[논문 리뷰] Muse: Text-To-Image Generation via Masked Generative Transformers
Muse는 이산 잠재 공간에서 마스킹된 토큰 예측을 사용하는 텍스트-투-이미지 Transformer를 도입하고, frozen LLM 임베딩에 조건화되어 SOTA FID/CLIP를 달성하는 동시에 빠른 병렬 디코딩과 제로샷 편집을 가능하게 합니다.
We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing. More results are available at https://muse-model.github.io
연구 동기 및 목표
- Discretized 토큰 공간에서 마스크 모델링을 활용하여 텍스트-투-이미지 합성을 진전시킨다.
- 사전 학습된 언어 모델 임베딩을 도입하여 의미적 충실도와 공간 추론을 개선한다.
- 확산/자기회귀 기반 baselines에 비해 이산 토큰에 대한 병렬 디코딩으로 추론 효율성을 향상한다.
- 미세 조정 없이 제로샷 이미지 편집(인페인팅, 아웃페인팅, 마스크-프리 편집)을 가능하게 한다.
- CC3M과 COCO에서 SOTA 품질과 정렬성을 입증하기 위해 평가한다.
제안 방법
- Dual VQGAN 토크나이저로 이미지를 이산 토큰으로 인코딩한다(256×256 with f=16; 512×512 with f=8).
- 고정된 T5-XXL 텍스트 임베딩에 이미지 디코더를 조건화하여 풍부한 언어 컨디셔닝을 제공한다.
- base 마스크드 Transformer를 사용하여 텍스트 임베딩에 대한 교차 주의와 이미지 토큰 간의 자기 주의로 마스킹된 이미지 토큰을 예측한다.
- 토큰 예측의 강건성을 장려하고 유연한 샘플링을 가능하게 하기 위해 코사인 스케줄에서 샘플링된 가변 마스킹률로 학습한다.
- 텍스트 임베딩에 조건화된 상태로 저해상도 토큰을 고해상도 토큰으로 변환하는 SR(Super-Resolution) Transformer를 뒤따르게 한다.
- 샘플링 중에 분류기-없는 가이던스를 적용하여 텍스트-이미지 정렬성을 향상시키고 음성 프롬프트를 허용한다.
- 병렬 디코딩을 반복적으로 수행하여 한 단계에 여러 토큰을 예측하게 하여 자가회귀나 확산 모델보다 추론 속도를 높인다.
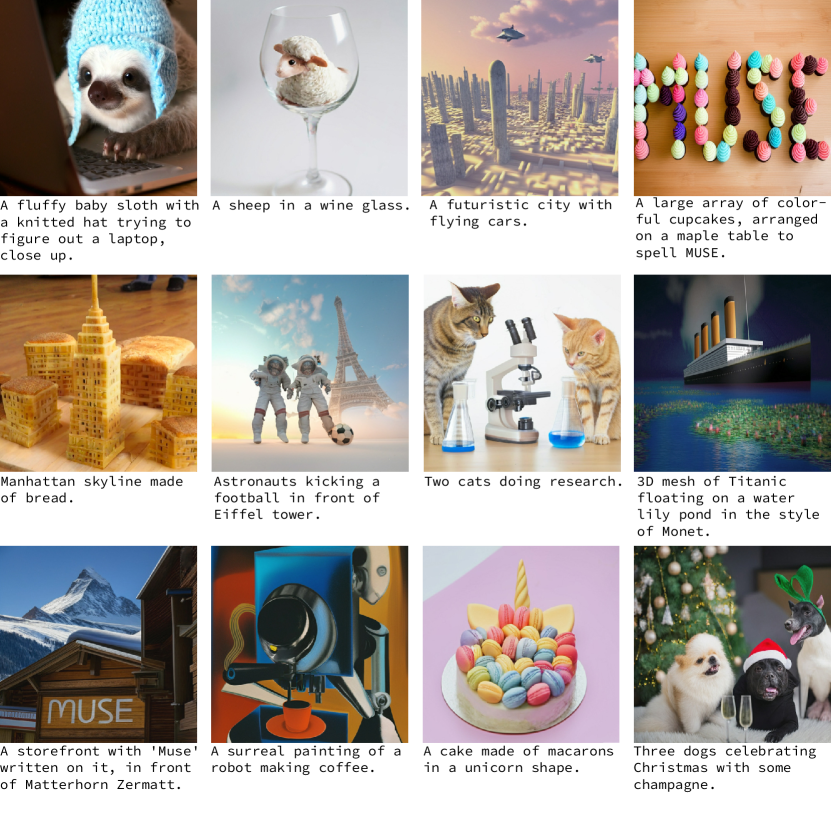
실험 결과
연구 질문
- RQ1사전 학습된 LLM 임베딩에 조건화된 마스크된 이산 토큰 이미지 모델이 최첨단 이미지 충실도와 텍스트 정렬성을 달성할 수 있는가?
- RQ2256×256 및 512×512 출력에 대해 기본 및 초해상도 토큰 트랜스포머의 조합이 어떻게 작동하는가?
- RQ3확산/자가회귀 baselines와 비교하여 이산 토큰 프레임워크에서의 병렬 디코딩으로 달성할 수 있는 추론 효율성 향상은 어느 정도인가?
- RQ4미세 조정 없이 제로샷 편집(인페인팅, 아웃페인팅, 마스크-프리 편집)이 어느 정도 가능하는가?
- RQ5Muse가 CC3M과 COCO에서 빠른 샘플링을 유지하면서 FID와 CLIP 측면에서 어떤 성능을 보이는가?
주요 결과
| 모델 | 모델 유형 | 매개변수 | FID-30K | 제로샷 | CLIP |
|---|---|---|---|---|---|
| VQGAN | Autoregressive | 600M | 28.86 | 0.20 | - |
| ImageBART | Diffusion+Autogressive | 2.8B | 22.61 | 0.23 | - |
| LDM-4 | Diffusion | 645M | 17.01 | 0.24 | - |
| RQ-Transformer | Autoregressive | 654M | 12.33 | 0.26 | - |
| Draft-and-revise | Non-autoregressive | 654M | 9.65 | 0.26 | - |
| Muse(base model) | Non-Autoregressive | 632M | 6.8 | 0.25 | - |
| Muse(base + super-res) | Non-Autoregressive | 632M + 268M | 6.06 | 0.26 | - |
- Muse는 CC3M에서 SOTA FID를 달성한다(6.06, 632M base + 268M super-res 토큰).
- Muse-3B는 COCO 제로샷 FID 7.88에 CLIP 0.32를 달성한다.
- Muse는 사람 간 정렬 프롬프트에서 비교 가능한 모델보다 우수한 성능을 보이며, 사용자 연구에서 프롬프트-이미지 정렬이 Stable Diffusion 대비 약 2.7배 더 좋다.
- 분석적으로 이산 토큰과 병렬 디코딩 덕분에 확산 또는 자가회귀 모델보다 추론 속도가 크게 빠르다(예: TPUv4에서 256×256–512×512 이미지당 0.5–1.3초).
- 미세 조정이나 역전(inversion) 없이도 조건부 토큰 재샘플링을 통해 제로샷 이미지 편집(인페인팅, 아웃페인팅, 마스크-프리 편집)이 직접 가능하다.
- 정성적 결과는 기수성(cardinality), 구성, 스타일, 텍스트 렌더링에 대한 강한 이해를 보여주지만, 긴 다단어 구와 높은 순서 수에 대한 도전은 남아 있다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.