[논문 리뷰] Non-Determinism of "Deterministic" LLM Settings
이 논문은 고정된 입력과 결정론적 하이퍼-파라미터에도 대형 언어 모델이 비결정적 상태를 유지하는 방식을 분석하고, 여러 실행 및 작업에 걸쳐 원시 출력과 파싱된 답변의 가변성을 보여줍니다.
LLM (large language model) practitioners commonly notice that outputs can vary for the same inputs under settings expected to be deterministic. Yet the questions of how pervasive this is, and with what impact on results, have not to our knowledge been systematically investigated. We investigate non-determinism in five LLMs configured to be deterministic when applied to eight common tasks in across 10 runs, in both zero-shot and few-shot settings. We see accuracy variations up to 15% across naturally occurring runs with a gap of best possible performance to worst possible performance up to 70%. In fact, none of the LLMs consistently delivers repeatable accuracy across all tasks, much less identical output strings. Sharing preliminary results with insiders has revealed that non-determinism perhaps essential to the efficient use of compute resources via co-mingled data in input buffers so this issue is not going away anytime soon. To better quantify our observations, we introduce metrics focused on quantifying determinism, TARr@N for the total agreement rate at N runs over raw output, and TARa@N for total agreement rate of parsed-out answers. Our code and data are publicly available at https://github.com/breckbaldwin/llm-stability.
연구 동기 및 목표
- LLM 응답이 동일한 실행에서 얼마나 많은 변 variation이 존재하는지 정량화합니다.
- 최종 파싱된 답변의 안정성과 원시 모델 출력의 안정성을 평가합니다.
- 안정성, 정확도, 입력 길이 및 출력 길이 간의 상관관계를 조사합니다.
- LLM 애플리케이션의 벤치마킹, 배치, 파싱 파이프라인에 대한 통찰을 제공합니다.
제안 방법
- 조합-촉발(Hint) 없이 Few-shot 프롬PT를 여러 작업 및 모델에서 사용합니다.
- temperature를 0으로, top-p를 1로 설정하고, 고정 시드 및 설정당 5개의 동일한 실행을 수행합니다.
- GPT-3.5 Turbo, GPT-4o, Llama-3-70B-Instruct, Llama-3-8B-Instruct, Mixtral-8x7B-Instruct를 사용하여 BBH 및 MMLU 벤치마크 작업을 평가합니다.
- 최소/중간/최대 정확도, 정확도 분포, 파싱 및 원시 출력에 대한 총 일치율(TAR) 등의 지표로 안정성을 측정합니다.
- Spearman 순위상관관계로 상관관계를 분석하고 정규성 검정으로 비정규 분포를 평가합니다
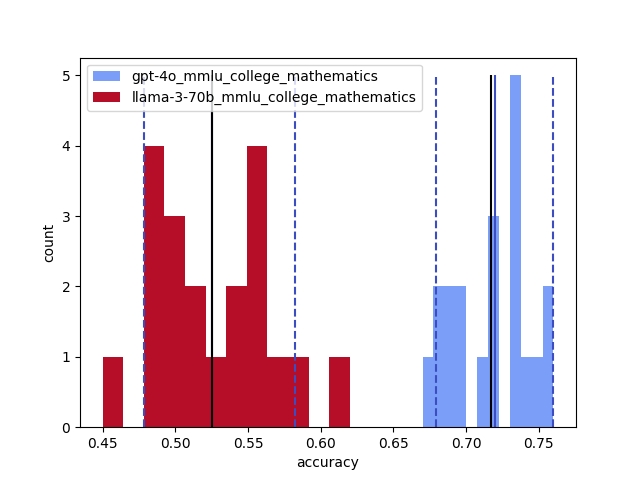
실험 결과
연구 질문
- RQ1동일한 입력과 설정으로 반복 실행했을 때 LLM 최종 성능의 변동 범위는 어느 정도인가?
- RQ2실행 간 원시 출력과 파싱된 답변이 어떻게 달라지며, 이것이 안정성에 어떤 영향을 미치는가?
- RQ3안정성과 정확도가 상관관계가 있는가, 입력 길이/출력 길이가 안정성에 어떤 영향을 주는가?
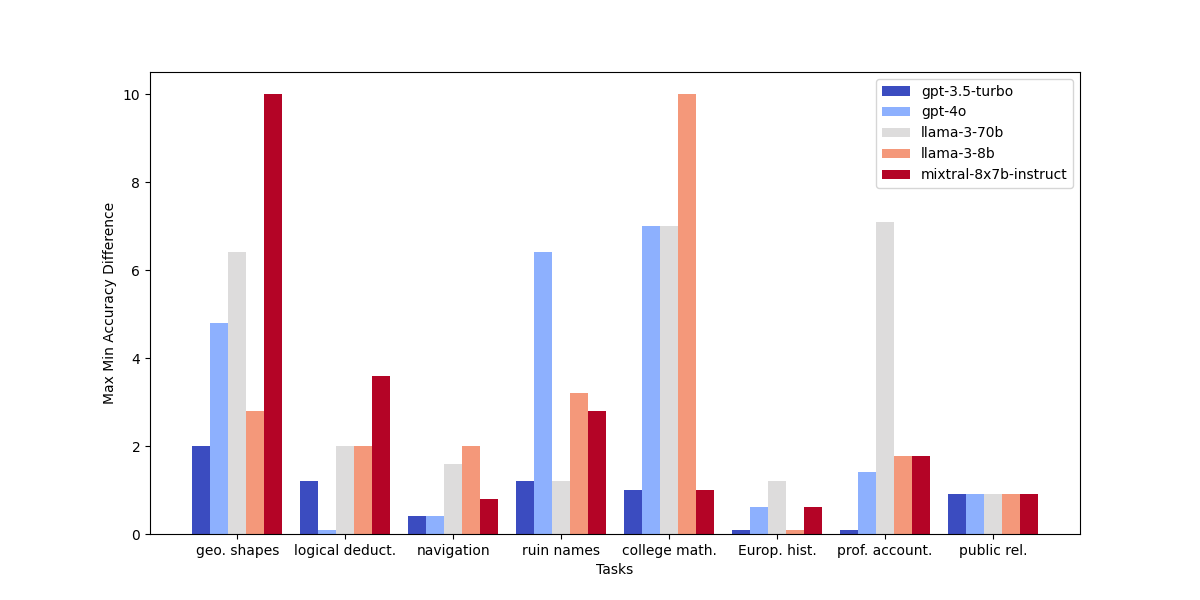
- RQ4안정성은 작업 및 모델 유형에 따라 달라지는가?
주요 결과
- 모델은 결정론적 설정에도 불구하고 원시 출력 단계에서 거의 결정적이지 않다.
- 파싱된(TARa) 안정성은 원시(TARr) 안정성보다 높지만 모든 모델/작업에서 100%는 아니다.
- 안정성과 정확도는 작업에 따라 달라지며, 대학 수학은 특히 불안정하고 유럽사 역사는 비교적으로 안정적이다.
- 출력 길이가 TARa와 TARr 모두와 음의 상관을 보여 더 긴 출력이 안정성을 감소시키는 경향이 있다.
- 정확도와 TARa는 양의 상관관계가 있지만, TARr은 정확도와 뚜렷한 상관관계를 보이지 않는다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.