[논문 리뷰] Multimodal Foundation Models: From Specialists to General-Purpose Assistants
이 논문은 다중 모달 기초 모델의 포괄적 분류체계와 진화 리뷰를 제공하며, 대형 언어 모델과 도구 체이닝으로 안내되는 일반 목적 시각 보조 도구로의 전환을 상세히 다룬다.
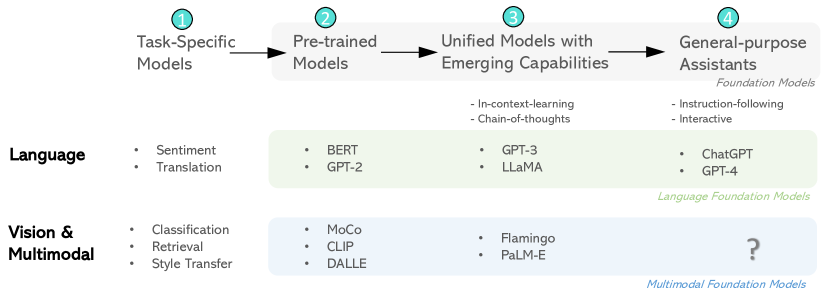
This paper presents a comprehensive survey of the taxonomy and evolution of multimodal foundation models that demonstrate vision and vision-language capabilities, focusing on the transition from specialist models to general-purpose assistants. The research landscape encompasses five core topics, categorized into two classes. (i) We start with a survey of well-established research areas: multimodal foundation models pre-trained for specific purposes, including two topics -- methods of learning vision backbones for visual understanding and text-to-image generation. (ii) Then, we present recent advances in exploratory, open research areas: multimodal foundation models that aim to play the role of general-purpose assistants, including three topics -- unified vision models inspired by large language models (LLMs), end-to-end training of multimodal LLMs, and chaining multimodal tools with LLMs. The target audiences of the paper are researchers, graduate students, and professionals in computer vision and vision-language multimodal communities who are eager to learn the basics and recent advances in multimodal foundation models.
연구 동기 및 목표
- 비전 및 비전-언어 영역에서 다중 모달 기초 모델의 개요와 분류 체계를 설명한다.
- 감독 신호 전반에 걸친 시각 이해 및 생성 학습 패러다임을 분석한다.
- 일반 목적 시각 보조 도구를 향한 단계와 LLM과의 상호작용에 대해 논의한다.
- 신흥 주제: 통합 비전 모델, 엔드투엔드 다중 모달 LLM, 그리고 LLM과의 도구 체인을 제시한다.
제안 방법
- 다중 모달 기초 모델을 특정 목적 대 일반 목적 보조 카테고리로 분류한다.
- 감독 학습 프리트레이닝, 언어 감독, 및 이미지-전용 자기지도 학습 등 역사적 및 현대 학습 패러다임을 조사한다.
- 텍스트-투-이미지 및 텍스트 기반 편집 패러다임을 포함한 시각 생성 접근법을 요약한다.
- 통합 비전 모델로의 진전과 다중 모달 작업에서의 LLM과의 상호작용을 설명한다.
- 대형 다중 모달 모델의 학습 전략과 도구를 LLM과 연결하는 다중모달 에이전트의 설계를 논의한다.

실험 결과
연구 질문
- RQ1비전 및 비전-언어 과제에서 다중 모달 기초 모델을 뒷받침하는 핵심 구성 요소와 학습 패러다임은 무엇인가?
- RQ2현재 접근법은 전문 모델에서 일반 목적 시각 보조 도구로 어떻게 전환하는가?
- RQ3통합 비전 모델, 엔드투엔드 다중 모달 LLM, 및 도구 체인 다중 모달 에이전트의 주요 도전과 신흥 방향은 무엇인가?
주요 결과
- 두 가지 분류의 분류체계: 특정 목적 사전 학습 모델과 일반 목적 보조 도구의 식별.
- 일반 목적 보조를 위한 세 가지 광범위 주제: 통합 비전 모델, 엔드투엔드 다중 모달 LLM, 및 LLM과의 도구 체인 구성의 문서화.
- 시각 이해를 위한 학습 신호의 요약: 라벨 감독, 언어 감독, 이미지-전용 자기지도 학습, 더불어 다중 모달 융합 및 픽셀/영역 수준 프리트레이닝.
- 텍스트 조건 생성 및 인간 정합 생성 기술을 포함한 시각 생성 트렌드 개요.
- 대화형, 도구 보강 기능을 위한 비주얼 모델과 LLM의 통합 및 다중 모달 에이전트로의 진전에 대한 논의.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.