[논문 리뷰] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
NV-Embed은 잠재 주의 풀링 계층을 사용하고, 대조 학습 during 양방향 주의, 그리고 공개 데이터를 활용한 두 단계 지시-미세조정 프로세스를 통해 디코더-전용 LLM을 다재다능한 임베딩 모델로 학습시켜, MTEB 및 BEIR 벤치마크에서 최고의 성과를 달성한다.
Decoder-only LLM-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce NV-Embed, incorporating architectural designs, training procedures, and curated datasets to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility. For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last token embedding from LLMs. To enhance representation learning, we remove the causal attention mask of LLMs during contrastive training. For training algorithm, we introduce a two-stage contrastive instruction-tuning method. It first applies contrastive training with instructions on retrieval datasets, utilizing in-batch negatives and curated hard negative examples. At stage-2, it blends various non-retrieval into instruction tuning, which not only enhances non-retrieval task accuracy but also improves retrieval performance. For training data, we utilize the hard-negative mining, synthetic data generation and existing public available datasets to boost the performance of embedding model. By combining these techniques, our NV-Embed-v1 and NV-Embed-v2 models obtained the No.1 position on the MTEB leaderboard (as of May 24 and August 30, 2024, respectively) across 56 tasks, demonstrating the sustained effectiveness of the proposed methods over time. It also achieved the highest scores in the Long Doc section and the second-highest scores in the QA section of the AIR Benchmark, which covers a range of out-of-domain information retrieval topics beyond those in MTEB. We further provide the analysis of model compression techniques for generalist embedding models.
연구 동기 및 목표
- 검색 및 비검색 작업을 위한 디코더-전용 LLM으로 일반 목적 텍스트 임베딩을 발전시키다.
- 풀링 및 표현 학습을 개선하기 위한 아키텍처 혁신을 도입하다.
- 공개 데이터만을 사용한 두 단계 지시-미세조정 학습 체계를 개발하다.
- MTEB 및 BEIR 벤치마크에서 최첨단 성능을 입증하다.
- 임베딩 모델의 단순성과 재현성을 유지하다.
제안 방법
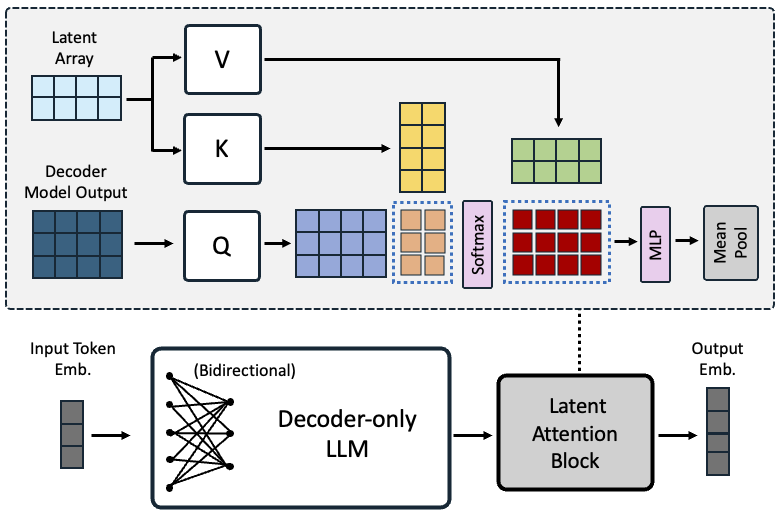
- 시퀀스 임베딩을 풀링하기 위한 잠재 주의 계층을 제안하고, 평균 풀링(mean pooling)이나 EOS 토큰 풀링을 대체하다.
- 대조 학습 중에 인과적 주의 마스크를 제거하여 양방향 표현 학습을 가능하게 하다.
- 두 단계 대조 지시-미세조정으로 학습: 1단계는 in-batch negatives와 hard negatives를 사용하는 검색 데이터세트를 활용하고; 2단계는 in-batch negatives 없이 비검색 데이터세트를 혼합한다.
- 훈련에 대해 공개적으로 이용 가능한 데이터만 사용하고, 독점적 합성 데이터는 피한다.
- 기반 모델은 Mistral-7B; LoRA로 엔드투엔드 학습하며, 최대 시퀀스 길이 512토큰, 배치 크기 128(1개 양성 + 7개 하드 네거티브).
- 전체 MTEB 벤치마크(56개 작업)와 BEIR 부분집합(15개 검색 작업)을 평가하고 선두 임베딩 모델과 비교한다.
실험 결과
연구 질문
- RQ1적절한 풀링 메커니즘과 훈련 전략으로 학습될 때 디코더-전용 LLM이 일반 목적 임베딩 작업에서 양방향 임베딩 모델을 능가할 수 있는가?
- RQ2인과적 주의 마스크를 제거하고 잠재 주의 풀링 계층을 사용하면 검색 및 비검색 작업에 대한 임베딩 품질이 향상되는가?
- RQ3in-batch negative를 사용하면서 먼저 검색에 집중하는 두 단계 지시-미세조정 체계가, 그다음 비검색 데이터를 in-batch negative 없이 혼합할 때 어떤 이점을 얻는가?
- RQ4공개적으로 이용 가능한 데이터만으로 학습해도 독점적 합성 데이터 없이 MTEB/BEIR에서 최첨단 점수를 달성할 수 있는가?
주요 결과
- NV-Embed은 56개 작업에서 사상 최고 MTEB 점수 69.32를 달성한다.
- 15개의 검색 작업에서 BEIR 검색 점수 59.36으로 최고치를 달성한다.
- 대조 학습 중 양방향 주의는 이 설정에서 일관되게 인과적 주의보다 우수하다.
- 잠재 주의 풀링은 평균 풀링 및 EOS 기반 풀링에 비해 검색, 분류, STS 작업의 성능을 향상시킨다.
- 두 단계 지시-미세조정(검색 우선, in-batch negatives 포함, 그런 다음 검색/비검색 혼합)은 검색 및 비검색 작업 성능을 모두 향상시킨다.
- 모든 결과는 공개적으로 이용 가능한 데이터를 사용해 얻었으며, NV-Embed은 Mistral 7B에서 처음부터 학습되었다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.