[논문 리뷰] Nemotron-4 340B Technical Report
Nemotron-4-340B 모델 패밀리(Base, Instruct, Reward)는 오픈 소스이며, 합치 데이터(synthetic data) 중심의 정렬에 중점을 두고 RewardBench에서 최고 점수를 달성하고 표준 벤치마크에서도 경쟁력 있는 성능을 보인다.
We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
연구 동기 및 목표
- permissive 라이선스 하에 340B 규모의 오픈 액세스 언어 모델 패밀리 출시
- 지시 수행, 채팅 기능, 보상 기반 정렬에서의 강력한 성능 시연
- 모델 정렬 및 데이터 효율성을 위한 합성 데이터 생성의 효능 시연
- 재현성과 커뮤니티 활용 촉진을 위한 상세한 학습 데이터, 파이프라인, 코드 제공
제안 방법
- 9조 토큰 규모의 멀티스트림 프리트레이닝(영어, 다국어, 코드 데이터 포함)
- RoPE, SentencePiece, 그룹드 쿼리 어텐션을 갖춘 디코더 전용 트랜스포머 아키텍처, 바이어스 항 없음
- 두 단계 정렬: 지도 미세조정(SFT) → 선호도 미세조정(DPO 및 RPO)
- 정렬을 위한 합성 데이터의 광범위한 사용(98% 초과) 및 합성 데이터 생성 파이프라인과 HelpSteer2 보상 데이터
- 생성기 품질과 모델 능력을 지속적으로 향상시키기 위한 반복적 약강-강강 정렬
- 정렬 및 데이터 필터링을 안내하는 고품질 보상 모델로 Nemotron-4-340B-Reward의 출시
실험 결과
연구 질문
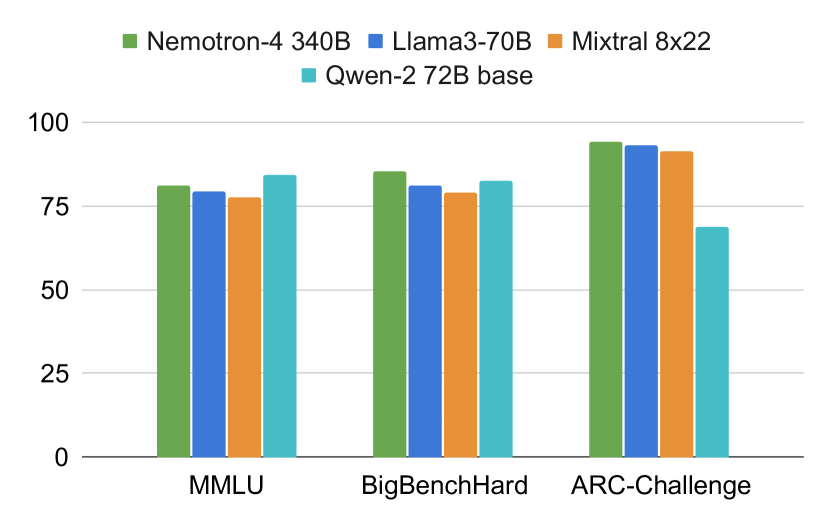
- RQ1Nemotron-4-340B-Base가 일반 오픈 액세스 기준과 표준 추론 및 벤치마크 작업에서 어떻게 비교되는가?
- RQ2대형 언어 모델의 정렬에서 합성 데이터 생성의 효과는 인간 주석 데이터만 사용할 때와 비교하여 어떠한가?
- RQ3보상 모델링과 인간 피드백(RLHF)이 지시 수행과 안전성에 어떤 영향을 미치는가?
- RQ4약강-강강 정렬이 전통적 단일 패스 정렬보다 데이터 품질과 모델 성능을 향상시킬 수 있는가?
- RQ5이중 단계 SFT, 특히 코드모델 중심의 SFT 후 일반 SFT가 다운스트림 작업에 미치는 영향은 무엇인가?
주요 결과
| 크기 | ARC-c | Winogrande | Hellaswag | MMLU | BBH | HumanEval | |
|---|---|---|---|---|---|---|---|
| Mistral 8x22B | 91.30 | 84.70 | 88.50 | 77.75 | 78.90 | 45.10 | |
| Llama-3 70B | 93.00 | 85.30 | ∗ | 88.00 | 79.50 | 81.30 | ∗ |
| Qwen-2 72B | 68.90 | 85.10 | 87.60 | 84.20 | 82.40 | 64.60 | |
| Nemotron-4-340B-Base 340B | 94.28 | 89.50 | 90.53 | 81.10 | 85.44 | 57.32 |
- Nemotron-4-340B-Base가 제시된 오픈 액세스 기반 중에서 상식 추론 과제 및 BBH에서 가장 높은 정확도를 달성했다.
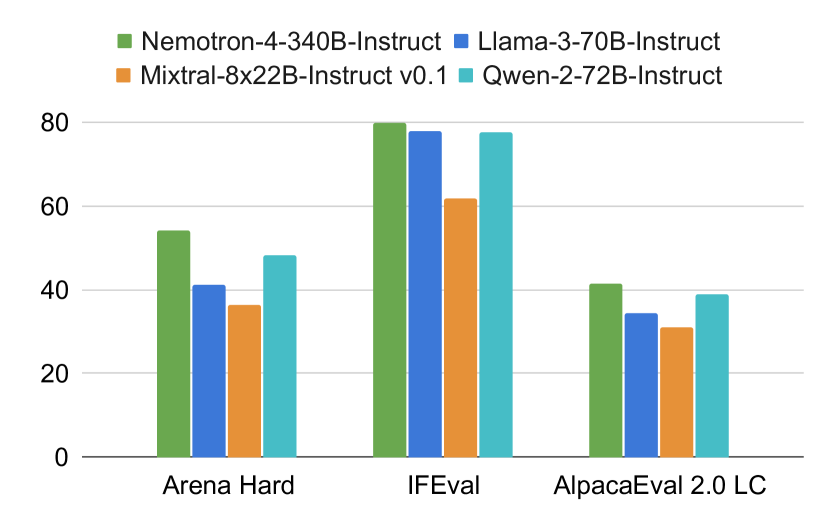
- Nemotron-4-340B-Instruct가 지시 수행 및 채팅 기능에서 해당하는 Instruct 모델을 능가했다.
- Nemotron-4-340B-Reward가 RewardBench에서 최고 정확도를 달성했고 출판 시점에 여러 독점 모델을 능가했다.
- 정렬 데이터의 98% 이상이 합성 데이터로 생성되어 모델 정렬에 대한 합성 데이터 생성의 효과를 입증했다.
- 저자는 오픈 연구 및 재현성을 지원하기 위해 합성 데이터 파이프라인, 생성 프롬프트, 보상 모델을 공개한다.
- 기본 모델은 9.4B 임베딩 매개변수와 331.6B 비임베딩 매개변수로 구성되며, 9T 토큰을 96층 트랜스포머를 통해 학습했다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.