[논문 리뷰] Multimodal Chain-of-Thought Reasoning in Language Models
이 논문은 Multimodal-CoT를 소개한다, 텍스트와 비전 입력에서 추론 근거를 생성하고 그 다중모달 근거를 사용해 답을 추론하는 두 단계 미세조정 프레임워크로, 1B 모델로 ScienceQA에서 최첨단을 달성했다.
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
연구 동기 및 목표
- 다중모달(텍스트+비전) 체인-오브- thought(CoT) 추론을 통해 답 추론을 개선하려는 동기 부여.
- 1B-모델이 CoT에서 어려움을 겪는 이유와 비전이 추론의 함정을 완화하는 방법을 조사.
- 근거 생성과 답 추론을 분리하는 두 단계 미세조정 프레임워크를 제안.
- ScienceQA 벤치마크에서 접근법을 평가하고 언어 전용 및 더 큰 모델과 비교.
제안 방법
- 두 단계에서 텍스트-텍스트 트랜스포머(T5 기반)를 미세조정: 근거 생성과 답 추론.
- 비전 인코더(DETR)를 사용해 이미지 특징을 추출하고 게이트드 퓨전을 통해 언어 표현과 융합.
- 첫 번째 단계에서 언어+비전 입력으로 근거 R을 생성; 두 번째 단계에서 원래 입력과 R에 조건화해 답을 추론.
- ScienceQA의 주석된 근거와 답변에 대한 감독 학습으로 두 단계 훈련 체계 채택.
- 언어-비전 간의 주의 기반 상호작용을 통해 비전 특징을 도입해 근거 품질과 정답 정확도 향상.
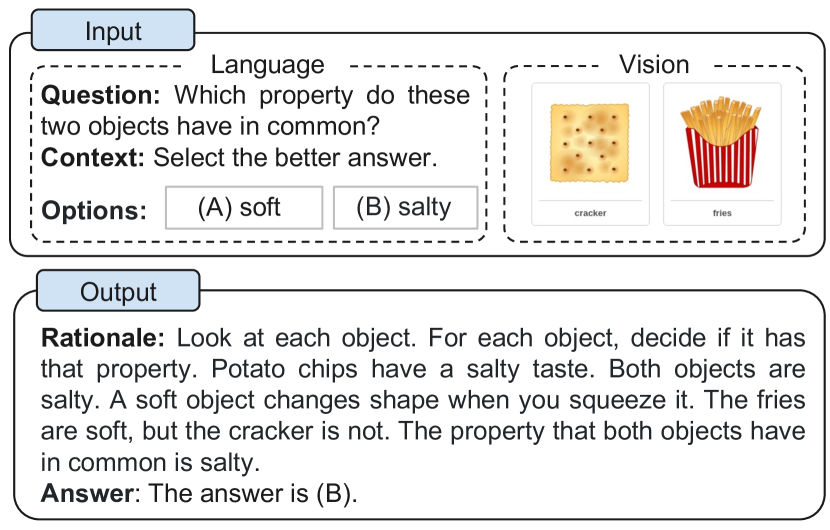
실험 결과
연구 질문
- RQ1다중모달(텍스트+비전) CoT 추론이 다중모달 QA 벤치마크에서 언어 전용 CoT를 능가할 수 있는가?
- RQ2다중모달 입력이 가능한 경우 1B-모델은 두 단계의 근거 생성과 답 추론 프레임워크로 이익을 얻는가?
- RQ3비전 특징(DETR)과 캡션의 사용이 근거 품질과 최종 정답에 어떤 영향을 미치는가?
- RQ4멀티모달 융합(주의 기반의 게이트 퓨전)이 텍스트 전용 베이스라인에 비해 추론 및 정확도에 어떤 영향을 미치는가?
주요 결과
| 모델 | 크기 | NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | 평균 |
|---|---|---|---|---|---|---|---|---|---|---|
| Human | - | 90.23 | 84.97 | 87.47 | 89.60 | 87.50 | 88.10 | 91.59 | 82.42 | 88.40 |
| MCAN (2019) | 95M | 56.08 | 46.23 | 58.09 | 59.43 | 51.17 | 55.40 | 51.65 | 59.72 | 54.54 |
| Top-Down (2018) | 70M | 59.50 | 54.33 | 61.82 | 62.90 | 54.88 | 59.79 | 57.27 | 62.16 | 59.02 |
| BAN (2018) | 112M | 60.88 | 46.57 | 66.64 | 62.61 | 52.60 | 65.51 | 56.83 | 63.94 | 59.37 |
| DFAF (2019) | 74M | 64.03 | 48.82 | 63.55 | 65.88 | 54.49 | 64.11 | 57.12 | 67.17 | 60.72 |
| ViLT (2021) | 113M | 60.48 | 63.89 | 60.27 | 63.20 | 61.38 | 57.00 | 60.72 | 61.90 | 61.14 |
| Patch-TRM (2021) | 90M | 65.19 | 46.79 | 65.55 | 66.96 | 55.28 | 64.95 | 58.04 | 67.50 | 61.42 |
| VisualBERT (2019) | 111M | 59.33 | 69.18 | 61.18 | 62.71 | 62.17 | 58.54 | 62.96 | 59.92 | 61.87 |
| UnifiedQA Base (2020) | 223M | 68.16 | 69.18 | 74.91 | 63.78 | 61.38 | 77.84 | 72.98 | 65.00 | 70.12 |
| UnifiedQA Base + CoT | 223M | 71.00 | 76.04 | 78.91 | 66.42 | 66.53 | 81.81 | 77.06 | 68.82 | 74.11 |
| GPT-3.5 (2020) | 175B | 74.64 | 69.74 | 76.00 | 74.44 | 67.28 | 77.42 | 76.80 | 68.89 | 73.97 |
| GPT-3.5 + CoT | 175B | 75.44 | 70.87 | 78.09 | 74.68 | 67.43 | 79.93 | 78.23 | 69.68 | 75.17 |
| Multimodal-CoT Base | 223M | 87.52 | 77.17 | 85.82 | 87.88 | 82.90 | 86.83 | 84.65 | 85.37 | 84.91 |
| Multimodal-CoT Large | 738M | 95.91 | 82.00 | 90.82 | 95.26 | 88.80 | 92.89 | 92.44 | 90.31 | 91.68 |
- 비전 특징을 이용한 Multimodal-CoT가 ScienceQA에서 GPT-3.5보다 16 포인트 높은 성능을 달성했다(대형 설정에서 91.68% 대 75.17%).
- 두 단계의 Multimodal-CoT가 정답을 직접 예측하는 한 단계 베이스라인보다 더 높은 정확도를 달성했다.
- 비전 특징(DETR)을 사용하는 것이 근거 품질(RougeL)과 최종 정답 정확도(84.91%)를 크게 향상시키고 망상으로 인한 오류를 감소시켰다.
- 다른 비전 특징이 성능에 영향을 주며, DETR이 강한 이점을 제공하는 반면 CLIP과 ResNet은 이 설정에서 열등했다.
- 이 접근법은 백본 모델(UnifiedQA Base/Large, FLAN-T5 Base/Large) 간에 일반화되며 1B에서 약 0.7B 파라미터 규모에서도 효과적이다.
- 특성 제거(Ablation) 실험은 두 단계 설계나 비전 특징을 제거하면 성능이 떨어짐을 보인다(예: Two-Stage Framework 제거 시 평균 82.57로 감소; Vision Features 제거 시 평균 70.53으로 감소).

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.