는가?
- RQ5태스크 전반에서 학습 성능을 극대화하는 실용적 구성(로봇, 그리퍼, 제어기)은 무엇인가?
주요 결과
- robosuite v1.0은 일곱 가지 로봇 모델, 여덟 가지 그리퍼, 여섟 가지 제어기, 그리고 아홉 가지 표준화된 작업을 제공합니다.
- SAC를 사용한 벤치마킹은 특정 설정에서 아홉 개 환경 중 세 개(Block Lifting, Door Opening, Two Arm Peg-in-Hole)을 해결함을 보여줍니다.
- 운용 공간 제어기가 적어도 일부 작업에서 조인트 속도 제어기보다 학습 효율성을 높이며, 작업 공간 탐색의 이점을 시사합니다.
- 두 팔 작업은 같은 프레임워크에서 여러 로봇(Panda 또는 Sawyer)의 협응 조작 능력을 시연합니다.
- 이 프레임워크는 절차적 환경 생성을 지원하고 재현 가능한 실험 결과를 위한 저장소를 제공합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.